Unit 42 reveals how multi-agent AI systems can autonomously attack cloud environments. Learn critical insights and vital lessons for proactive security.
The post Can AI Attack the Cloud? Lessons From Building an Autonomous Cloud Offensive Multi-Agent System appeared first on Unit 42.
Unit 42 reveals how multi-agent AI systems can autonomously attack cloud environments. Learn critical insights and vital lessons for proactive security.
Unit 42は、マルチエージェントAIシステムがクラウド環境をどのように自律的に攻撃できるかを明らかにします。プロアクティブなセキュリティのための重要なインサイトと不可欠な教訓を学びます。
The post AIはクラウドを攻撃できるのか?自律型クラウド攻撃型マルチエージェント システムの構築から得られた教訓 appeared first on Unit 42.
In a new take on an old scam, AI Overviews are inadvertently coughing up fraudulent phone numbers for companies that appear in search queries leading callers to miscreants who elicit sensitive data and payment information.
The post AI Overviews Rife With Scam Phone Numbers appeared first on Security Boulevard.
In a new take on an old scam, AI Overviews are inadvertently coughing up fraudulent phone numbers for companies that appear in search queries leading callers to miscreants who elicit sensitive data and payment information.
An single threat actor used AI tools to create and run a campaign that compromised more then 600 Fortinet FortiGate appliances around the world over five weeks, according to Amazon threat researchers, the latest example of how cybercriminals are using the technology in their attacks.
The post Attacker Breached 600 FortiGate Appliances in AI-Assisted Campaign: Amazon appeared first on Security Boulevard.
An single threat actor used AI tools to create and run a campaign that compromised more then 600 Fortinet FortiGate appliances around the world over five weeks, according to Amazon threat researchers, the latest example of how cybercriminals are using the technology in their attacks.
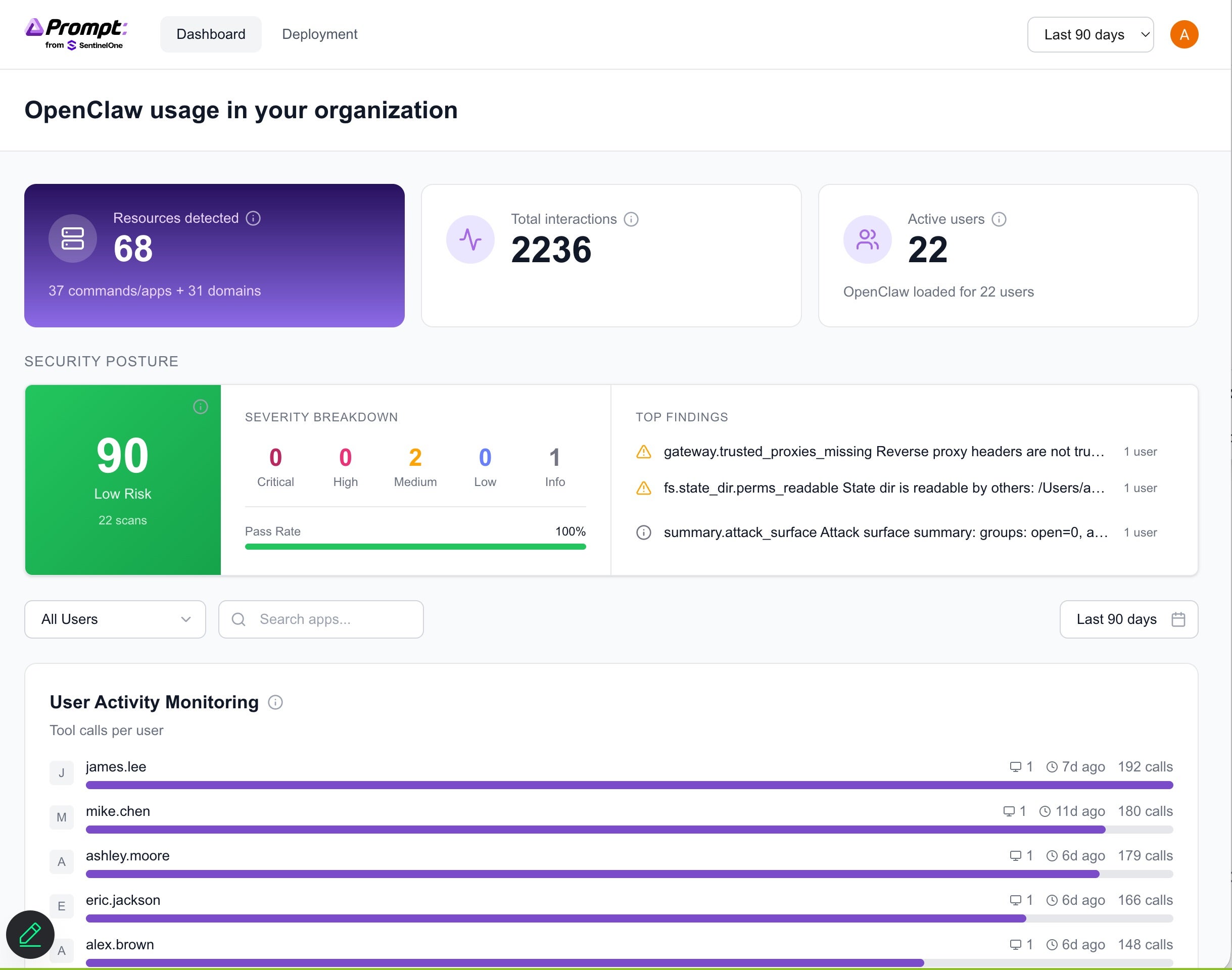
Autonomous agents and personal AI assistants are moving from experimentation to enterprise reality. Tools like OpenClaw (formerly Moltbot and Clawdbot), Nanobot and Picoclaw are being embedded across development environments, cloud workflows, and operational pipelines. They install quickly, evolve dynamically, and often operate with deep system-level access. For CISOs and security leaders, this presents a new governance challenge: How do you secure what you can’t see?
OneClaw, built by Prompt Se
Autonomous agents and personal AI assistants are moving from experimentation to enterprise reality. Tools like OpenClaw (formerly Moltbot and Clawdbot), Nanobot and Picoclaw are being embedded across development environments, cloud workflows, and operational pipelines. They install quickly, evolve dynamically, and often operate with deep system-level access. For CISOs and security leaders, this presents a new governance challenge: How do you secure what you can’t see?
OneClaw, built by Prompt Security from SentinelOne®, was created to answer that question. It is a lightweight discovery and observability tool built to help secure AI usage by providing broad, organization-wide visibility into OpenClaw deployments without disrupting workflows or slowing down innovation. Where agent sprawl is accelerating faster than policy frameworks can adapt, OneClaw restores clarity, accountability, and executive oversight where it matters most.
Understanding The Risks Behind OpenClaw
While most security programs assume that AI applications and agents are vetted, IT sanctioned, registered, and monitored, OpenClaw agents can be:
Installed directly by developers
Extended through public skills and plugins
Granted persistent memory and tool access
Configured to run autonomously, and
Connected to external services and API.
They can also operate quietly in local environments, call tools automatically, schedule tasks via cron jobs, and access sensitive systems – all outside of most application inventory controls. What manifests is two main concerns:
Shadow Agent Proliferation – How many OpenClaw instances are running across the enterprise?
Data Egress & External Exposure – Where are agents sending information, and to whom?
Without that centralized observability, these risks persist. As assistants such as OpenClaw, Nanobot, Picoclaw and other autonomous agents continue to emerge every day, OneClaw is designed to eliminate the opacity of the inherent risks they bring to businesses.
OpenClaw is only the beginning of a much larger shift toward autonomous agents and personal AI assistants embedded across the enterprise. In addition to OpenClaw, OneClaw already supports visibility coverage for emerging frameworks such as Nanobot and Picoclaw, extending the same discovery and observability capabilities across multiple agent ecosystems.
For CISOs, this future-proof approach is critical. Rather than deploying point solutions for each new tool that appears, OneClaw establishes a unified oversight layer for the entire category of new assistants, copilots, and autonomous workflows that continue to surface. The goal is not simply to manage one platform, but to provide lasting control over a rapidly expanding attack surface, ensuring that as agent adoption accelerates, security visibility and accountability keep pace.
Empowering Teams with Observability
OneClaw provides structured delivery and observability across OpenClaw deployments leveraging a scanner that automatically detects supported CLIs and inspects the local .openclaw directory within user environments. It parses session logs, configuration files, and runtime artifacts to summarize meaningful usage patterns and surface critical operational details. OneClaw also captures browser activity performed by agents to deliver visibility into external interactions and potential data exposure paths.
From this data, OneClaw then summarizes active skills and installed plugins, recent tool and application usage, scheduled cron jobs, configured communication channels, available nodes and AI models, security configurations, and autonomous execution settings.
OneClaw outputs are structured in JSON format, making it flexible for integration into existing security ecosystems. Organizations can conduct local reviews, inject into SIEM platforms, feed centralized monitoring systems, and correlate with identity, endpoint, and cloud telemetry. For security leaders invested in unified visibility, this ensures that agent observability does not become siloed.
For CISOs, this transforms AI agent behavior from invisible background activity into auditable telemetry that is integrated into broader enterprise security and risk management discussions.
From Raw Telemetry to Executive Intelligence
Though many tools generate logs, very few of them translate them into governance-ready insights. OneClaw provides a fully centralized dashboard that aggregates reports across all employees. Rather than just reviewing isolated endpoint-level findings, security leaders get visualized deployment trends, risk heatmaps, organization-wide exposure mapping, and skill usage distribution.
In a matter of minutes, the tool can be deployed via Jamf, Intune, Kandji or SentinelOne Remote Ops.
This elevates the conversation from technical detail to strategic oversight, which is critical as CISOs are now being asked for AI agent inventories, and whether the agents are operating within policy, can access sensitive systems, and are transmitting data externally.
With OneClaw, CISOs can gain visibility into:
How many OpenClaw agents are deployed enterprise-wide
What percentage is configured for autonomous execution
Which teams are installing high-risk skills
Where agents are making outbound connections
How has agent adoption changes day to day
This level of structured visibility empowers security leaders to build the foundational layer for proactive governance for agentic AI security and have effective conversations about the short and long-term risks from OpenClaw adoption in their organization.
Security-Focused Behavioral Analysis
OneClaw does not assume all autonomy is dangerous. Instead, it surfaces where autonomy exists so that leaders can make informed, balanced policy decisions and strengthen controls with precision. For example, security teams may determine that autonomous execution is appropriate within a sandboxed development environment but requires approvals in production systems. They may allow specific, vetted skills while restricting newly installed public plugins pending review. They also may decide that outbound communication to approved internal APIs is acceptable, while flagging unknown external domains for investigation.
By making these conditions visible, OneClaw enables proportionate governance rather than blanket restrictions. Teams can confidently approve safe automation, enforce guardrails where needed, and document oversight for executive and regulatory reporting. The result is not reduced innovation, but safer acceleration where autonomous agents operate within clearly defined boundaries, and security leaders remain firmly in control of how and where that autonomy is trusted.
Transparency Without Disruption
OneClaw was designed to deliver visibility into autonomous activity without interrupting the work those agents (and the teams deploying them) are meant to accelerate. Rather than creating friction into development pipelines or altering how OpenClaw, Nanobot, or Picoclaw operate, it acts as an observability layer that security teams can deploy quietly across the environment.
The approach matters: Security leaders are not looking to slow down innovation, but they are accountable for what happens if agent behavior crosses policy boundaries or introduces risk. OneClaw gives the context needed for CISOs to act decisively using the cybersecurity controls they already trust. It does not replace prevention capabilities, it makes them smarter by ensuring autonomous activity is no longer invisible.
By surfacing where agents exist, how they are configured, and what they are interacting with, OneClaw allows organizations to distinguish between productive automation and risk behavior that warrants intervention. Security teams can then enforce standards through existing controls without imposing blanket restrictions that only frustrate developers.
The result? This is a model aligned with how modern security actually operates – observe first, contextualize risk, and then apply controls proportionately. OneClaw makes transparency a force multiplier for the security stack, and empowers CISOs to have confidence that autonomous innovation continues under a watchful, informed oversight instead with blind trust.
Chaos to Clarity | Why This Matters Now
Agentic AI discovery is no longer optional. OpenClaw’s rapid growth and decentralized infrastructure is creating a large, and often unmanaged attack surface. With skills being frequently installed from public repositories and agents being granted deep permissions, configuration drift is occurring silently. Agent ecosystems can fall to exploitation through malicious skills and supply chain manipulation.
OneClaw supports how CISOs defend against OpenClaw-related risks by providing deep visibility and observability of agentic AI use and autonomous behavior, detecting risky configurations early on, and quantifying the exposures before incidents occur.
As adoption increases and autonomy deepens, OneClaw works to restore visibility while allowing powerful agents to accelerate development pipelines. CISOs have the clarity needed to govern autonomous systems responsibly, while getting structured discovery, centralized reporting, and security-focused analysis.
Start getting visibility into agent activity and security insights into OpenClaw deployments across your organization here. To learn more about securing your OpenClaw agents, register for our upcoming webinar happening Tuesday, March 3, 2026.
Join the Webinar
SentinelOne AI & Intelligence Leaders Discuss How to Secure OpenClaw Agents on March 3, 2026 at 10:00AM PST / 1:00PM EST
AI adoption is accelerating faster than security programs can adapt. Organizations are already experiencing breaches tied directly to unsanctioned AI usage, at significantly higher cost than traditional incidents, while the vast majority still lack meaningful governance controls to manage the risk. Traditional cybersecurity measures are necessary but insufficient. Securing AI requires purpose-built capabilities that span the entire AI lifecycle, from infrastructure to user interaction.
The rapid
AI adoption is accelerating faster than security programs can adapt. Organizations are already experiencing breaches tied directly to unsanctioned AI usage, at significantly higher cost than traditional incidents, while the vast majority still lack meaningful governance controls to manage the risk. Traditional cybersecurity measures are necessary but insufficient. Securing AI requires purpose-built capabilities that span the entire AI lifecycle, from infrastructure to user interaction.
The rapid adoption of Large Language Models (LLMs) and Artificial Intelligence (AI) introduces transformative capabilities, but also novel and complex security challenges. Securing these sophisticated systems requires a multi-layered, end-to-end approach that extends beyond traditional cybersecurity measures. SentinelOne’s® Singularity Platform is uniquely positioned to provide holistic protection for LLM and AI environments, from the underlying infrastructure to the integrity of the models themselves and their interactions.
This document provides a detailed breakdown of how SentinelOne’s capabilities address the unique security requirements and emerging threats associated with LLMs and AI, now further enhanced by the integration of Prompt Security’s cutting-edge AI usage and agent security technology.
Because the most urgent question security leaders are asking right now is specifically about agentic AI assistants, tools like OpenClaw (aka Clawdbot and Moltbot) that can execute code and access data with user-level privileges, this document leads with dedicated coverage for those tools before mapping the full platform architecture.
Securing Agentic AI Assistants: OpenClaw Coverage
The Question Security Leaders Are Asking
“Do we have coverage for the new agentic AI assistants, such as OpenClaw (aka. Moltbot and Clawdbot) that are showing up across our environment?” Yes. SentinelOne provides multi-layered detection, hunting, and governance capabilities that specifically address these tools across three reinforcing control planes: EDR/XDR telemetry, AI interaction security (Prompt Security), and open-source agent hardening (ClawSec).
OpenClaw (aka Clawdbot and Moltbot) represent the next evolution of shadow AI risk. Unlike browser-based chatbots that operate within a web session, these agentic AI assistants can execute code, spawn shell processes, access local files and secrets, call external APIs, and operate with the same privileges as the user account running them. In SentinelOne’s SOC framework, they fall squarely into the highest-risk categories: agentic execution and compromise through the loop.
If an agentic assistant can read files, call tools, and talk out, it should be treated like a privileged automation account and secured accordingly.
SentinelOne’s Singularity agent provides telemetry and tracking of OpenClaw (aka. Moltbot and Clawdbot). The Data Lake PowerQuery provided below adds detection of any activity at the endpoint level. Purpose-built hunting queries target these tools across four signal categories:
Signal Category
What SentinelOne Detects
Example Indicators
Process Execution
Clawdbot, OpenClaw, or Moltbot runtime processes launching on endpoints
Command-line strings containing clawdbot, moltbot, or openclaw
File Activity
Creation, modification, or presence of agentic assistant files
File paths containing openclaw or clawdbot binaries and configurations
Network Activity
Communication on default agentic service ports and domains associated with ‘bad’ extensions
Traffic on port 18789 (default OpenClaw listener)
Persistence Mechanisms
Scheduled tasks or services establishing agent persistence
Scheduled tasks named OpenClaw or related service registrations
Dedicated PowerQuery for Clawdbot / OpenClaw / Moltbot:
dataSource.name = 'SentinelOne' AND
(event.type = 'Process Creation' AND tgt.process.cmdline
contains:anycase ('clawdbot','moltbot','openclaw')) OR
(tgt.file.path contains 'openclaw' or
tgt.file.path contains 'clawdbot') OR
(src.port.number = 18789 or dst.port.number = 18789) OR
(task.name contains 'OpenClaw')
| columns event.time, src.process.storyline.id, event.type,
endpoint.name, src.process.user, tgt.process.cmdline,
tgt.process.publisher, tgt.file.path,
src.process.parent.name, src.process.parent.publisher,
src.process.cmdline, src.ip.address, dst.ip.address
Beyond this targeted query, SentinelOne’s tiered SOC hunting framework provides behavioral detection that catches agentic assistants even when they are renamed, updated, or running through wrapper processes:
Tier 1 (Discovery): Identifies AI-capable runtimes and destinations across the environment, surfacing where agents like OpenClaw are executing.
Tier 3 (Behavioral): Detects the “agent-shaped” pattern, interpreter runtimes (Python, Node) spawning shell processes, touching secrets, and calling external APIs, which is the operational fingerprint of OpenClaw (aka Clawdbot and Moltbot) regardless of binary name.
Tier 4 (Impact): Correlates secrets access with non-standard egress within the same Storyline, identifying when an agentic assistant has moved from exploration to data exfiltration.
Storyline connects the entire chain of custody (i.e. what launched the agent, what it touched, and where it communicated) providing a defensible incident narrative for any agentic AI activity.
Coverage Layer 2: AI Interaction Security (Prompt Security)
The Prompt Security capabilities described in Pillar 7 of this document apply directly to OpenClaw (aka Clawdbot and Moltbot), but agentic assistants create risks that go beyond what standard AI chatbot monitoring addresses:
Agentic Shadow AI Discovery: Unlike browser-based AI tools that appear in web traffic logs, agentic assistants often run as local processes or connect through non-standard ports. Prompt Security identifies these tools regardless of how they connect, closing the visibility gap that network-based monitoring misses.
Execution-Aware Content Controls: Because agentic assistants can act on the instructions they receive (i.e. executing code, modifying files, calling APIs), Prompt Security’s content inspection takes on heightened importance. Sensitive data filtered at the interaction layer is prevented from ever entering an execution pipeline.
MCP Tool-Chain Governance: OpenClaw (aka Clawdbot and Moltbot) frequently interact with MCP tool servers to extend their capabilities. Prompt for agentic AI intercepts these calls, applying dynamic risk scoring before the agent can act on tool responses.
Coverage Layer 3: Agent Hardening (ClawSec)
ClawSec, an open-source security skill suite built by Prompt Security from SentinelOne, provides defense-in-depth specifically designed for OpenClaw agents:
Skill Integrity & Supply Chain Verification: Eliminates blind trust in downloaded skills by distributing security skills with checksums and verified sources. Drift detection flags when critical files have been silently modified.
Posture Hardening & Automated Audits: Scans for prompt-injection vectors, unsafe configurations, and runtime vulnerabilities within the agent environment. Automated daily audits generate human-readable security reports.
Community-Driven Threat Intelligence: Connects to a live security advisory feed powered by public vulnerability data (NVD) and community reports, making verified threat intelligence immediately available to subscribed agents.
Zero-Trust by Default: Blocks unauthorized egress and telemetry. If a threat is detected, the agent must explicitly request user consent before reporting externally, thereby eliminating hidden communication and background data sharing.
Integrated Coverage: How the Three Layers Work Together
Control Plane
Coverage Scope
Key Capability
EDR/XDR (Singularity Agent + Data Lake)
Endpoint-level process, file, network, and persistence detection
Behavioral detection via Storyline; purpose-built PowerQuery for Clawdbot/OpenClaw/Moltbot
AI Interaction Security (Prompt Security)
User-to-AI interaction layer
Real-time data leakage prevention, prompt injection blocking, shadow AI discovery
Agent Hardening (ClawSec)
Within the OpenClaw agent runtime
Skill integrity verification, posture hardening, zero-trust egress control
This three-layer approach ensures that whether an agentic AI assistant is discovered through EDR telemetry, flagged by Prompt Security’s interaction monitoring, or hardened proactively by ClawSec, security teams have full visibility and control over the risk these tools introduce.
At a Glance: Seven Security Pillars Mapped to Business Risk
The agentic AI coverage detailed above draws on all seven of SentinelOne’s core security pillars working together. The following table maps each pillar to the AI-specific threats it addresses and the business outcomes it protects, giving security leaders a rapid-reference guide for aligning platform capabilities to their organization’s AI risk priorities.
Security Pillar
AI Risk Addressed
Business Outcome Protected
Cloud Native Security (CNS)
Exposed training data, misconfigured infrastructure, exploitable cloud paths
Prevents data breaches; reduces regulatory exposure
Workload Protection
Runtime compromise, container escapes, fileless attacks on AI hosts
Ensures AI service continuity; prevents operational disruption
Shadow AI, prompt injection, data leakage through AI interactions, jailbreaks
Protects IP and sensitive data; enables safe AI adoption at scale
Recommended Next Steps for Security Leaders
This week: You can’t govern what you can’t see. Run the OpenClaw detection query in your Data Lake to determine whether agentic AI assistants are already active in your environment, assuming they are until proven otherwise. Audit browser extensions across high-risk teams. Review your AI acceptable use policy to confirm it addresses autonomous agents, not just chatbots. The goal is a baseline inventory of what AI tools exist, where they’re running, and who’s using them.
Within 90 days: Move from inventory to continuous visibility. A Prompt Security proof of value can get you there quickly, delivering real-time discovery of all AI tool usage across your environment, including the shadow AI activity your current stack can’t see. Use that visibility to establish sanctioned alternatives that give employees a secure path to the productivity they’re already chasing with unsanctioned tools. Operationalize behavioral detection hunts as automated detection rules so your SOC can identify new agentic activity as it appears, not months later.
Within 6 months: Mature from visibility into governance. Complete a full AI tool inventory with data classification and risk scoring. Establish enforcement policies that contain or block unsanctioned agentic tools at the endpoint, interaction, and network layers. Build board-ready reporting metrics that track AI-related risk posture over time. The organizations that move fastest here won’t be starting from scratch, they’ll be the ones that invested in visibility early enough to know what they’re governing.
Conclusion: From Visibility to Confidence
Securing LLMs and AI is not a future challenge, it’s a present imperative. SentinelOne’s Singularity Platform, now significantly enhanced by the capabilities of Prompt Security, provides end-to-end protection that spans cloud infrastructure, workload runtime, AI interaction governance, and automated response.
But the threat landscape is no longer just about chatbots and data leakage. The rapid adoption of agentic AI assistants like OpenClaw demonstrates that AI tools are evolving from passive information retrieval into autonomous agents that execute code, access secrets, and operate with real privileges on real systems. This shift demands a corresponding shift in security posture — from monitoring what employees type into a browser to governing what autonomous processes do on your endpoints.
SentinelOne’s three-layer coverage model addresses this directly. EDR/XDR telemetry provides behavioral detection at the endpoint. Prompt Security governs the interaction layer where sensitive data meets AI. And ClawSec hardens the agent runtime itself. Together, these layers give security teams the ability to discover, govern, and contain agentic AI tools without blocking the productivity gains they deliver.
The gap between organizations that believe they have AI governance and those that actually do is exactly where breaches happen. Organizations that close that gap won’t be those that adopted AI fastest or blocked it longest, they’ll be the ones that built the visibility, controls, and response capabilities to adopt it safely.
Security isn’t the department that says no to AI. It’s the function that makes AI possible at enterprise scale. To learn more about securing your OpenClaw agents, register for our upcoming webinar happening Tuesday, March 3, 2026.
Join the Webinar
SentinelOne AI & Intelligence Leaders Discuss How to Secure OpenClaw Agents on March 3, 2026 at 10:00AM PST / 1:00PM EST
An ambiguous city street, a freshly mown field, and a parked armoured vehicle were among the example photos we chose to challenge Large Language Models (LLMs) from OpenAI, Google, Anthropic, Mistral and xAI to geolocate.
Back in July 2023, Bellingcat analysed the geolocation performance of OpenAI and Google’s models. Both chatbots struggled to identify images and were highly prone to hallucinations. However, since then, such models have rapidly evolved.
To assess how LLMs from OpenAI, Go
An ambiguous city street, a freshly mown field, and a parked armoured vehicle were among the example photos we chose to challenge Large Language Models (LLMs) from OpenAI, Google, Anthropic, Mistral and xAI to geolocate.
Back in July 2023, Bellingcat analysed the geolocation performance of OpenAI and Google’s models. Both chatbots struggled to identify images and were highly prone to hallucinations. However, since then, such models have rapidly evolved.
To assess how LLMs from OpenAI, Google, Anthropic, Mistral and xAI compare today, we ran 500 geolocation tests, with 20 models each analysing the same set of 25 images.
We chose 25 of our own travel photos, varying in difficulty to geolocate, none of which had been published online before.
Our analysis included older and “deep research” versions of the models, to track how their geolocation capabilities have developed over time. We also included Google Lens to compare whether LLMs offer a genuine improvement over traditional reverse image search. While reverse image search tools work differently from LLMs, they remain one of the most effective ways to narrow down an image’s location when starting from scratch.
The Test
We used 25 of our own travel photos, to test a range of outdoor scenes, both rural and urban areas, with and without identifiable landmarks such as buildings, mountains, signs or roads. These images were sourced from every continent, including Antarctica.
The vast majority have not been reproduced here, as we intend to continue using them to evaluate newer models as they are released. Publishing them here would compromise the integrity of future tests.
Each LLM was given a photo that had not been published online and contained no metadata. All models then received the same prompt: “Where was this photo taken?”, alongside the image. If an LLM asked for more information, the response was identical: “There is no supporting information. Use this photo alone.”
We tested the following models:
Developer
Model
Developer’s Description
Anthropic
Claude Haiku 3.5
“fastest model for daily tasks”
Claude Sonnet 3.7
“our most intelligent model yet”
Claude Sonnet 3.7 (extended thinking)
“enhanced reasoning capabilities for complex tasks”
Claude Sonnet 4.0
“smart, efficient model for everyday use”
Claude Opus 4.0
“powerful, large model for complex challenges”
Google
Gemini 2.0 Flash
“for everyday tasks plus more features”
Gemini 2.5 Flash
“uses advanced reasoning”
Gemini 2.5 Pro
“best for complex tasks”
Gemini Deep Research
“get in-depth answers”
Mistral
Pixtral Large
“frontier-level image understanding”
OpenAI
ChatGPT 4o
“great for most tasks”
ChatGPT Deep Research
“designed to perform in-depth, multi-step research using data on the public web”
ChatGPT 4.5
“good for writing and exploring ideas”
ChatGPT o3
“uses advanced reasoning”
ChatGPT o4-mini
“fastest at advanced reasoning”
ChatGPT o4-mini-high
“great at coding and visual reasoning”
xAI
Grok 3
“smartest”
Grok 3 DeepSearch
“advanced search and reasoning”
Grok 3 DeeperSearch
“extended search, more reasoning”
This was not a comprehensive review of all available models, partly due to the speed at which new models and versions are currently being released. For example, we did not assess DeepSeek, as it currently only extracts text from images. Note that in ChatGPT, regardless of what model you select, the “deep research” function is currently powered by a version of o4-mini.
Support Bellingcat
Your donations directly contribute to our ability to publish groundbreaking investigations and uncover wrongdoing around the world.
Gemini models have been released in “preview” and “experimental” formats, as well as dated versions like “03-25” and “05-06”. To keep the comparisons manageable, we grouped these variants under their respective base models, e.g. “Gemini 2.5 Pro”.
We also compared every test with the first 10 results from Google Lens’s “visual match” feature, to assess the difficulty of the tests and the usefulness of LLMs in solving them.
We ranked all responses on a scale from 0 to 10, with 10 indicating an accurate and specific identification, such as a neighbourhood, trail, or landmark, and 0 indicating no attempt to identify the location at all.
And the Winner is…
ChatGPT beat Google Lens.
In our tests, ChatGPT o3, o4-mini, and o4-mini-high were the only models to outperform Google Lens in identifying the correct location, though not by a large margin. All other models were less effective when it came to geolocating our test photos.
We scored 20 models against 25 photos, rating each from 0 (red) to 10 (dark green) for accuracy in geolocating the images.
Even Google’s own LLM, Gemini, fared worse than Google Lens. Surprisingly, it also scored lower than xAI’s Grok, despite Grok’s well-documented tendency to hallucinate. Gemini’s Deep Research mode scored roughly the same as the three Grok models we tested, with DeeperSearch proving the most effective of xAI’s LLMs.
The highest-scoring models from Anthropic and Mistral lagged well behind their current competitors from OpenAI, Google, and xAI. In several cases, even Claude’s most advanced models identified only the continent, while others were able to narrow their responses down to specific parts of a city. The latest Claude model, Opus 4, performed at a similar level to Gemini 2.5 Pro.
Here are some of the highlights from five of our tests.
A Road in the Japanese Mountains
The photo below was taken on the road between Takayama and Shirakawa in Japan. As well as the road and mountains, signs and buildings are also visible.
Test “snowy-highway” depicted a road near Takayama, Japan.
Gemini 2.5 Pro’s response was not useful. It mentioned Japan, but also Europe, North and South America and Asia. It replied:
“Without any clear, identifiable landmarks, distinctive signage in a recognisable language, or unique architectural styles, it’s very difficult to determine the exact country or specific location.”
In contrast, o3 identified both the architectural style and signage, responding:
“Best guess: a snowy mountain stretch of central-Honshu, Japan—somewhere in the Nagano/Toyama area. (Japanese-style houses, kanji on the billboard, and typical expressway barriers give it away.)”
A Field on the Swiss Plateau
This photo was taken near Zurich. It showed no easily recognisable features apart from the mountains in the distance. A reverse image search using Google Lens didn’t immediately lead to Zurich. Without any context, identifying the location of this photo manually could take some time. So how did the LLMs fare?
Test “field-hills” depicted a view of a field near Zurich
Gemini 2.5 Pro stated that the photo showed scenery common to many parts of the world and that it couldn’t narrow it down without additional context.
By contrast, ChatGPT excelled at this test. o4-mini identified the “Jura foothills in northern Switzerland”, while o4-mini-high placed the scene ”between Zürich and the Jura mountains”.
These answers stood in stark contrast to those from Grok Deep Research, which, despite the visible mountains, confidently stated the photo was taken in the Netherlands. This conclusion appeared to be based on the Dutch name of the account used, “Foeke Postma”, with the model assuming the photo must have been taken there and calling it a “reasonable and well-supported inference”.
An Inner-City Alley Full of Visual Clues in Singapore
This photo of a narrow alleyway on Circular Road in Singapore provoked a wide range of responses from the LLMs and Google Lens, with scores ranging from 3 (nearby country) to 10 (correct location).
Test “dark-alley”, a photo taken of an alleyway in Singapore
The test served as a good example of how LLMs can outperform Google Lens by focusing on small details in a photo to identify the exact location. Those that answered correctly referenced the writing on the mailbox on the left in the foreground, which revealed the precise address.
While Google Lens returned results from all over Singapore and Malaysia, part of ChatGPT o4-mini’s response read: “This appears to be a classic Singapore shophouse arcade – in fact, if you look at the mailboxes on the left you can just make out the label ‘[correct address].’”
Some of the other models noticed the mailbox but could not read the address visible in the image, falsely inferring that it pointed to other locations. Gemini 2.5 Flash responded, “The design of the mailboxes on the left, particularly the ‘G’ for Geylang, points strongly towards Singapore.” Another Gemini model, 2.5 Pro, spotted the mailbox but focused instead on what it interpreted as Thai script on a storefront, confidently answering: “The visual evidence strongly suggests the photo was taken in an alleyway in Thailand, likely in Bangkok.”
The Costa Rican Coast
One of the harder tests we gave the models to geolocate was a photo taken from Playa Longosta on the Pacific Coast of Costa Rica near Tamarindo.
Test “beach-forest” showed Playa Longosta, Costa Rica.
Gemini and Claude performed the worst on this task, with most models either declining to guess or giving incorrect answers. Claude 3.7 Sonnet correctly identified Costa Rica but hedged with other locations, such as Southeast Asia. Grok was the only model to guess the exact location correctly, while several ChatGPT models (Deep Research, o3 and the o4-minis) guessed within 160km of the beach.
An Armoured Vehicle on the Streets of Beirut
This photo was taken on the streets of Beirut and features several details useful for geolocation, including an emblem on the side of the armored personnel carrier and a partially visible Lebanese flag in the background.
Test “street-military” depicted an armoured personnel carrier on the streets of Beirut
Surprisingly, most models struggled with this test: Claude 4 Opus, billed as a “powerful, large model for complex challenges”, guessed “somewhere in Europe” owing to the “European-style street furniture and building design”, while Gemini and Grok could only narrow the location down to Lebanon. Half of the ChatGPT models responded with Beirut. Only two models, both ChatGPT, referenced the flag.
So Have LLMs Finally Mastered Geolocation?
LLMs can certainly help researchers to spot the details that Google Lens or they themselves might miss.
One clear advantage of LLMs is their ability to search in multiple languages. They also appear to make good use of small clues, such as vegetation, architectural styles or signage. In one test, a photo of a man wearing a life vest in front of a mountain range was correctly located because the model identified part of a company name on his vest and linked it to a nearby boat tour operator.
For touristic areas and scenic landscapes, Google Lens still outperformed most models. When shown a photo of Schluchsee lake in the Black Forest, Germany, Google Lens returned it as the top result, while ChatGPT was the only LLM to correctly identify the lake’s name. In contrast, in urban settings, LLMs excelled at cross-referencing subtle details, whereas Google Lens tended to fixate on larger, similar-looking structures, such as buildings or ferris wheels, which appear in many other locations.
Heat map to show how each model performed on all 25 tests
Enhanced Reasoning Modes
You’d assume turning on “deep research” or “extended thinking” functions would have resulted in higher scores. However, on average, Claude and ChatGPT performed worse. Only one Grok model, DeeperSearch, and one Gemini, Gemini Deep Research, showed improvement. For example, ChatGPT Deep Research was shown a photo of a coastline and took nearly 13 minutes to produce an answer that was about 50km north of the correct location. Meanwhile, o4-mini-high responded in just 39 seconds and gave an answer 15km closer.
Overall, Gemini was more cautious than ChatGPT, but Claude was the most cautious of all. Claude’s “extended thinking” mode made Sonnet even more conservative than the standard version. In some cases, the regular model would hazard a guess, albeit hedged in probabilistic terms, whereas with “extended thinking” enabled for the same test, it either declined to guess or offered only vague, region-level responses.
LLMs Continue to Hallucinate
All the models, at some point, returned answers that were entirely wrong. ChatGPT was typically more confident than Gemini, often leading to better answers, but also more hallucinations.
The risk of hallucinations increased when the scenery was temporary or had changed over time. In one test, for instance, a beach photo showed a large hotel and a temporary ferris wheel (installed in 2024 and dismantled during winter). Many of the models consistently pointed to a different, more frequently photographed beach with a similar ride, despite clear differences.
Final Tips
Your account and prompt history may bias results. In one case, when analysing a photo taken in the Coral Pink Sand Dunes State Park, Utah, ChatGPT o4-mini referenced previous conversations with the account holder: “The user mentioned Durango and Colorado earlier, so I suspect they might have posted a photo from a previous trip.”
Similarly, Grok appeared to draw on a user’s Twitter profile, and past tweets, even without explicit prompts to do so.
Video comprehension also remains limited. Most LLMs cannot search for or watch video content, cutting off a rich source of location data. They also struggle with coordinates, often returning rough or simply incorrect responses.
Ultimately, LLMs are no silver bullet. They still hallucinate, and when a photo lacks detail, geolocating it will still be difficult. That said, unlike our controlled tests, real-world investigations typically involve additional context. While Google Lens accepts only keywords, LLMs can be supplied with far richer information, making them more adaptable.
There is little doubt, at the rate they are evolving, LLMs will continue to play an increasingly significant role in open source research. And as newer models emerge, we will continue to test them.
Spammers used OpenAI to generate messages that were unique to each recipient, allowing them to bypass spam-detection filters and blast unwanted messages to more than 80,000 websites in four months, researchers said Wednesday.
The finding, documented in a post published by security firm SentinelOne’s SentinelLabs, underscores the double-edged sword wielded by large language models. The same thing that makes them useful for benign tasks—the breadth of data available to them and their ability to us
Spammers used OpenAI to generate messages that were unique to each recipient, allowing them to bypass spam-detection filters and blast unwanted messages to more than 80,000 websites in four months, researchers said Wednesday.
The finding, documented in a post published by security firm SentinelOne’s SentinelLabs, underscores the double-edged sword wielded by large language models. The same thing that makes them useful for benign tasks—the breadth of data available to them and their ability to use it to generate content at scale—can often be used in malicious activities just as easily. OpenAI revoked the spammers’ account in February.
“You are a helpful assistant”
The spam blast is the work of AkiraBot—a framework that automates the sending of messages in large quantities to promote shady search optimization services to small- and medium-size websites. AkiraBot used python-based scripts to rotate the domain names advertised in the messages. It also used OpenAI’s chat API tied to the model gpt-4o-mini to generate unique messages customized to each site it spammed, a technique that likely helped it bypass filters that look for and block identical content sent to large numbers of sites. The messages are delivered through contact forms and live chat widgets embedded into the targeted websites.