Bypassing MTE with CVE-2025-0072
Memory Tagging Extension (MTE) is an advanced memory safety feature that is intended to make memory corruption vulnerabilities almost impossible to exploit. But no mitigation is ever completely airtight—especially in kernel code that manipulates memory at a low level.
Last year, I wrote about CVE-2023-6241, a vulnerability in ARM’s Mali GPU driver, which enabled an untrusted Android app to bypass MTE and gain arbitrary kernel code execution. In this post, I’ll walk through CVE-2025-0072: a newly patched vulnerability that I also found in ARM’s Mali GPU driver. Like the previous one, it enables a malicious Android app to bypass MTE and gain arbitrary kernel code execution.
I reported the issue to Arm on December 12, 2024. It was fixed in Mali driver version r54p0, released publicly on May 2, 2025, and included in Android’s May 2025 security update. The vulnerability affects devices with newer Arm Mali GPUs that use the Command Stream Frontend (CSF) architecture, such as Google’s Pixel 7, 8, and 9 series. I developed and tested the exploit on a Pixel 8 with kernel MTE enabled, and I believe it should work on the 7 and 9 as well with minor modifications.
What follows is a deep dive into how CSF queues work, the steps I used to exploit this bug, and how it ultimately bypasses MTE protections to achieve kernel code execution.
How CSF queues work—and how they become dangerous
Arm Mali GPUs with the CSF feature communicate with userland applications through command queues, implemented in the driver as kbase_queue objects. The queues are created by using the KBASE_IOCTL_CS_QUEUE_REGISTER ioctl. To use the kbase_queue that is created, it first has to be bound to a kbase_queue_group, which is created with the KBASE_IOCTL_CS_QUEUE_GROUP_CREATE ioctl. A kbase_queue can be bound to a kbase_queue_group with the KBASE_IOCTL_CS_QUEUE_BIND ioctl. When binding a kbase_queue to a kbase_queue_group, a handle is created from get_user_pages_mmap_handle and returned to the user application.
int kbase_csf_queue_bind(struct kbase_context *kctx, union kbase_ioctl_cs_queue_bind *bind)
{
...
group = find_queue_group(kctx, bind->in.group_handle);
queue = find_queue(kctx, bind->in.buffer_gpu_addr);
…
ret = get_user_pages_mmap_handle(kctx, queue);
if (ret)
goto out;
bind->out.mmap_handle = queue->handle;
group->bound_queues[bind->in.csi_index] = queue;
queue->group = group;
queue->group_priority = group->priority;
queue->csi_index = (s8)bind->in.csi_index;
queue->bind_state = KBASE_CSF_QUEUE_BIND_IN_PROGRESS;
out:
rt_mutex_unlock(&kctx->csf.lock);
return ret;
}In addition, mutual references are stored between the kbase_queue_group and the queue. Note that when the call finishes, queue->bind_state is set to KBASE_CSF_QUEUE_BIND_IN_PROGRESS, indicating that the binding is not completed. To complete the binding, the user application must call mmap with the handle returned from the ioctl as the file offset. This mmap call is handled by kbase_csf_cpu_mmap_user_io_pages, which allocates GPU memory via kbase_csf_alloc_command_stream_user_pages and maps it to user space.
int kbase_csf_alloc_command_stream_user_pages(struct kbase_context *kctx, struct kbase_queue *queue)
{
struct kbase_device *kbdev = kctx->kbdev;
int ret;
lockdep_assert_held(&kctx->csf.lock);
ret = kbase_mem_pool_alloc_pages(&kctx->mem_pools.small[KBASE_MEM_GROUP_CSF_IO],
KBASEP_NUM_CS_USER_IO_PAGES, queue->phys, false, //<------ 1.
kctx->task);
...
ret = kernel_map_user_io_pages(kctx, queue);
...
get_queue(queue);
queue->bind_state = KBASE_CSF_QUEUE_BOUND;
mutex_unlock(&kbdev->csf.reg_lock);
return 0;
...
}In 1. in the above snippet, kbase_mem_pool_alloc_pages is called to allocate memory pages from the GPU memory pool, whose addresses are then stored in the queue->phys field. These pages are then mapped to user space and the bind_state of the queue is set to KBASE_CSF_QUEUE_BOUND. These pages are only freed when the mmapped area is unmapped from the user space. In that case, kbase_csf_free_command_stream_user_pages is called to free the pages via kbase_mem_pool_free_pages.
void kbase_csf_free_command_stream_user_pages(struct kbase_context *kctx, struct kbase_queue *queue)
{
kernel_unmap_user_io_pages(kctx, queue);
kbase_mem_pool_free_pages(&kctx->mem_pools.small[KBASE_MEM_GROUP_CSF_IO],
KBASEP_NUM_CS_USER_IO_PAGES, queue->phys, true, false);
...
}This frees the pages stored in queue->phys, and because this only happens when the pages are unmapped from user space, it prevents the pages from being accessed after they are freed.
An exploit idea
The interesting part begins when we ask: what happens if we can modify queue->phys after mapping them into user space. For example, if I can trigger kbase_csf_alloc_command_user_pages again to overwrite new pages to queue->phys, and map them to user space and then unmap the previously mapped region, kbase_csf_free_command_stream_user_pages will be called to free the pages in queue->phys. However, because queue->phys is now overwritten by the newly allocated pages, I ended up in a situation where I free the new pages while unmapping an old region:
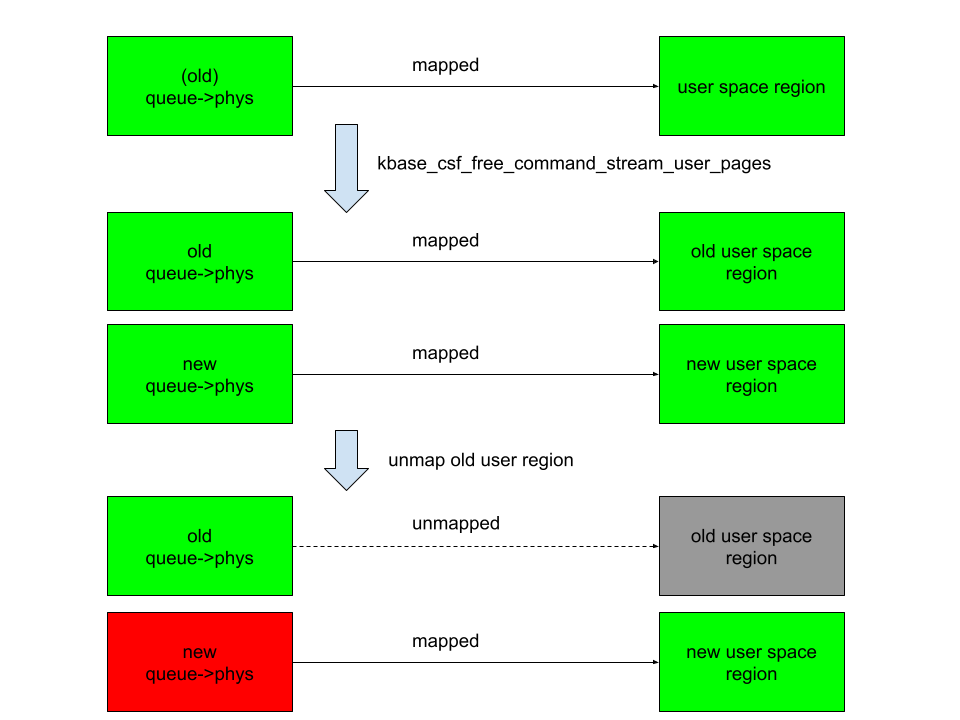
In the above figure, the right columns are mappings in the user space, green rectangles are mapped, while gray ones are unmapped. The left column are backing pages stored in queue->phys. The new queue->phys are pages that are currently stored in queue->phys, while old queue->phys are pages that are stored previously but are replaced by the new ones. Green indicates that the pages are alive, while red indicates that they are freed. After overwriting queue->phys and unmapping the old region, the new queue->phys are freed instead, while still mapped to the new user region. This means that user space will have access to the freed new queue->phys pages. This then gives me a page use-after-free vulnerability.
The vulnerability
So let’s take a look at how to achieve this situation. The first obvious thing to try is to see if I can bind a kbase_queue multiple times using the KBASE_IOCTL_CS_QUEUE_BIND ioctl. This, however, is not possible because the queue->group field is checked before binding:
int kbase_csf_queue_bind(struct kbase_context *kctx, union kbase_ioctl_cs_queue_bind *bind)
{
...
if (queue->group || group->bound_queues[bind->in.csi_index])
goto out;
...
}After a kbase_queue is bound, its queue->group is set to the kbase_queue_group that it binds to, which prevents the kbase_queue from binding again. Moreover, once a kbase_queue is bound, it cannot be unbound via any ioctl. It can be terminated with KBASE_IOCTL_CS_QUEUE_TERMINATE, but that will also delete the kbase_queue. So if rebinding from the queue is not possible, what about trying to unbind from a kbase_queue_group? For example, what happens if a kbase_queue_group gets terminated with the KBASE_IOCTL_CS_QUEUE_GROUP_TERMINATE ioctl? When a kbase_queue_group terminates, as part of the clean up process, it calls kbase_csf_term_descheduled_queue_group to unbind queues that it bound to:
void kbase_csf_term_descheduled_queue_group(struct kbase_queue_group *group)
{
...
for (i = 0; i < max_streams; i++) {
struct kbase_queue *queue = group->bound_queues[i];
/* The group is already being evicted from the scheduler */
if (queue)
unbind_stopped_queue(kctx, queue);
}
...
}This then resets the queue->group field of the kbase_queue that gets unbound:
static void unbind_stopped_queue(struct kbase_context *kctx, struct kbase_queue *queue)
{
...
if (queue->bind_state != KBASE_CSF_QUEUE_UNBOUND) {
...
queue->group->bound_queues[queue->csi_index] = NULL;
queue->group = NULL;
...
queue->bind_state = KBASE_CSF_QUEUE_UNBOUND;
}
}In particular, this now allows the kbase_queue to bind to another kbase_queue_group. This means I can now create a page use-after-free with the following steps:
- Create a
kbase_queueand akbase_queue_group, and then bind thekbase_queueto thekbase_queue_group. - Create GPU memory pages for the user io pages in the
kbase_queueand map them to user space using ammapcall. These pages are then stored in thequeue->physfield of thekbase_queue. - Terminate the
kbase_queue_group, which also unbinds thekbase_queue. - Create another
kbase_queue_groupand bind thekbase_queueto this new group. - Create new GPU memory pages for the user io pages in this
kbase_queueand map them to user space. These pages now overwrite the existing pages inqueue->phys. - Unmap the user space memory that was mapped in step 2. This then frees the pages in
queue->physand removes the user space mapping created in step 2. However, the pages that are freed are now the memory pages created and mapped in step 5, which are still mapped to user space.
This, in particular, means that the pages that are freed in step 6 of the above can still be accessed from the user application. By using a technique that I used previously, I can reuse these freed pages as page table global directories (PGD) of the Mali GPU.
To recap, let’s take a look at how the backing pages of a kbase_va_region are allocated. When allocating pages for the backing store of a kbase_va_region, the kbase_mem_pool_alloc_pages function is used:
int kbase_mem_pool_alloc_pages(struct kbase_mem_pool *pool, size_t nr_4k_pages,
struct tagged_addr *pages, bool partial_allowed)
{
...
/* Get pages from this pool */
while (nr_from_pool--) {
p = kbase_mem_pool_remove_locked(pool); //<------- 1.
...
}
...
if (i != nr_4k_pages && pool->next_pool) {
/* Allocate via next pool */
err = kbase_mem_pool_alloc_pages(pool->next_pool, //<----- 2.
nr_4k_pages - i, pages + i, partial_allowed);
...
} else {
/* Get any remaining pages from kernel */
while (i != nr_4k_pages) {
p = kbase_mem_alloc_page(pool); //<------- 3.
...
}
...
}
...
}The input argument kbase_mem_pool is a memory pool managed by the kbase_context object associated with the driver file that is used to allocate the GPU memory. As the comments suggest, the allocation is actually done in tiers. First the pages will be allocated from the current kbase_mem_pool using kbase_mem_pool_remove_locked (1 in the above). If there is not enough capacity in the current kbase_mem_pool to meet the request, then pool->next_pool, is used to allocate the pages (2 in the above). If even pool->next_pool does not have the capacity, then kbase_mem_alloc_page is used to allocate pages directly from the kernel via the buddy allocator (the page allocator in the kernel).
When freeing a page, the same happens in the opposite direction: kbase_mem_pool_free_pages first tries to return the pages to the kbase_mem_pool of the current kbase_context, if the memory pool is full, it’ll try to return the remaining pages to pool->next_pool. If the next pool is also full, then the remaining pages are returned to the kernel by freeing them via the buddy allocator.
As noted in my post “Corrupting memory without memory corruption”, pool->next_pool is a memory pool managed by the Mali driver and shared by all the kbase_context. It is also used for allocating page table global directories (PGD) used by GPU contexts. In particular, this means that by carefully arranging the memory pools, it is possible to cause a freed backing page in a kbase_va_region to be reused as a PGD of a GPU context. (Read the details of how to achieve this.)
Once the freed page is reused as a PGD of a GPU context, the user space mapping can be used to rewrite the PGD from the GPU. This then allows any kernel memory, including kernel code, to be mapped to the GPU, which allows me to rewrite kernel code and hence execute arbitrary kernel code. It also allows me to read and write arbitrary kernel data, so I can easily rewrite credentials of my process to gain root, as well as to disable SELinux.
See the exploit for Pixel 8 with some setup notes.
How does this bypass MTE?
Before wrapping up, let’s look at why this exploit manages to bypass Memory Tagging Extension (MTE)—despite protections that should have made this type of attack impossible.
The Memory Tagging Extension (MTE) is a security feature on newer Arm processors that uses hardware implementations to check for memory corruptions.
The Arm64 architecture uses 64 bit pointers to access memory, while most applications use a much smaller address space (for example, 39, 48, or 52 bits). The highest bits in a 64 bit pointer are actually unused. The main idea of memory tagging is to use these higher bits in an address to store a “tag” that can then be used to check against the other tag stored in the memory block associated with the address.
When a linear overflow happens and a pointer is used to dereference an adjacent memory block, the tag on the pointer is likely to be different from the tag in the adjacent memory block. By checking these tags at dereference time, such discrepancy, and hence the corrupted dereference can be detected. For use-after-free type memory corruptions, as long as the tag in a memory block is cleared every time it is freed and a new tag reassigned when it is allocated, dereferencing an already freed and reclaimed object will also lead to a discrepancy between pointer tag and the tag in memory, which allows use-after-free to be detected.
The memory tagging extension is an instruction set introduced in the v8.5a version of the ARM architecture, which accelerates the process of tagging and checking of memory with the hardware. This makes it feasible to use memory tagging in practical applications. On architectures where hardware accelerated instructions are available, software support in the memory allocator is still needed to invoke the memory tagging instructions. In the linux kernel, the SLUB allocator, used for allocating kernel objects, and the buddy allocator, used for allocating memory pages, have support for memory tagging.
Readers who are interested in more details can, for example, consult this article and the whitepaper released by Arm.
As I mentioned in the introduction, this exploit is capable of bypassing MTE. However, unlike a previous vulnerability that I reported, where a freed memory page is accessed via the GPU, this bug accesses the freed memory page via user space mapping. Since page allocation and dereferencing is protected by MTE, it is perhaps somewhat surprising that this bug manages to bypass MTE. Initially, I thought this was because the memory page that is involved in the vulnerability is managed by kbase_mem_pool, which is a custom memory pool used by the Mali GPU driver. In the exploit, the freed memory page that is reused as the PGD is simply returned to the memory pool managed by kbase_mem_pool, and then allocated again from the memory pool. So the page was never truly freed by the buddy allocator and therefore not protected by MTE. While this is true, I decided to also try freeing the page properly and return it to the buddy allocator. To my surprise, MTE did not trigger even when the page is accessed after it is freed by the buddy allocator. After some experiments and source code reading, it appears that page mappings created by mgm_vmf_insert_pfn_prot in kbase_csf_user_io_pages_vm_fault, which are used for accessing the memory page after it is freed, ultimately uses insert_pfn to create the mapping, which inserts the page frame into the user space page table. I am not totally sure, but it seems that because the page frames are inserted directly into the user space page table, accessing those pages from user space does not require kernel level dereferencing and therefore does not trigger MTE.
Conclusion
In this post I’ve shown how CVE-2025-0072 can be used to gain arbitrary kernel code execution on a Pixel 8 with kernel MTE enabled. Unlike a previous vulnerability that I reported, which bypasses MTE by accessing freed memory from the GPU, this vulnerability accesses freed memory via user space memory mapping inserted by the driver. This shows that MTE can also be bypassed when freed memory pages are accessed via memory mappings in user space, which is a much more common scenario than the previous vulnerability.
The post Bypassing MTE with CVE-2025-0072 appeared first on The GitHub Blog.
