CodeQL zero to hero part 5: Debugging queries
When you’re first getting started with CodeQL, you may find yourself in a situation where a query doesn’t return the results you expect. Debugging these queries can be tricky, because CodeQL is a Prolog-like language with an evaluation model that’s quite different from mainstream languages like Python. This means you can’t “step through” the code, and techniques such as attaching gdb or adding print statements don’t apply. Fortunately, CodeQL offers a variety of built-in features to help you diagnose and resolve issues in your queries.
Below, we’ll dig into these features — from an abstract syntax tree (AST) to partial path graphs — using questions from CodeQL users as examples. And if you ever have questions of your own, you can visit and ask in GitHub Security Lab’s public Slack instance, which is monitored by CodeQL engineers.
Minimal code example
The issue we are going to use was raised by user NgocKhanhC311, and later a similar issue was raised from zhou noel. Both encountered difficulties writing a CodeQL query to detect a vulnerability in projects using the Gradio framework. Since I have personally added Gradio support to CodeQL — and even wrote a blog about the process (CodeQL zero to hero part 4: Gradio framework case study), which includes an introduction to Gradio and its attack surface — I jumped in to answer.
zhou noel wanted to detect variants of an unsafe deserialization vulnerability that was found in browser-use/web-ui v1.6. See the simplified code below.
import pickle
import gradio as gr
def load_config_from_file(config_file):
"""Load settings from a UUID.pkl file."""
try:
with open(config_file.name, 'rb') as f:
settings = pickle.load(f)
return settings
except Exception as e:
return f"Error loading configuration: {str(e)}"
with gr.Blocks(title="Configuration Loader") as demo:
config_file_input = gr.File(label="Load Config File")
load_config_button = gr.Button("Load Existing Config From File", variant="primary")
config_status = gr.Textbox(label="Status")
load_config_button.click(
fn=load_config_from_file,
inputs=[config_file_input],
outputs=[config_status]
)
demo.launch()Using the load_config_button.click event handler (from gr.Button), a user-supplied file config_file_input (of type gr.File) is passed to the load_config_from_file function, which reads the file with open(config_file.name, 'rb'), and loads the file’s contents using pickle.load.
The vulnerability here is more of a “second order” vulnerability. First, an attacker uploads a malicious file, then the application loads it using pickle. In this example, our source is gr.File. When using gr.File, the uploaded file is stored locally, and the path is available in the name attribute config_file.name. Then the app opens the file with open(config_file.name, 'rb') as f: and loads it using pickle pickle.load(f), leading to unsafe deserialization.
What a pickle! 🙂
If you’d like to test the vulnerability, create a new folder with the code, call it example.py, and then run:
python -m venv venv
source venv/bin/activate
pip install gradio
python example.pyThen, follow these steps to create a malicious pickle file to exploit the vulnerability.
The user wrote a CodeQL taint tracking query, which at first glance should find the vulnerability.
/**
* @name Gradio unsafe deserialization
* @description This query tracks data flow from inputs passed to a Gradio's Button component to any sink.
* @kind path-problem
* @problem.severity warning
* @id 5/1
*/
import python
import semmle.python.ApiGraphs
import semmle.python.Concepts
import semmle.python.dataflow.new.RemoteFlowSources
import semmle.python.dataflow.new.TaintTracking
import MyFlow::PathGraph
class GradioButton extends RemoteFlowSource::Range {
GradioButton() {
exists(API::CallNode n |
n = API::moduleImport("gradio").getMember("Button").getReturn()
.getMember("click").getACall() |
this = n.getParameter(0, "fn").getParameter(_).asSource())
}
override string getSourceType() { result = "Gradio untrusted input" }
}
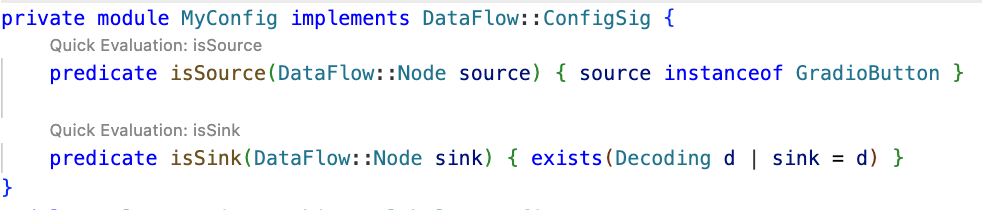
private module MyConfig implements DataFlow::ConfigSig {
predicate isSource(DataFlow::Node source) { source instanceof GradioButton }
predicate isSink(DataFlow::Node sink) { exists(Decoding d | sink = d) }
}
module MyFlow = TaintTracking::Global<MyConfig>;
from MyFlow::PathNode source, MyFlow::PathNode sink
where MyFlow::flowPath(source, sink)
select sink.getNode(), source, sink, "Data Flow from a Gradio source to decoding"The source is set to any parameter passed to function in a gr.Button.click event handler. The sink is set to any sink of type Decoding. In CodeQL for Python, the Decoding type includes unsafe deserialization sinks, such as the first argument to pickle.load.
If you run the query on the database, you won’t get any results.
To figure out most CodeQL query issues, I suggest trying out the following options, which we’ll go through in the next sections of the blog:
- Make a minimal code example and create a CodeQL database of it to reduce the number of results.
- Simplify the query into predicates and classes, making it easier to run the specific parts of the query, and check if they provide the expected results.
- Use quick evaluation on the simplified predicates.
- View the abstract syntax tree of your codebase to see the expected CodeQL type for a given code element, and how to query for it.
- Call the
getAQlClasspredicate to identify what types a given code element is. - Use a partial path graph to see where taint stops propagating.
- Write a taint step to help the taint propagate further.
Creating a CodeQL database
Using our minimal code example, we’ll create a CodeQL database, similarly to how we did it in CodeQL ZtH part 4, and run the following command in the directory that contains only the minimal code example.
codeql database create codeql-zth5 --language=pythonThis command will create a new directory, codeql-zth5, with the CodeQL database. Add it to your CodeQL workspace and then we can get started.
Simplifying the query and quick evaluation
The query is already simplified into predicates and classes, so we can quickly evaluate it using the Quick evaluation button over the predicate name, or by right-clicking on the predicate name and choosing CodeQL: Quick evaluation.
Clicking Quick Evaluation over the isSource and isSink predicate shows a result for each, which means that both source and sink were found correctly. Note, however, that the isSink result highlights the whole pickle.load(f) call, rather than just the first argument to the call. Typically, we prefer to set a sink as an argument to a call, not the call itself.
In this case, the Decoding abstract sinks have a getAnInput predicate, which specifies the argument to a sink call. To differentiate between normal Decoding sinks (for example, json.loads), and the ones that could execute code (such as pickle.load), we can use the mayExecuteInput predicate.
predicate isSink(DataFlow::Node sink) {
exists(Decoding d | d.mayExecuteInput() | sink = d.getAnInput()) }Quick evaluation of the isSink predicate gives us one result.
With this, we verified that the sources and sinks are correctly reported. That means there’s an issue between the source and sink, which CodeQL can’t propagate through.
Abstract Syntax Tree (AST) viewer
We haven’t had issues identifying the source or sink nodes, but if there were an issue with identifying the source or sink nodes, it would be helpful to examine the abstract syntax tree (AST) of the code to determine the type of a particular code element.
After you run Quick Evaluation on isSink, you’ll see the file where CodeQL identified the sink. To see the abstract syntax tree for the file, right-click the code element you’re interested in and select CodeQL: View AST.
The option will display the AST of the file in the CodeQL tab in VS Code, under the AST Viewer section.
Once you know the type of a given code element from the AST, it can be easier to write a query for the code element you’re interested in.
getAQlClass predicate
Another good strategy to figure out the type of a code element you’re interested in is to use getAQlClass predicate. Usually, it’s best to create a separate query, so you don’t clutter your original query.
For example, we could write a query to check the types of a parameter to the function fn passed to gradio.Button.click:
/**
* @name getAQlClass on Gradio Button input source
* @description This query reports on a code element's types.
* @id 5/2
* @severity error
* @kind problem
*/
import python
import semmle.python.ApiGraphs
import semmle.python.Concepts
import semmle.python.dataflow.new.RemoteFlowSources
from DataFlow::Node node
where node = API::moduleImport("gradio").getMember("Button").getReturn()
.getMember("click").getACall().getParameter(0, "fn").getParameter(_).asSource()
select node, node.getAQlClass()Running the query provides five results showing the types of the parameter: FutureTypeTrackingNode, ExprNode, LocalSourceNodeNotModuleVariableNode, ParameterNode, and LocalSourceParameterNode. From the results, the most interesting and useful types for writing queries are the ExprNode and ParameterNode.
Partial path graph: forwards
Now that we’ve identified that there’s an issue with connecting the source to the sink, we should verify where the taint flow stops. We can do that using partial path graphs, which show all the sinks the source flows toward and where those flows stop. This is also why having a minimal code example is so vital — otherwise we’d get a lot of results.
If you do end up working on a large codebase, you should try to limit the source you’re starting with to, for example, a specific file with a condition akin to:
predicate isSource(DataFlow::Node source) { source instanceof GradioButton
and source.getLocation().getFile().getBaseName() = "example.py" }See other ways of providing location information.
Partial graphs come in two forms: forward FlowExplorationFwd, which traces flow from a given source to any sink, and backward/reverse FlowExplorationRev, which traces flow from a given sink back to any source.
We have public templates for partial path graphs in most languages for your queries in CodeQL Community Packs — see the template for Python.
Here’s how we would write a forward partial path graph query for our current issue:
/**
* @name Gradio Button partial path graph
* @description This query tracks data flow from inputs passed to a Gradio's Button component to any sink.
* @kind path-problem
* @problem.severity warning
* @id 5/3
*/
import python
import semmle.python.ApiGraphs
import semmle.python.Concepts
import semmle.python.dataflow.new.RemoteFlowSources
import semmle.python.dataflow.new.TaintTracking
// import MyFlow::PathGraph
import PartialFlow::PartialPathGraph
class GradioButton extends RemoteFlowSource::Range {
GradioButton() {
exists(API::CallNode n |
n = API::moduleImport("gradio").getMember("Button").getReturn()
.getMember("click").getACall() |
this = n.getParameter(0, "fn").getParameter(_).asSource())
}
override string getSourceType() { result = "Gradio untrusted input" }
}
private module MyConfig implements DataFlow::ConfigSig {
predicate isSource(DataFlow::Node source) { source instanceof GradioButton }
predicate isSink(DataFlow::Node sink) { exists(Decoding d | d.mayExecuteInput() | sink = d.getAnInput()) }
}
module MyFlow = TaintTracking::Global<MyConfig>;
int explorationLimit() { result = 10 }
module PartialFlow = MyFlow::FlowExplorationFwd<explorationLimit/0>;
from PartialFlow::PartialPathNode source, PartialFlow::PartialPathNode sink
where PartialFlow::partialFlow(source, sink, _)
select sink.getNode(), source, sink, "Partial Graph $@.", source.getNode(), "user-provided value."What changed:
- We commented out
import MyFlow::PathGraphand insteadimport PartialFlow::PartialPathGraph. - We set
explorationLimit()to10, which controls how deep the analysis goes. This is especially useful in larger codebases with complex flows. - We create a
PartialFlowmodule withFlowExplorationFwd, meaning we are tracing flows from a specified source to any sink. If we want to start from a sink and trace back to any source, we’d useFlowExplorationRevwith small changes in the query itself. See template forFlowExplorationRev. - Finally, we made changes to the from-where-select query to use
PartialFlow::PartialPathNodes, and thePartialFlow::partialFlowpredicate.
Running the query gives us one result, which ends at config_file in the with open(config_file.name, 'rb') as f: line. This means CodeQL didn’t propagate to the name attribute in config_file.name.
The config_name here is an instance of gr.File, which has the name attribute, which stores the path to the uploaded file.
Quite often, if an object is tainted, we can’t tell if all of its attributes are tainted as well. By default, CodeQL would not propagate to an object’s attributes. As such, we need to help taint propagate from an object to its name attribute by writing a taint step.
Taint step
The quickest way, though not the prettiest, would be to write a taint step to propagate from any object to that object’s name attribute. This is naturally not something we’d like to include in production CodeQL queries, since it might lead to false positives. For our use case it’s fine, since we are writing the query for security research.
We add a taint step into a taint tracking configuration by using an isAdditionalFlowStep predicate. This taint step will allow CodeQL to propagate to any read of a name attribute. We specify the two nodes that we want to connect — nodeFrom and nodeTo — and how they should be connected. nodeFrom is a node that accesses name attribute, and nodeTo is the node that represents the attribute read.
predicate isAdditionalFlowStep(DataFlow::Node nodeFrom, DataFlow::Node nodeTo) {
exists(DataFlow::AttrRead attr |
attr.accesses(nodeFrom, "name")
and nodeTo = attr
)
}Let’s make it a separate predicate for easier testing, and plug it into our partial path graph query.
/**
* @name Gradio Button partial path graph
* @description This query tracks data flow from Gradio's Button component to any sink.
* @kind path-problem
* @problem.severity warning
* @id 5/4
*/
import python
import semmle.python.ApiGraphs
import semmle.python.Concepts
import semmle.python.dataflow.new.RemoteFlowSources
import semmle.python.dataflow.new.TaintTracking
// import MyFlow::PathGraph
import PartialFlow::PartialPathGraph
class GradioButton extends RemoteFlowSource::Range {
GradioButton() {
exists(API::CallNode n |
n = API::moduleImport("gradio").getMember("Button").getReturn()
.getMember("click").getACall() |
this = n.getParameter(0, "fn").getParameter(_).asSource())
}
override string getSourceType() { result = "Gradio untrusted input" }
}
predicate nameAttrRead(DataFlow::Node nodeFrom, DataFlow::Node nodeTo) {
// Connects an attribute read of an object's `name` attribute to the object itself
exists(DataFlow::AttrRead attr |
attr.accesses(nodeFrom, "name")
and nodeTo = attr
)
}
private module MyConfig implements DataFlow::ConfigSig {
predicate isSource(DataFlow::Node source) { source instanceof GradioButton }
predicate isSink(DataFlow::Node sink) { exists(Decoding d | d.mayExecuteInput() | sink = d.getAnInput()) }
predicate isAdditionalFlowStep(DataFlow::Node nodeFrom, DataFlow::Node nodeTo) {
nameAttrRead(nodeFrom, nodeTo)
}
}
module MyFlow = TaintTracking::Global<MyConfig>;
int explorationLimit() { result = 10 }
module PartialFlow = MyFlow::FlowExplorationFwd<explorationLimit/0>;
from PartialFlow::PartialPathNode source, PartialFlow::PartialPathNode sink
where PartialFlow::partialFlow(source, sink, _)
select sink.getNode(), source, sink, "Partial Graph $@.", source.getNode(), "user-provided value."Running the query gives us two results. In the second path, we see that the taint propagated to config_file.name, but not further. What happened?
Taint step… again?
The specific piece of code turned out to be a bit of a special case. I mentioned earlier that this vulnerability is essentially a “second order” vulnerability — we first upload a malicious file, then load that locally stored file. Generally in these cases it’s the path to the file that we consider as tainted, and not the contents of the file itself, so CodeQL wouldn’t normally propagate here. In our case, in Gradio, we do control the file that is being loaded.
That’s why we need another taint step to propagate from config_file.name to open(config_file.name, 'rb').
We can write a predicate that would propagate from the argument to open() to the result of open() (and also from the argument to os.open to os.open call since we are at it).
predicate osOpenStep(DataFlow::Node nodeFrom, DataFlow::Node nodeTo) {
// Connects the argument to `open()` to the result of `open()`
// And argument to `os.open()` to the result of `os.open()`
exists(API::CallNode call |
call = API::moduleImport("os").getMember("open").getACall() and
nodeFrom = call.getArg(0) and
nodeTo = call)
or
exists(API::CallNode call |
call = API::builtin("open").getACall() and
nodeFrom = call.getArg(0) and
nodeTo = call)
}Then we can add this second taint step to isAdditionalFlowStep.
predicate isAdditionalFlowStep(DataFlow::Node nodeFrom, DataFlow::Node nodeTo) {
nameAttrRead(nodeFrom, nodeTo)
or
osOpenStep(nodeFrom, nodeTo)
}Let’s add the taint step to a final taint tracking query, and make it a normal taint tracking query again.
/**
* @name Gradio File Input Flow
* @description This query tracks data flow from Gradio's Button component to a Decoding sink.
* @kind path-problem
* @problem.severity warning
* @id 5/5
*/
import python
import semmle.python.ApiGraphs
import semmle.python.Concepts
import semmle.python.dataflow.new.RemoteFlowSources
import semmle.python.dataflow.new.TaintTracking
import MyFlow::PathGraph
class GradioButton extends RemoteFlowSource::Range {
GradioButton() {
exists(API::CallNode n |
n = API::moduleImport("gradio").getMember("Button").getReturn()
.getMember("click").getACall() |
this = n.getParameter(0, "fn").getParameter(_).asSource())
}
override string getSourceType() { result = "Gradio untrusted input" }
}
predicate nameAttrRead(DataFlow::Node nodeFrom, DataFlow::Node nodeTo) {
// Connects an attribute read of an object's `name` attribute to the object itself
exists(DataFlow::AttrRead attr |
attr.accesses(nodeFrom, "name")
and nodeTo = attr
)
}
predicate osOpenStep(DataFlow::Node nodeFrom, DataFlow::Node nodeTo) {
// Connects the argument to `open()` to the result of `open()`
// And argument to `os.open()` to the result of `os.open()`
exists(API::CallNode call |
call = API::moduleImport("os").getMember("open").getACall() and
nodeFrom = call.getArg(0) and
nodeTo = call)
or
exists(API::CallNode call |
call = API::builtin("open").getACall() and
nodeFrom = call.getArg(0) and
nodeTo = call)
}
private module MyConfig implements DataFlow::ConfigSig {
predicate isSource(DataFlow::Node source) { source instanceof GradioButton }
predicate isSink(DataFlow::Node sink) {
exists(Decoding d | d.mayExecuteInput() | sink = d.getAnInput()) }
predicate isAdditionalFlowStep(DataFlow::Node nodeFrom, DataFlow::Node nodeTo) {
nameAttrRead(nodeFrom, nodeTo)
or
osOpenStep(nodeFrom, nodeTo)
}
}
module MyFlow = TaintTracking::Global<MyConfig>;
from MyFlow::PathNode source, MyFlow::PathNode sink
where MyFlow::flowPath(source, sink)
select sink.getNode(), source, sink, "Data Flow from a Gradio source to decoding"Running the query provides one result — the vulnerability we’ve been looking for! 🎉
A prettier taint step
Note that the CodeQL written in this section is very specific to Gradio, and you’re unlikely to encounter similar modeling in other frameworks. What follows is a more advanced version of the previous taint step, which I added for those of you who want to dig deeper into writing a more maintainable solution to this taint step problem. You are unlikely to need to write this kind of granular CodeQL as a security researcher, but if you use CodeQL at work, this section might come in handy.
As we’ve mentioned, the taint step that propagates taint through a name attribute read on any object is a hacky solution. Not every object that propagates taint through name read would cause a vulnerability. We’d like to limit the taint step to only propagate similarly to this case — only for gr.File type.
But we encounter a problem — Gradio sources are modeled as any parameters passed to function in gr.Button.click event handlers, so CodeQL is not aware of what type a given argument passed to a function in gr.Button.click is. For that reason, we can’t easily write a straightforward taint step that would check if the source is of gr.File type before propagating to a name attribute.
We have to “look back” to where the source was instantiated, check its type, and later connect that object to a name attribute read.
Recall our minimal code example.
import pickle
import gradio as gr
def load_config_from_file(config_file):
"""Load settings from a UUID.pkl file."""
try:
with open(config_file.name, 'rb') as f:
settings = pickle.load(f)
return settings
except Exception as e:
return f"Error loading configuration: {str(e)}"
with gr.Blocks(title="Configuration Loader") as demo:
config_file_input = gr.File(label="Load Config File")
load_config_button = gr.Button("Load Existing Config From File", variant="primary")
config_status = gr.Textbox(label="Status")
load_config_button.click(
fn=load_config_from_file,
inputs=[config_file_input],
outputs=[config_status]
)
demo.launch()Taint steps work by creating an edge (a connection) between two specified nodes. In our case, we are looking to connect two sets of nodes, which are on the same path.
First, we want CodeQL to connect the variables passed to inputs (here config_file_input) in e.g. gr.Button.click and connect it to the parameter config_file in the load_config_from_file function. This way it will be able to propagate back to the instantiation, to config_file_input = gr.File(label="Load Config File").
Second, we want CodeQL to propagate from the nodes that we checked are of gr.File type, to the cases where they read the name attribute.
Funnily enough, I’ve already written a taint step, called ListTaintStep that can track back to the instantiations, and even written a section in the previous CodeQL zero to hero about it. We can reuse the implemented logic, and add it to our query. We’ll do it by modifying the nameAttrRead predicate.
predicate nameAttrRead(DataFlow::Node nodeFrom, DataFlow::Node nodeTo) {
// Connects an attribute read of an object's `name` attribute to the object itself
exists(DataFlow::AttrRead attr |
attr.accesses(nodeFrom, "name")
and nodeTo = attr
)
and
exists(API::CallNode node, int i, DataFlow::Node n1, DataFlow::Node n2 |
node = API::moduleImport("gradio").getAMember().getReturn().getAMember().getACall() and
n2 = node.getParameter(0, "fn").getParameter(i).asSource()
and n1.asCfgNode() =
node.getParameter(1, "inputs").asSink().asCfgNode().(ListNode).getElement(i)
and n1.getALocalSource() = API::moduleImport("gradio").getMember("File").getReturn().asSource()
and (DataFlow::localFlow(n2, nodeFrom) or DataFlow::localFlow(nodeTo, n1))
)
}The taint step connects any object to that object’s name read (like before). Then, it looks for the function passed to fn, variables passed to inputs in e.g. gr.Button.click and connects the variables in inputs to the parameters given to the function fn by using an integer i to keep track of position of the variables.
Then, by using:
nodeFrom.getALocalSource()
= API::moduleImport("gradio").getMember("File").getReturn().asSource()We check that the node we are tracking is of gr.File type.
and (DataFlow::localFlow(n2, nodeFrom) or DataFlow::localFlow(nodeTo, n1)At last, we check that there is a local flow (with any number of path steps) between the fn function parameter n2 and an attribute read nodeFrom or that there is a local flow between specifically the name attribute read nodeTo, and a variable passed to gr.Button.click’s inputs.
What we did is essentially two taint steps (we connect, that is create edges between two sets of nodes) connected by local flow, which combines them into one taint step. The reason we are making it into one taint step is because one condition can’t exist without the other. We use localFlow because there can be several steps between the connection we made from variables passed to inputs to the function defined in fn in gr.Button.click and later reading the name attribute on an object. localFlow allows us to connect the two.
It looks complex, but it stems from how directed graphs work.
Full CodeQL query:
/**
* @name Gradio File Input Flow
* @description This query tracks data flow from Gradio's Button component to a Decoding sink.
* @kind path-problem
* @problem.severity warning
* @id 5/6
*/
import python
import semmle.python.dataflow.new.DataFlow
import semmle.python.dataflow.new.TaintTracking
import semmle.python.Concepts
import semmle.python.dataflow.new.RemoteFlowSources
import semmle.python.ApiGraphs
class GradioButton extends RemoteFlowSource::Range {
GradioButton() {
exists(API::CallNode n |
n = API::moduleImport("gradio").getMember("Button").getReturn()
.getMember("click").getACall() |
this = n.getParameter(0, "fn").getParameter(_).asSource())
}
override string getSourceType() { result = "Gradio untrusted input" }
}
predicate nameAttrRead(DataFlow::Node nodeFrom, DataFlow::Node nodeTo) {
// Connects an attribute read of an object's `name` attribute to the object itself
exists(DataFlow::AttrRead attr |
attr.accesses(nodeFrom, "name")
and nodeTo = attr
)
and
exists(API::CallNode node, int i, DataFlow::Node n1, DataFlow::Node n2 |
node = API::moduleImport("gradio").getAMember().getReturn().getAMember().getACall() and
n2 = node.getParameter(0, "fn").getParameter(i).asSource()
and n1.asCfgNode() =
node.getParameter(1, "inputs").asSink().asCfgNode().(ListNode).getElement(i)
and n1.getALocalSource() = API::moduleImport("gradio").getMember("File").getReturn().asSource()
and (DataFlow::localFlow(n2, nodeFrom) or DataFlow::localFlow(nodeTo, n1))
)
}
predicate osOpenStep(DataFlow::Node nodeFrom, DataFlow::Node nodeTo) {
exists(API::CallNode call |
call = API::moduleImport("os").getMember("open").getACall() and
nodeFrom = call.getArg(0) and
nodeTo = call)
or
exists(API::CallNode call |
call = API::builtin("open").getACall() and
nodeFrom = call.getArg(0) and
nodeTo = call)
}
module MyConfig implements DataFlow::ConfigSig {
predicate isSource(DataFlow::Node source) { source instanceof GradioButton }
predicate isSink(DataFlow::Node sink) {
exists(Decoding d | d.mayExecuteInput() | sink = d.getAnInput())
}
predicate isAdditionalFlowStep(DataFlow::Node nodeFrom, DataFlow::Node nodeTo) {
nameAttrRead(nodeFrom, nodeTo)
or
osOpenStep(nodeFrom, nodeTo)
}
}
import MyFlow::PathGraph
module MyFlow = TaintTracking::Global<MyConfig>;
from MyFlow::PathNode source, MyFlow::PathNode sink
where MyFlow::flowPath(source, sink)
select sink.getNode(), source, sink, "Data Flow from a Gradio source to decoding"Running the taint step will return a full path from gr.File to pickle.load(f).
A taint step in this form could be contributed to CodeQL upstream. However, this is a very specific taint step, which makes sense for some vulnerabilities, and not others. For example, it works for an unsafe deserialization vulnerability like described in the article, but not for path injection. That’s because this is a “second order” vulnerability — we control the uploaded file, but not its path (stored in “name”). For path injection vulnerabilities with sinks like open(file.name, ‘r’), this would be a false positive.
Conclusion
Some of the issues we encounter on the GHSL Slack around tracking taint can be a challenge. Cases like these don’t happen often, but when they do, it makes them a good candidate for sharing lessons learned and writing a blog post, like this one.
I hope my story of chasing taint helps you with debugging your queries. If, after trying out the tips in this blog, there are still issues with your query, feel free to ask for help on our public GitHub Security Lab Slack instance or in github/codeql discussions.
The post CodeQL zero to hero part 5: Debugging queries appeared first on The GitHub Blog.



