Gerenciamento de vulnerabilidades de código aberto | Blog oficial da Kaspersky
Como já comentamos em uma postagem anterior, o desenvolvimento de produtos de software modernos é praticamente impossível sem o uso de componentes de código aberto. Mas, nos últimos anos, os riscos associados a isso tornaram-se cada vez mais diversos, complexos e numerosos. Devemos considerar que, primeiro, as vulnerabilidades afetam a infraestrutura e o código de uma empresa mais rapidamente do que são corrigidas; segundo, os dados são incompletos e pouco confiáveis; e, terceiro, malware pode estar escondido em componentes populares. Portanto, não basta simplesmente verificar os números de versão e solicitar que a equipe de TI corrija os problemas. O gerenciamento de vulnerabilidades deve ser expandido para abranger políticas de download de software, proteções para assistentes de IA e todo o pipeline de criação de software.
Um conjunto confiável de componentes de código aberto
A principal característica de uma solução é impedir o uso de código vulnerável e malicioso. As seguintes medidas devem ser implementadas:
- Ter um repositório interno de artefatos. A fonte única de componentes para desenvolvimento interno precisa ser um repositório unificado no qual os componentes são admitidos somente após uma série de verificações.
- Fazer uma triagem rigorosa dos componentes. Isso inclui verificações de versões conhecidas do componente, versões vulneráveis e maliciosas conhecidas, data de publicação, histórico de atividades e reputação do pacote e de seus autores. É obrigatório verificar todo o conteúdo do pacote, incluindo instruções de compilação, casos de teste e outros dados auxiliares. Para filtrar o registro durante a ingestão, use verificadores de código aberto especializados ou uma solução de segurança abrangente de carga de trabalho na nuvem.
- Fixar versões de dependências. Os processos de compilação, as ferramentas de IA e os desenvolvedores não devem usar modelos (como “o mais recente”) ao especificar versões. As compilações do projeto precisam ser baseadas em versões verificadas. Ao mesmo tempo, as dependências com versões fixas devem ser atualizadas com frequência para as versões verificadas mais recentes que mantêm a compatibilidade e não contêm vulnerabilidades conhecidas. Isso reduz significativamente o risco de ataques à cadeia de suprimentos por meio do comprometimento de um pacote conhecido.
Aperfeiçoamento dos dados de vulnerabilidades
Para identificar vulnerabilidades com mais eficácia e priorizá-las de forma adequada, uma organização precisa estabelecer vários processos de TI e segurança:
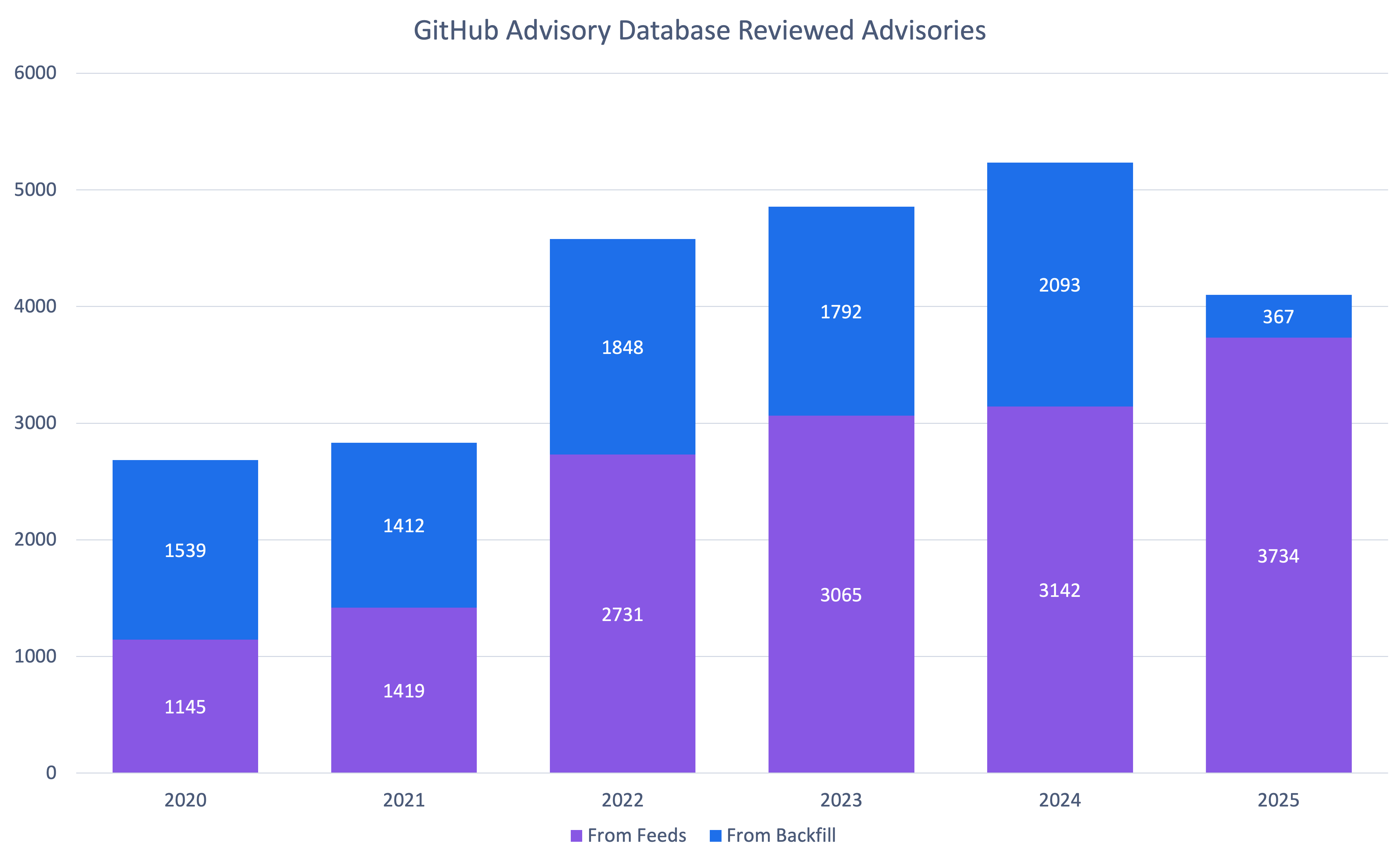
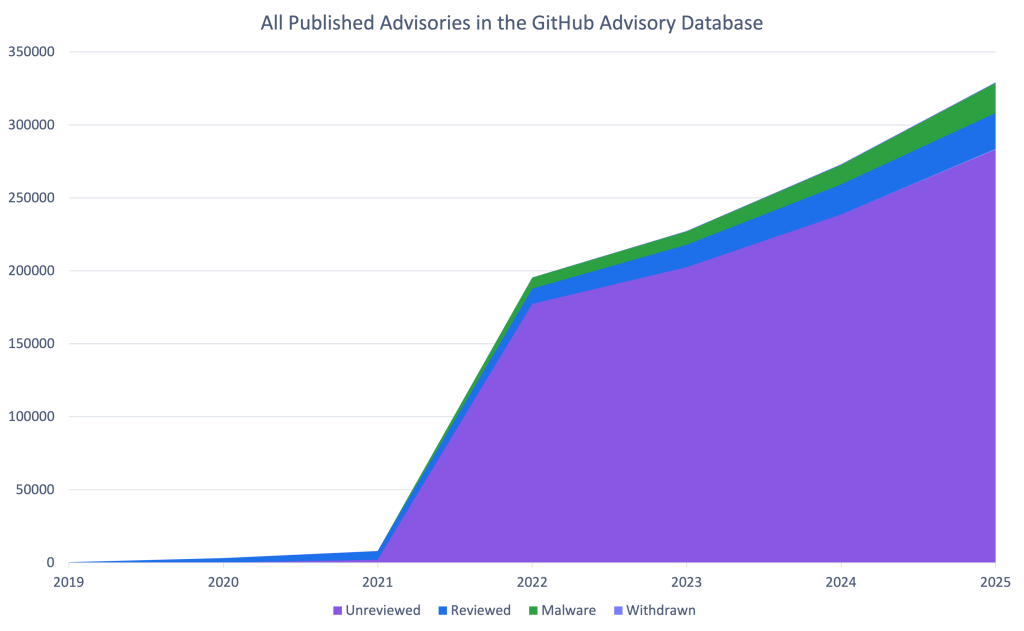
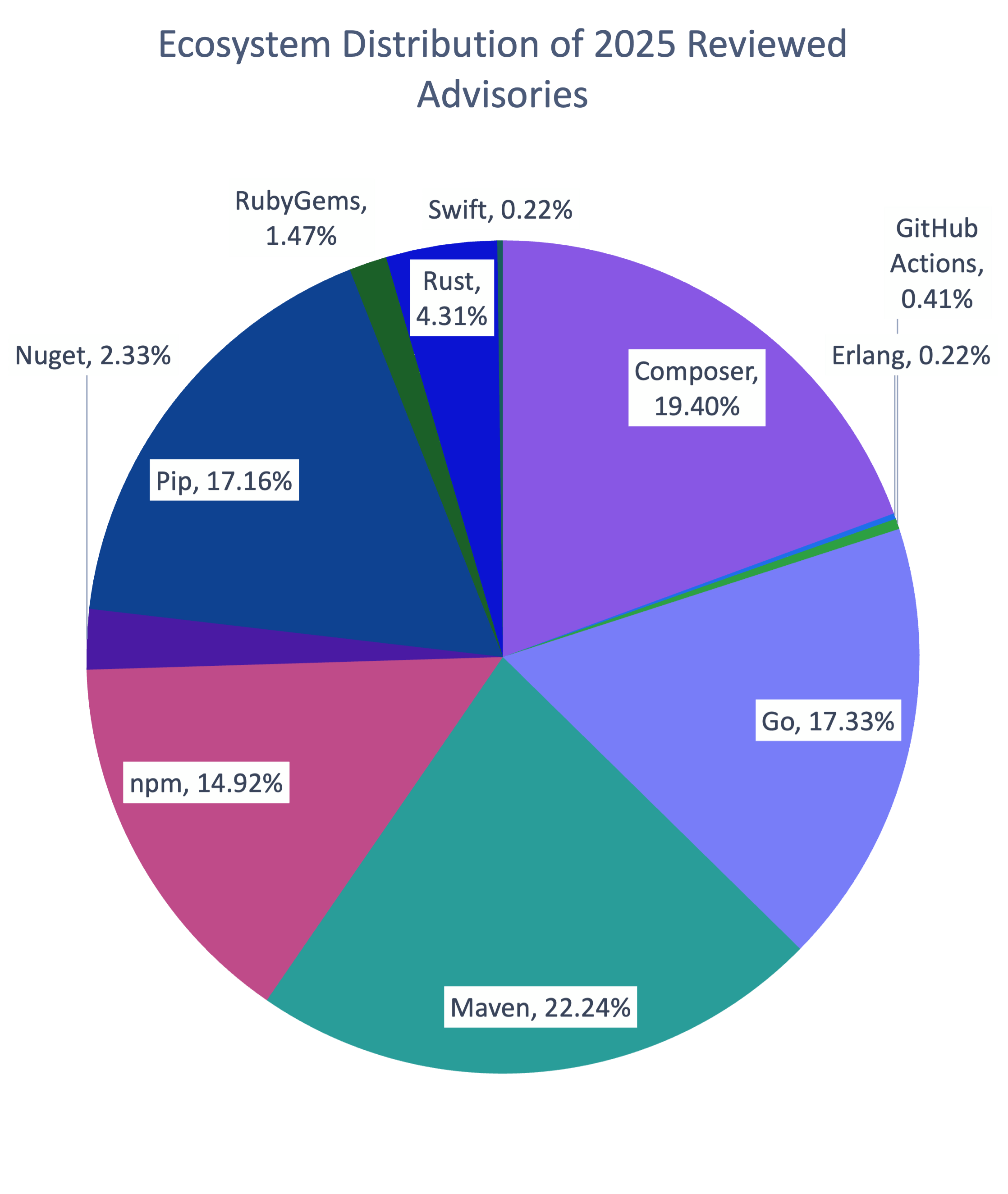
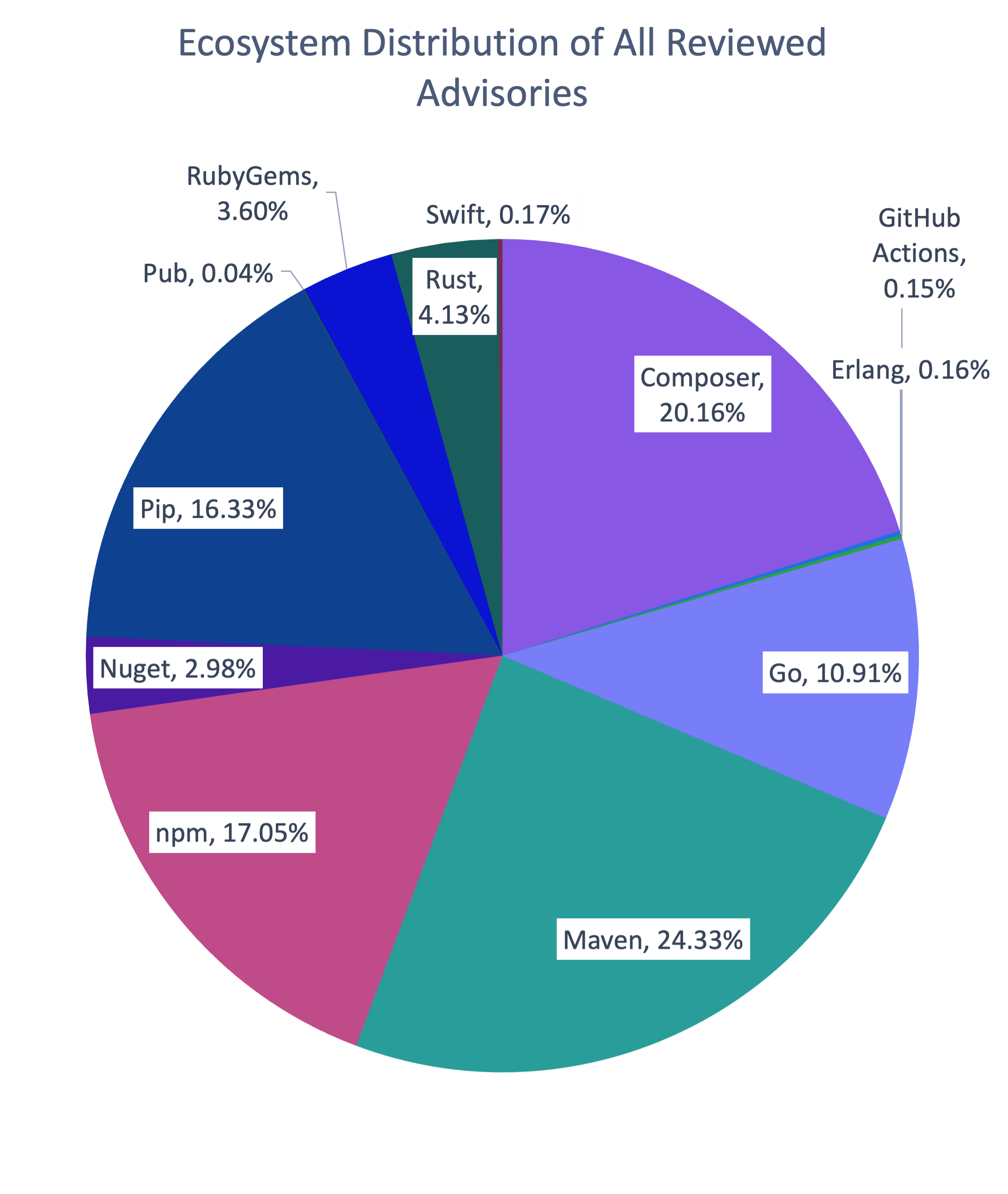
- Enriquecimento de dados de vulnerabilidade. Dependendo das necessidades da organização, isso é necessário para enriquecer as informações combinando dados do NVD, EUVD, BDU, GitHub Advisory Database e osv.dev, ou para comprar um feed de inteligência de vulnerabilidades comercial no qual os dados já estão agregados e enriquecidos. Em ambos os casos, também vale a pena monitorar os feeds de inteligência de ameaças para rastrear tendências de exploração reais e obter um entendimento do perfil dos invasores que visam vulnerabilidades específicas. A Kaspersky fornece um feed de dados especializado especificamente focado em componentes de código aberto.
- Análise detalhada da composição do software. As ferramentas especializadas de análise de composição de software (SCA) permitem o mapeamento correto da cadeia de dependências no código-fonte aberto para realizar o inventário completo das bibliotecas que estão sendo usadas e descobrir componentes desatualizados ou sem suporte. Os dados sobre componentes íntegros também são úteis para enriquecer o registro de artefatos.
- Identificação do abandonware. Mesmo que um componente não apresente vulnerabilidades formais e o encerramento do suporte ainda não tenha sido declarado oficialmente, o processo de verificação deve sinalizar os componentes que não receberam atualizações há mais de um ano. Isso garante uma análise separada e uma possível substituição, assim como ocorre com os componentes em EOL (fim da vida útil).
Proteção do código e dos agentes de IA
As atividades dos sistemas de IA usados na codificação devem ser agrupadas em um conjunto abrangente de medidas de segurança: desde a filtragem de dados de entrada até o treinamento do usuário:
- Restrições de recomendações de dependências. Configure o ambiente de desenvolvimento para garantir que os agentes e assistentes de IA consultem apenas componentes e bibliotecas do registro de artefatos confiável. Se eles não contiverem as ferramentas corretas, o modelo deve acionar uma solicitação para incluir a dependência no registro em vez de extrair algo do PyPI que apenas corresponda à descrição.
- Filtragem das saídas do modelo. Apesar dessas restrições, tudo o que for gerado pelo modelo também deve ser verificado para garantir que o código de IA não contenha dependências desatualizadas, sem suporte, vulneráveis ou inventadas. Essa verificação deve ser integrada diretamente no processo de aceitação do código ou no estágio de preparação da compilação. Ela não substitui o processo de análise estática tradicional: as ferramentas SAST ainda devem ser incorporadas no pipeline de CI/CD.
- Treinamento do desenvolvedor. As equipes de TI e de segurança devem estar extremamente familiarizadas com as características dos sistemas de IA, seus princípios operacionais e erros comuns. Para conseguir isso, os funcionários devem completar um curso de treinamento especializado, adaptados às suas funções específicas.
Remoção sistemática de componentes em EOL
Se os sistemas de uma empresa utilizarem componentes de código aberto desatualizados, deve-se adotar uma abordagem sistemática e consistente para lidar com as vulnerabilidades. Existem três métodos principais para fazer isso:
- Migração. Este é o método mais complexo e caro para uma organização, pois envolve a substituição total de um componente, seguida pela adaptação, reescrita ou substituição dos aplicativos construídos sobre ele. Decidir sobre uma migração é muito mais difícil quando se exige uma revisão geral de todo o código interno. Isso costuma afetar os componentes principais: é impossível migrar facilmente do Node.js 14 ou do Python 2.
- Suporte de longo prazo (LTS). Existe um mercado de serviços de suporte dedicado para projetos legados de larga escala. Às vezes, isso envolve uma bifurcação do sistema legado mantido por desenvolvedores de terceiros; em outros casos, equipes especializadas fazem o backport de patches que corrigem vulnerabilidades específicas em versões mais antigas e sem suporte. A transição para o LTS geralmente exige custos de suporte contínuos, mas, em muitos casos, isso ainda pode ser mais econômico do que uma migração completa.
- Controles compensatórios. Com base nos resultados de análises detalhadas, é possível criar um conjunto de medidas de segurança abrangentes para mitigar o risco de exploração das vulnerabilidades de um produto legado. Tanto a eficácia quanto a viabilidade econômica dessa abordagem dependem da função do software na organização.
Os departamentos de segurança, TI e negócios devem trabalhar juntos para escolher um desses três métodos para cada componente abandonado ou com EOL documentado e refletir a escolha feita nos registros de ativos e SBOMs da empresa.
Gerenciamento de vulnerabilidades de código aberto baseado em risco
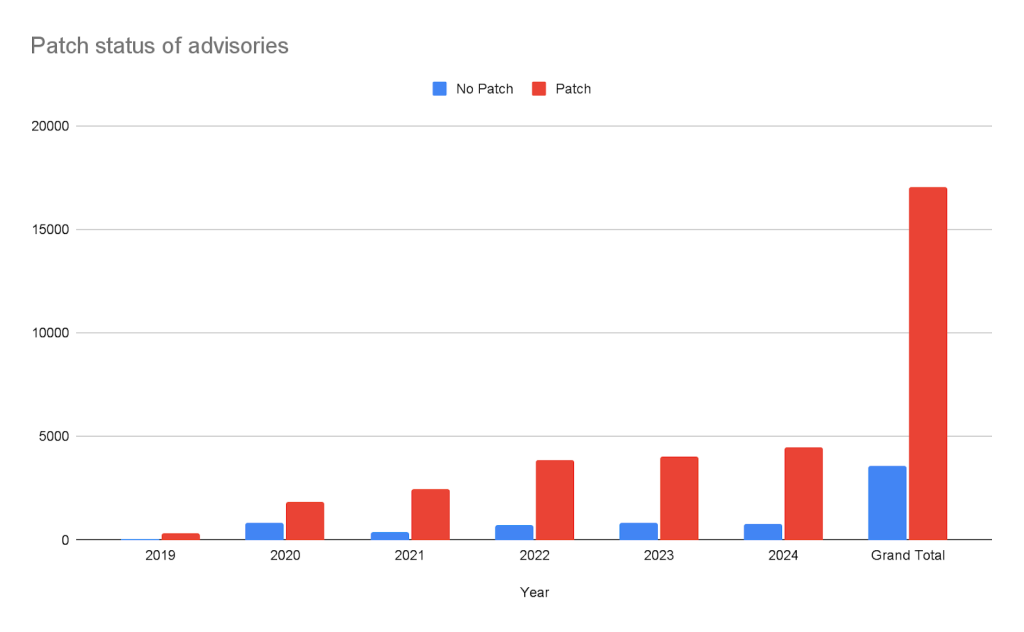
Todos os métodos listados acima reduzem o volume de softwares e componentes vulneráveis que entram na organização, o que simplifica a detecção e a correção de falhas. Apesar disso, é impossível eliminar todos os defeitos: o número de aplicativos e componentes está crescendo muito rápido.
Portanto, é essencial priorizar as vulnerabilidades com base nos riscos reais que elas representam. O modelo de avaliação de risco deve ser expandido para considerar as características do código aberto, além de responder às seguintes perguntas:
- A ramificação do código vulnerável é realmente executada no ambiente da organização? Deve-se realizar uma análise de acessibilidade das vulnerabilidades descobertas. Muitos snippets de código defeituosos nunca são realmente executados na implementação específica da organização, fazendo com que seja impossível explorar a vulnerabilidade. Certas soluções de SCA podem realizar esta análise. Esse mesmo processo permite avaliar um cenário alternativo: o que acontece se os procedimentos ou componentes vulneráveis forem removidos completamente do projeto? Às vezes, esse método de remediação é surpreendentemente indolor.
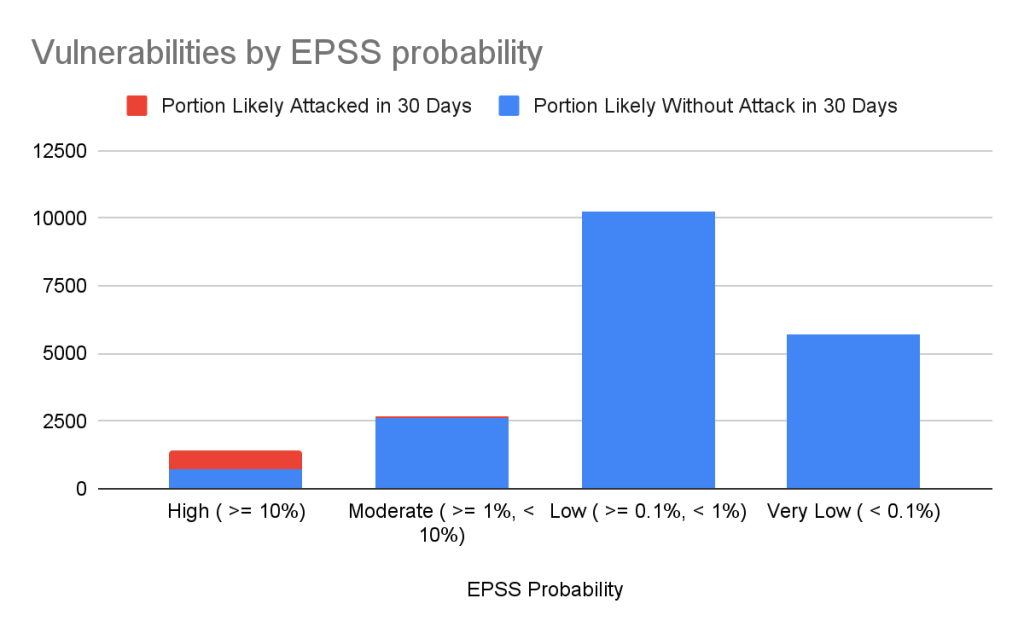
- O defeito está sendo explorado em ataques reais? Há um PoC disponível? As respostas a essas perguntas fazem parte de estruturas de priorização padrão, como EPSS, mas o rastreamento deve ser realizado em um conjunto muito mais amplo de fontes de inteligência.
- A atividade de criminosos cibernéticos foi relatada nesse registro de dependência ou em componentes relacionados e semelhantes? Estes são fatores adicionais para a priorização.
A consideração desses fatores permite que a equipe aloque recursos de forma eficaz e corrija os defeitos mais perigosos primeiro.
A transparência nunca sai de moda
O padrão de segurança para softwares de código aberto só vai continuar subindo. As empresas que desenvolvem aplicativos, mesmo que para uso interno, enfrentarão pressões regulatórias que exigem segurança cibernética documentada e verificável nos seus sistemas. De acordo com as estimativas dos especialistas da Sonatype, 90% das empresas em todo o mundo já se enquadram em um ou mais requisitos que as obrigam a fornecer provas da confiabilidade do software que usam. Portanto, os especialistas consideram a transparência “o pilar fundamental da segurança da cadeia de suprimento de software”.
Ao controlar o uso de componentes e aplicativos de código aberto, enriquecer a inteligência contra ameaças e fazer o monitoramento rigoroso dos sistemas de desenvolvimento orientados por IA, as organizações podem introduzir as inovações que tanto desejam, ao mesmo tempo em que atingem o padrão elevado definido por reguladores e clientes.