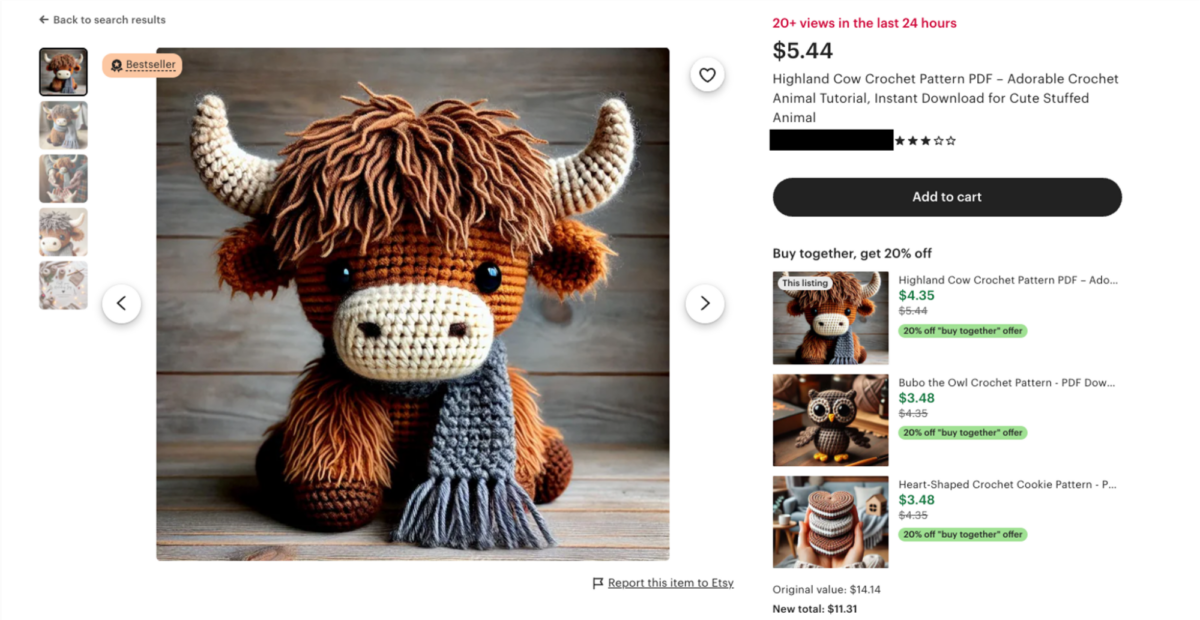
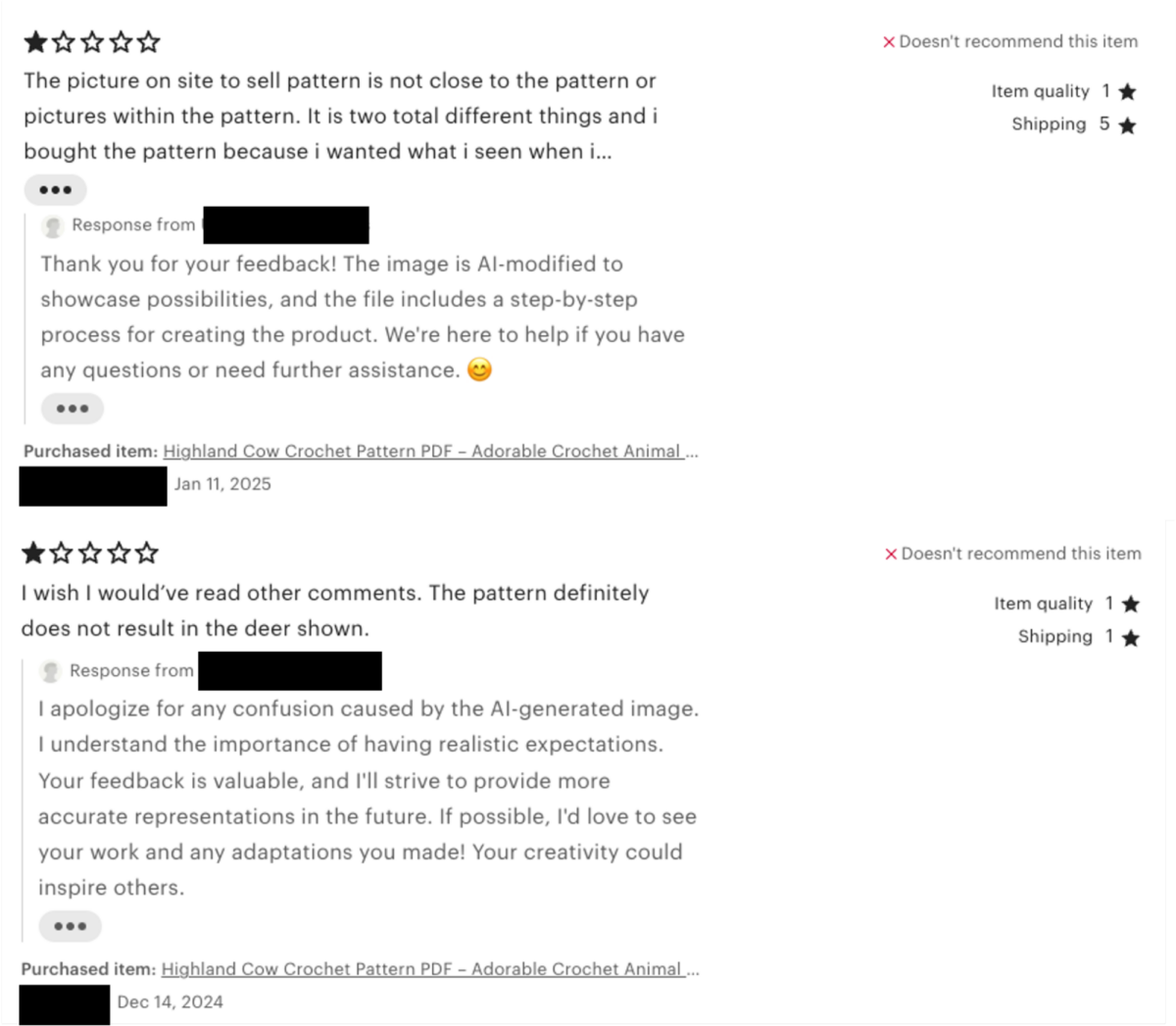
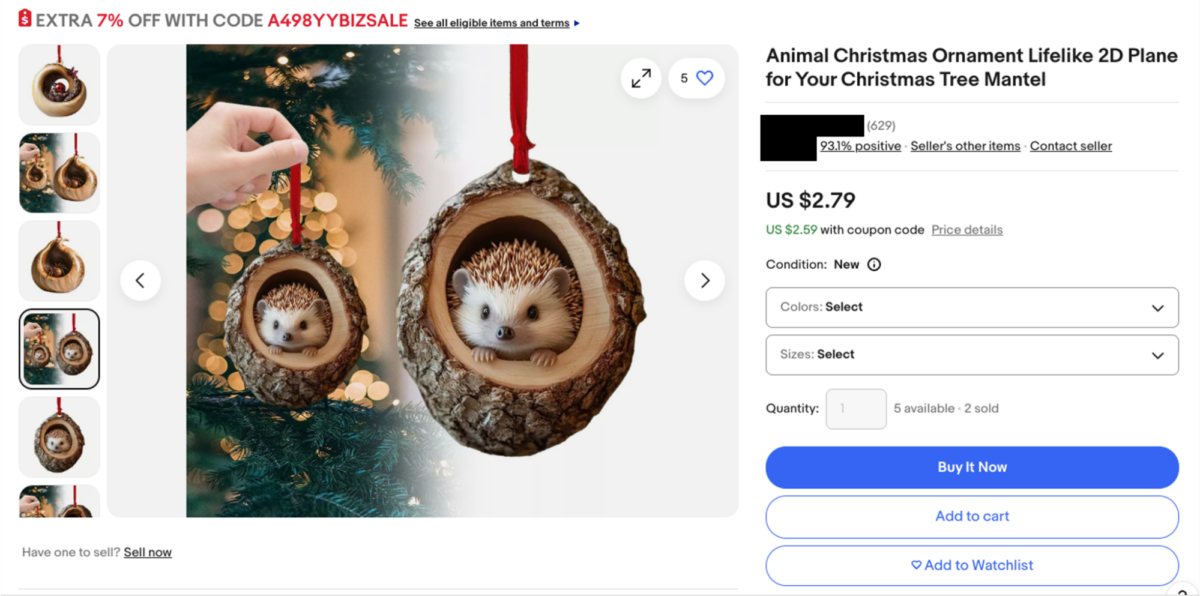
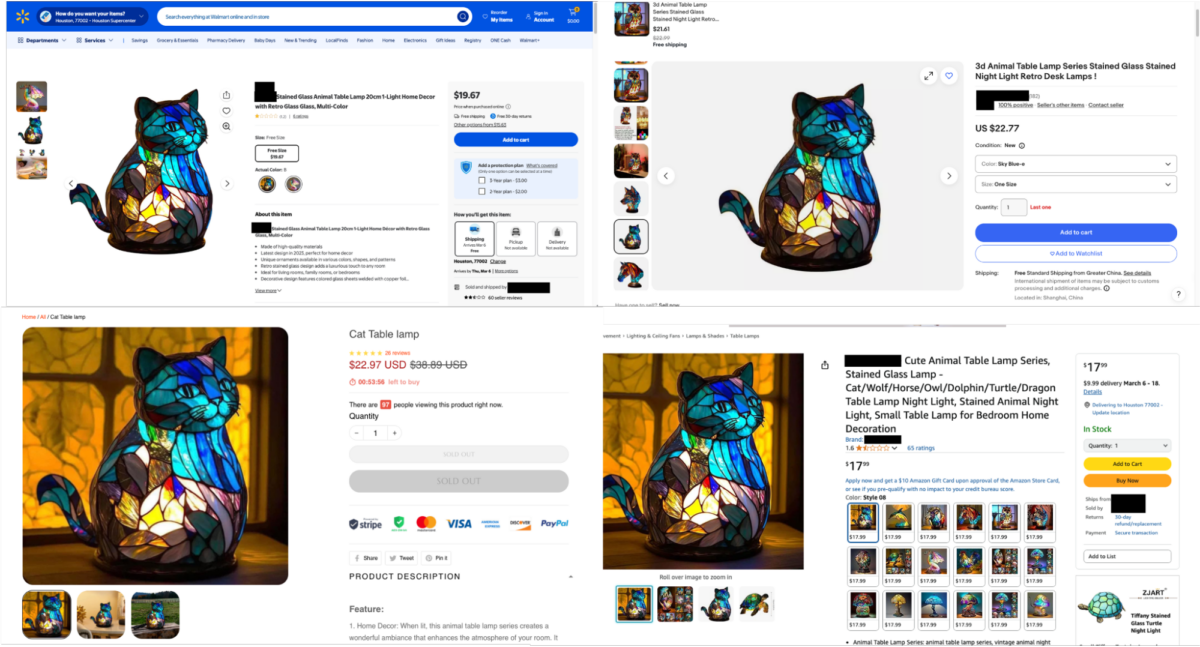
As organizations rebrand themselves as AI companies, most of the conversation is focused on knowledge workers rather than the people in retail, manufacturing, and healthcare who can benefit from AI just as much. Prakash Kota, CIO of UKG, one of the largest HR tech platforms in the market, which delivers a workforce operating platform utilized by 80,000 organizations in 150 countries, explains how his company uses agentic AI, voice agents, and a democratized innovation framework to transform the frontline worker experience, and why the CIO-CHRO partnership is critical to making it stick.
How do you leverage AI for growth and transformation at UKG?
UKG is one of the largest HR, pay, and workforce management tech platforms in the market, and our expertise is in creating solutions for frontline workers, which account for 80% of the world’s workforce. This is important because when companies rebrand themselves as AI for knowledge workers, they’re not talking about frontline workers. But people in retail, manufacturing, healthcare, and so on also benefit from AI capabilities.
So the richness of our data sets, and our long history with the frontline workforce, positions us well for AI driven workforce transformation.
What are some examples?
We use agentic AI for dynamic workforce operations, which shows us real-time labor demand. Our customers employ thousands of frontline workers, and the timely market insights and suggested actions we give them are new and valuable.
We also provide voice agents. Traditionally, when a frontline worker requests a shift, managers would review availability, fill out paperwork or update scheduling software, and eventually offer an appropriate job. With voice agents, AI works directly with the frontline worker, going through background and skills validation, communication, and even workflow execution. The worker can also ask if they can swap shifts or even get advice on how to make more money in a particular month. This is where AI changes the entire frontline worker experience.
We also launched People Assist, an autonomous employee support agent. Typically, when an employee is onboarded, IT and HR need to trigger and approve workflows. People Assist not only tracks workflows, but also performs those necessary IT and HR onboarding activities so new employees are productive from day one.
What framework do you use to create these new capabilities?
For internal AI usage for our own employee experience, we use an idea-to-implementation framework, which involves a community of UKG power users who are subject matter experts in their area. Ideas can come from anybody, and since we started nine months ago, more than 800 ideas have been submitted. The power users set our priorities by choosing the ideas that will make the most impact.
Rather than funneling ideas through a small central team — a linear process that kills momentum — we’ve democratized innovation across the business. We give teams the governance frameworks, change models, and risk guardrails they need to move quickly. With AI, the most important thing isn’t to launch, but to land.
But before we adopted the framework, we defined internal personas so we could collaborate with different employee groups across the company, from sales to finance.
With the personas and the framework, we can prioritize ideas by persona, which also facilitates crowd sourcing. You’re asking an entire persona which of these 10 ideas will make their lives better, rather than senior leaders making those decisions for them.
Why do so many CIOs focus on personas for their AI engine?
Across the enterprise, every function has a role to play. We hire marketing, sales, and finance for a particular purpose. Before AI, we gave generic packaged tools to everyone. AI allows us to build capabilities to make a specific job more effective. Even our generic AI tools are delivered by persona. Its impact on specific roles is the reason personas are so important right now. Our focus is on the actual jobs, the people who do them, the skills and tasks needed, and the outcomes they want to achieve.
We know our framework and persona focus work from employee data. In our most recent global employee engagement survey, 90% said they’re getting the right AI tools to be effective. For the AI tools we’ve launched broadly across the company, eight out of 10 employees use them. For me, AI isn’t about launching 10,000 tools, because if no one uses them, it’s just additional cost for the CIO and the company.
Is the build or buy question more challenging in this nascent stage of AI?
The lifecycle of technology has moved from three years to three hours, so whenever we build at UKG, we use an open architecture, which allows us to build with a commercial product if one comes on the market.
Given the speed of innovation, we lean toward augmentation rather than build. There are areas, like our own native products, where a dedicated engineering team makes sense. But for most of our AI capabilities — customer support and voice agents, for example — we work with our vendor partners. We test and learn with multiple vendors, and decide on one usually within two weeks.
This is what AI is giving all CIOs: flexibility, rapid adoption, interoperability, and the ability to quickly switch vendors. It’s IT that’s very different from what it used to be.
Given the shift to augmentation, how will the role of the software engineer change?
For software builders, business acumen — the ability to understand context — is no longer optional. In the past, the business user would own the business context, and the developer, who owns the technology, brings that business idea to life. Going forward, the builder has the business context to create the right prompts to let AI do the building, and the human in the loop is no longer the technology builder, but the provider of context, prompts, and validation of the work. So the engineer doesn’t go away, however they now finish a three-week scope of work in hours. With AI, engineers operate at a different altitude. The SDLC stays, but agility increases where a two-week concept compresses into two days.
At UKG, you’re directly connected to the CHRO community. What should they be thinking about how the workforce is changing with AI?
The best CHROs are thinking about the skills they’ll need for the future, and how to train existing talent to be ready. They’re not questioning whether we’ll need people, but how to sharpen our teams for new roles. The runbooks for both IT and HR are evolving, which is why the CIO-CHRO partnership has never been more critical to create the right culture for AI transformation.
CIOs can deliver a wealth of employee data like roles, skillsets, and how people spend their time. And as HR leaders help business leaders think through their roadmap for talent — both human and AI — IT leaders can equip them with exactly that intelligence.
What advice would you give to CIOs driving AI adoption?
Invest in AI fluency, not just AI tools. Your people don’t need to become data scientists, but they do need a new kind of literacy — the ability to work alongside AI, question its outputs, and know when to override it. That’s a training and culture investment, not a software investment.
And redesign work before you redeploy people. Don’t just drop AI into existing workflows. Use this moment to ask what work really matters. AI is forcing us to have the job design conversations we should’ve had years ago, so it’s important to be transparent about the journey. What’s killing workforce trust now is ambiguity. Your people can handle hard truths but not silence. Leaders who communicate openly about where AI is taking the organization will retain the talent they need to get there.
The next time someone on your team says, ‘hire an AI engineer,’ stop the conversation.
That title is too vague because it fails to account for critical differences in engineering strengths. Instead, companies need to decide specifically what they need. Is it someone to rapidly prototype AI solutions? Or someone to build the solution that makes it ready for production? Or someone to design the supporting capabilities and infrastructure to scale it? These are all different skills and require different assessments during the hiring process.
But here’s where companies also fall short. Assessing skills is hard and assessments, as we know them, are broken when it comes to AI. They’re misaligned with what AI roles actually demand. That misalignment is what I call the AI assessment gap.
Where the gap lives
Most technical assessments were built for a pre-AI world: Coding proficiency, algorithms, deterministic system design. These are skills tests. They confirm that an engineer can do the work. But they don’t tell you whether that engineer has the technical taste to make the right decisions when building, scaling or deploying AI systems in production.
In conversations with enterprise engineering leaders, we’re hearing that candidates are now running AI agents during live interviews, getting textbook-perfect answers fed to them in real time. If your assessment can be passed by an AI whispering in someone’s ear, it was never testing for the right thing. Skills can be faked or augmented. Taste can’t.
To see what this looks like, consider this scenario: An enterprise needs someone with deep experience in a specific data platform. A candidate passes the data engineering assessment. They get to the client interview, and the hiring manager says: ‘Tell me about a time you had to make a hard tradeoff in designing a streaming architecture.’ The candidate defines every concept involved. They don’t have the taste to explain why one approach would be dramatically better than another for a specific context. They’re out.
This happens because most assessment pipelines only test for skills: Can they code, understand the fundamentals? Nobody is systematically testing for technical taste: Can this person make better-than-default decisions about architecture, tooling and approach? That question only surfaces once someone with real experience asks it. By then, everyone has wasted time and the role is still open.
Traditional job postings compound the problem by filtering for ‘5+ years of AI experience,’ which screens out strong candidates because the category itself is only a few years old. What matters at the AI layer isn’t tenure. It’s the depth and specificity of what someone has built, deployed or scaled in production. Meanwhile, seniority at the foundational role level still matters in the ways it always has: A senior engineer brings architectural judgment that can’t be shortcut. The mistake is applying years-of-experience filters to the AI layers, where the work hasn’t existed long enough for tenure to be a meaningful signal.
One of the most telling signals of a broken assessment process: When stakeholders simultaneously complain that assessments are too hard and too easy. That’s not a calibration problem. It means the assessments aren’t measuring the right things in the first place. They’re testing for skills when they should be testing for taste.
Start with the work, not the title
To close the AI assessment gap, decompose the problem before you assess and decompose the need across the dimensions that actually determine whether someone can do the job. For example:
Dimension
The Question
What It Determines
How You Evaluate
Role
What technical domain does the work live in?
Foundational skills and stack (e.g., backend engineer, Python, PostgreSQL)
Skills assessment: Project-based or simulation-based filter that confirms core engineering competency
Seniority
What level of judgment and autonomy does this work require?
Engineering maturity, depth of technical taste, ability to operate under ambiguity
Experience depth at the role level: Years of practice in the domain, complexity of systems designed and shipped
AI Engagement Pattern
How will this person engage with AI systems?
The specific technical taste required (e.g., Prototyper needs taste for sensing value; Builder needs taste for architecture and integration decisions; Scaler needs taste for performance, governance and risk tradeoffs)
Applied assessments: Not ‘define RAG’ but ‘given this use case, which approach would you choose and why?’ Testing for tradeoff reasoning, not terminology
This decomposition replaces the single job description with a structured picture of what you actually need. It also immediately reveals whether you’re looking for one person or a team. If the project requires rapid prototyping to find value and then a production build, you probably need engineers with different profiles–not one ‘AI engineer’ who’s supposed to do both.
Three things most enterprises get wrong
They test for skills when they should test for taste. Most assessments confirm that an engineer can write code and define concepts. They don’t test whether that engineer can make the architectural and tooling decisions that actually determine project success. An engineer who knows what agentic search is and an engineer who knows when agentic search is the right choice for a specific problem are two completely different hires. The first passes your skills test. The second delivers in production.
They conflate skills with experience. A skills assessment tells you if someone can do the work. An experience validation tells you if someone has done the work in the specific context the job demands. These require completely different evaluation methods. When companies try to test both with a single instrument, they get the ‘too hard and too easy’ paradox: The assessment is simultaneously screening out competent people and letting through candidates who can’t perform. Seniority and years of experience are meaningful at the role level, where 10 years of backend engineering builds real architectural judgment and compounds technical taste. They’re much less meaningful at the AI engagement layer, where the work itself is only a few years old and depth of hands-on exposure matters more than calendar time.
They treat assessment as a snapshot. The traditional model is a one-time gate: Pass or fail, in or out. In an AI world where skills are evolving monthly, that approach breaks down fast. Six months ago, almost nobody was shipping production code with agentic tools like Claude Code. Model Context Protocol, which lets AI systems plug into enterprise tools and data sources, was barely on anyone’s radar. Now enterprises are hiring for these skills specifically. Six months from now, the list will change again.
That means an assessment built in January is already partially stale by June. Companies that treat assessment as a living system, continuously updated by performance signals from real engagements, will consistently field better talent than those running the same tests they built a year ago.
The reskilling imperative
The reality is, there is no way to close this gap through hiring alone. The supply of engineers who already have the technical taste for AI work is a tiny fraction of what the market demands. For example, since the launch of ChatGPT in 2022, demand for roles that require more analytical, technical or creative work has increased by 20%.
Which means enterprises have to reskill and upskill existing workforces. And without a targeted approach mapped to actual needs, AI upskilling efforts often fail, leaving employees unsupported and initiatives stalled.
This is where the multi-dimensional model pays off beyond hiring. The same framework that powers your talent acquisition also powers your training strategy. Assessment results don’t just filter candidates in or out. They generate a heat map of where your workforce is strong and where it’s thin, across every dimension: Role competency, seniority depth and the specific technical taste required for prototyping, building or scaling AI systems. That heat map becomes your training roadmap.
Most companies skip this entirely and jump straight to ‘let’s buy an AI training program.’ Without that foundation, even the best training program is solving the wrong problem.
Ever ready
In the world of AI, the most critical skill might be knowing that you don’t and can’t possibly know everything. Or even what’s coming next. The roles we need today will look different in six months. The skills taxonomies we build now will need constant revision. The assessments we deploy this quarter will need recalibration by next quarter.
Companies that accept this reality and build nimble, multi-dimensional approaches to talent assessment will find something valuable: The technical taste they need already exists in their workforce, hiding behind outdated job descriptions and misaligned tests. CIOs must actively audit these descriptions to eliminate the traditional experience filters that mask the latent talent already sitting on their teams. The others will keep posting for ‘AI engineers’ and wondering why nobody who gets hired can actually do the job.
This article is published as part of the Foundry Expert Contributor Network. Want to join?
Workers are facing a conundrum: They worry about the potential for their displacement by AI even as it dramatically speeds up their own productivity.
According to a new survey from Anthropic, workers in roles most likely to be taken over by AI (developers or IT workers, for instance) recognize their precarious position. Yet, perhaps naturally, they readily adopt the tools that could take their jobs, and see first-hand how well they work.
This measurement is fundamentally different from the way others are gauging AI job displacement, noted Thomas Randall, research director at Info-Tech Research Group.
While macro reports, such as those from Goldman Sachs, the International Monetary Fund (IMF), or the World Economic Forum (WEF), are asking what share of existing job tasks AI could theoretically perform in the future, “Anthropic is measuring qualitative experiences of workers in the present,” he pointed out. This “tells us how people are navigating this landscape in real time.”
The paradox of AI in the workforce
Anthropic’s survey of 81,000 Claude users gauged peoples’ “visions and fears” around advances in AI, and weighed these findings against the company’s own measurement of jobs most vulnerable to AI displacement. This was based on Claude usage data; jobs are identified as more exposed when associated tasks are significantly performed on the platform, in work-related contexts, and take up a larger share of a role.
Some occupations at risk include computer programmers, data entry keyers, market researchers, software quality assurance analysts and testers, information security analysts, and computer user support specialists.
Overall, one-fifth of respondents expressed concern about displacement, noting that their job, or at least aspects of it, is being taken over by automation. Those in jobs identified as most exposed readily recognized that fact, voicing worry three times as often as those in less at-risk positions. One software engineer remarked: “like anyone who has a white collar job these days, I’m 100% concerned, pretty much 24/7 concerned, about losing my job eventually to AI.”
Early-career respondents were also more nervous than others.
At the same time, those in the highest-paid occupations reported the largest productivity gains when using AI. This is most notably in terms of their ability to perform new tasks, which was cited by 48% of users. In addition, 40% of workers said the technology helped speed up their work, and a little more than 10% said it improved the quality of their work.
In general, enterprise usage of AI is “actually quite consistent,” said Sanchit Vir Gogia, chief analyst at Greyhound Research. Teams are using the technology “where information is abundant and time is limited,” such as in drafting documents and code, summarizing content, responding to customer queries, navigating internal systems.
Is AI actually creating more work?
Still, not everyone thinks AI makes their jobs easier or faster. In some cases, people felt it made their work harder; for instance, project managers are assigning tickets for issues that are much more difficult to solve, Anthropic noted.
Gogia agreed that, even when tasks become easier, scope and responsibilities expand, and roles can absorb adjacent tasks. This results in a “redistribution of effort,” rather than a reduction of effort.
“Faster generation means higher expectations on quality,” he said. More output feeds into decision pipelines that are already constrained. “In some cases, the system becomes heavier, not lighter.”
Delayed impact on enterprises
The market is rewarding those who can integrate AI into complex workflows to do more, faster, and often with better outcomes, Gogia noted. However, the most exposed tasks, including documentation, basic coding, routine analysis, and structured support work, often “sit at the base of the experience ladder.”
These very tasks traditionally have given entry-level workers a way in, and the automation of them reduces the urgency for companies to hire them. “What you begin to lose is not the job,” said Gogia. “It is the path into the job.”
This can have a delayed impact; enterprises may not realize until years later that they do not have enough mid-level experts because they didn’t bring enough people in at lower levels. As AI plays a greater role in the workplace, there must be a “conscious effort” to rethink how people enter and grow, Gogia said. “New pathways need to be created, and they need to be deliberate.”
How enterprise leaders should adjust
As is often the case, sentiment moves faster than structural change, Gogia pointed out. Workers feel the shift almost immediately, but organizations take longer to adjust hiring, redesign roles, and rethink workforce structures.
“This is why expectations can become misaligned,” he noted. The reality is that most enterprises have introduced AI into existing ways of working without fundamentally changing them. Acceleration occurs in unchanged systems that still carry the same dependencies, approval chains, and coordination challenges.
Ultimately, Gogia advised, leaders must approach the shift with “intentional design.” This requires clarity, he emphasized; people need to understand how their work is expected to change. What will be enhanced? What will reduce? Where should they focus their development?
Baselines are moving: Roles may begin to look “oversized” as what used to be considered a full day’s work begins to look like half a day’s work, or what used to be considered efficient begins to look average. “AI is changing how work is done, but more importantly, it is changing what work expects from people,” said Gogia.
As well, Info-Tech’s Randall pointed out that workers who experience AI expanding what they can do by performing tasks previously outside their competence appear to relate to AI more positively than those who experience it as doing their existing job faster. So, he advised, “tech leaders should design AI deployment around capability extensions.”
Along with goal setting, managers must have support, Gogia emphasized. They set expectations and interpret strategy, and when they’re not properly equipped, “even the best tools will fall short,” he said. Measurement must also evolve; enterprises need to look at quality, sustainability, and capability development over time.
“What we are witnessing right now is not a sudden disruption,” said Gogia. “It is a gradual shift that is becoming impossible to ignore.”
Somewhere in your organization’s hiring stack, there is probably an AI system producing candidate scores. If you’re a leader who helped evaluate or approve that system, here’s a question worth sitting with: If one of those scores got challenged, by a candidate, an internal audit or a regulator, could your team explain how it was produced?
Not “the vendor said it’s accurate.” Not “the model was trained on historical data.” A specific, documented explanation of what criteria were evaluated, how the candidate performed against them and why those criteria are job-relevant.
For a growing number of organizations using AI video interview scoring tools, the honest answer is no. And as regulatory frameworks targeting employment AI move from guidance to enforcement, that answer is a risk.
What the system is actually optimizing for
Before asking how accurate an AI scoring system is, the right question is what it is optimizing for.
Many video interview scoring platforms evaluate tone of voice, pace, eye contact, facial expressions and fluency alongside or in some cases instead of, the actual content of candidate responses. The underlying assumption is that these signals correlate with job performance or cultural fit. The evidence for that assumption is weak. The evidence that measuring these signals introduces systematic, legally significant bias is much stronger.
Several major players in this space removed facial analysis features after regulatory pressure and public scrutiny. That acknowledgment — that criteria advertised as objective were neither reliable nor fair — should raise a harder question. If those criteria were in production and no one caught it until outside pressure forced a change, what else is still being measured that shouldn’t be?
This is not a hypothetical risk. The EEOC has made it clear that employers are liable under Title VII for discriminatory outcomes from AI hiring tools, regardless of whether those tools were built in-house or purchased from a vendor. New York City’s Local Law 144 requires annual independent bias audits of automated employment decision tools and public disclosure of results. Illinois requires notice and consent before AI is used to evaluate video interviews. The EU AI Act, whose high-risk AI provisions take full effect this August, explicitly classifies employment AI as high-risk, with binding requirements for transparency, explainability and human oversight.
The common thread: Can you explain what your AI is measuring, and can you demonstrate that it’s measuring the right things?
The accountability problem at the executive level
For technology leaders, this is where the conversation becomes concrete.
Consider the scenario: A hiring decision gets challenged by a candidate, an internal audit or a regulator. The question is how the decision was made. “The AI scored them lower” is not a defensible answer in any of those contexts. It can’t be traced to specific job-relevant criteria. It can’t be explained to the candidate. It won’t satisfy an auditor. And if the system’s logic is proprietary and opaque, the organization has no way to produce a satisfying answer even if it wants to.
The organizations that adopt black-box scoring tools often do so with the right intentions: To reduce human bias and create a more consistent process. Those are legitimate goals. But a system whose internal logic can’t be questioned, explained or audited just obscures bias. It doesn’t reduce it. And when bias becomes difficult to see, it becomes more difficult to address.
This is a pattern you’ll recognize from other domains. When a system produces outcomes that look plausible but are wrong in ways that aren’t immediately visible, the failure compounds before it surfaces. The cost of discovering it late is almost always higher than the cost of building it right from the start.
What a defensible architecture looks like
There is a meaningful difference between AI that scores interviews and AI that scores interviews in a way that can be explained and defended. The distinction is structural.
Defensible scoring starts before any candidate records a response. It starts with the job. What competencies does this role require, and what does strong performance against each competency look like? From those answers, explicit rubrics are developed. Criteria that describe what high-quality, adequate and weak responses look like for each dimension being evaluated. Those rubrics are reviewed and approved by the hiring team before scoring begins.
When responses come in, the AI evaluates what candidates actually said against those pre-defined criteria. Not tone. Not pacing. Not facial expression. What they communicated, measured against a standard the hiring team set, and can explain. Criterion-level scores roll up to an overall assessment, and every part of that chain is visible and auditable.
This architecture has an important secondary property: The human remains meaningfully in the loop. The AI generates a starting point by identifying relevant competencies and drafting rubric criteria from the job description, but the standard is owned by the people responsible for the hire. If a hiring manager can’t look at a scoring rubric and explain what it’s evaluating and why, it should not be deployed. That is not a burden on the tool. It is the minimum condition for using it responsibly.
Four questions for the governance conversation
For leaders evaluating or overseeing AI video interview tools, four questions surface most of what matters.
What specifically is the system scoring? Request an explicit list of evaluation criteria. If the answer includes anything beyond the content of candidate responses, ask for the validation data that connects those criteria to job performance outcomes.
Are the criteria derived from job requirements?Generic rubrics applied uniformly across roles create standardized evaluation, not structured evaluation, which is different. Legitimate scoring starts from the specific competencies required for the specific role.
Can the criteria be reviewed, modified and approved before scoring begins? If the rubrics are fixed and opaque, the organization is not in control of its own evaluation standard. That is a governance gap.
Can any score be explained to a candidate or a regulator? This is the accountability test. If the explanation requires “the AI said so” rather than pointing to specific, documented criteria and how a candidate performed against them, the process will not withstand scrutiny.
Well-designed systems answer these questions directly. The ones that can’t are telling you something important about the tradeoffs their creators made.
Why this moment matters
The EU AI Act deadline is in August, forcing organizations with global operations or EU-based candidates to evaluate their tech. But getting this right isn’t just regulatory, it’s practical.
When hiring teams can see exactly how a score was produced, they use it. When they can’t explain it, they override it or work around it, the efficiency gains disappear. The tools that will last in enterprise hiring stacks are the ones that make decisions transparently enough that the humans responsible for those decisions trust them.
That’s not a high bar. But it requires being precise about what any given AI system is really measuring. And honest about whether that’s what you actually want to know.
This article is published as part of the Foundry Expert Contributor Network. Want to join?
But despite these strict controls, Chinese apps – which boast more than a billion estimated users – remain an information goldmine for investigative journalists covering stories both within and outside China.
Support Bellingcat
Your donations directly contribute to our ability to publish groundbreaking investigations and uncover wrongdoing around the world.
Since most foreign sites are banned, Chinese platforms are the largest resource available to journalists and researchers interested in what’s going on in the world’s second-most populous country. Even when a topic is being censored, patterns in the censorship can themselves serve as investigative leads: a 2020 BuzzFeed News investigation, for example, mapped out detention camps in Xinjiang by examining areas that had been blanked out on China’s Baidu Maps.
With millions of Chinese people living overseas, social media activity by members of the diaspora can also turn into global stories.
Serial rapist Zou Zhenhao, a Chinese PhD student, was jailed in London last year after one of his victims posted a warning on Xiaohongshu, also known as Little Red Book or Rednote, an app popular with young Chinese women living abroad. Another woman Zou had raped reached out to the original poster, who put her in touch with the police – leading to the conviction of a man described by police as possibly one of the worst sexual predators in British history.
Founded in 2013 as a Hong Kong shopping guide, Xiaohongshu has evolved into a lifestyle and e-commerce platform that has been compared with Instagram, Pinterest and Amazon. Last year, it reported about 300 million monthly active users, rivalling some of China’s largest social media platforms.
Xiaohongshu saw a surge in international users in January 2025 amid a threatened ban on short video app TikTok. Photo: VCG via Reuters Connect
The app’s 600 million daily searches by the end of 2024 also accounted for half of market leader Baidu’s search volume, demonstrating that it is emerging as a critical search and discovery engine, not just a social platform.
Although primarily a Chinese-language app, Xiaohongshu gained attention in the English-speaking world last year, when millions of American TikTok users flocked to the platform in anticipation of a TikTok ban under US President Donald Trump.
Responding to the surge of international users – sparked by the #TikTokRefugees trend – Xiaohongshu rolled out an AI-powered translation feature, making the app more accessible to non-Chinese audiences. This also meant that journalists without Chinese language skills can more easily communicate on and navigate the platform.
Despite its growing popularity both within and outside China, the app is relatively new and underexplored compared to more well-established platforms such as Weibo.
This guide aims to provide a starting point for those looking to explore Xiaohongshu for open-source investigations, including an overview of its main user demographics, potential topics to explore and strategic search methods specific to the app.
User Demographics and Topics
According to Xiaohongshu’s official data, the platform’s demographic profile is mainly young, female and urban. As of 2024, 70 percent of its users were women, with half of all users belonging to Gen Z and living in China’s largest cities.
As previously mentioned, the app has also gained popularity with the Chinese diaspora. Many Chinese nationals living abroad use it as a search engine for local information, posting and searching for content related to their daily lives, from restaurant recommendations and apartment hunting to navigating foreign bureaucracies and finding community resources.
This demographic profile makes Xiaohongshu particularly well-suited for investigating stories about consumer fraud and urban livability issues. For example, Chinese outlets like Jiemian have used Xiaohongshu posts to expose the grey-market ecosystem of paid reviews and fake endorsements tied to the platform’s e-commerce model, while in 2022, International Financial News traced a mother-and-baby store scam that defrauded over 400 parents back to product recommendation posts on the platform.
Given its predominantly female user base, Xiaohongshu has also evolved into one of China’s most important spaces for feminist discourse and women’s issues. Academic researchers have used content on the platform to analyse local discussions on menstrual shaming, sexual harassment, and the controversial “divorce cooling-off period” introduced in 2021. As Rest of World reported, women have increasingly congregated on Xiaohongshu, where they outnumber male users and have found ways to trick the app’s recommendation algorithm so their posts are shown mostly to other women.
The Relevance of Censorship
Political content and current affairs about China are largely absent from the app – a result of both active censorship and platform design.
All Chinese social media platforms, including Xiaohongshu, operate under strict content moderation requirements from the Cyberspace Administration of China. A leaked 143-page internal document published by China Digital Times in 2022 revealed how Xiaohongshu censors respond to government directives in “real-time”, blocking content related to politically sensitive topics such as criticism of the Chinese Communist Party, labour strikes and student suicides. Xiaohongshu’s commercial focus also makes it less likely that these topics would be discussed on the platform: as Rest of World reported, the platform functions less like Weibo – a public square for current events – and more like “a giant mall, where shoppers tell each other what to buy”.
Coverage of international affairs is also tightly controlled: only state-owned or state-controlled news organisations can obtain licences to publish original news content. However, content about life abroad, particularly stories about the cost of living, healthcare, or social problems in Western countries, circulates more freely on platforms including Xiaohongshu, and provide journalists with insight into how Chinese diaspora communities engage with local political systems.
For example, when the 2025 Miss Finland was accused of making anti-Asian gestures, searching for “芬兰小姐” (Miss Finland) and “投诉” (complaint) on Xiaohongshu revealed a trove of collective action: users shared different complaint pathways, posted templates for filing reports, and documented various outcomes from their complaints.
For such large-scale public events, Xiaohongshu can be both an organising platform and a rich source for tracking how diaspora communities coordinate responses to discrimination, providing journalists with insight into grassroots activism and transnational advocacy networks.
Getting Started
Xiaohongshu is available for download on both Apple’s App Store and Google Play worldwide, or can be accessed via a web browser. In international app stores, the app appears under the name “RedNote,” but this is the same application as Xiaohongshu – content and accounts are shared across both. The key difference is that RedNote users who register with overseas phone numbers are automatically tagged as international users, which affects the content the algorithm surfaces to them.
For users who download the app outside mainland China, Xiaohongshu automatically detects the device language and location. Upon first login, international users are prompted with an option to automatically translate all content into English (or their device language). If enabled, posts and comments will display with translations by default, and the algorithm will prioritise English-language content and posts created by or for international users, such as expat influencers.
For researchers and journalists seeking to observe the platform as Chinese users experience it, consider disabling automatic translation. This allows you to see content as it natively appears and helps you distinguish between posts created for international audiences versus those created for domestic users – a distinction that matters when assessing how representative your sample is for the relevant topic.
The default home feed, or the “Explore” tab, is where the algorithm surfaces content based on your engagement history, location and user profile. The feed uses a grid layout displaying post thumbnails with titles and like counts.
On the top right corner of the screen, the search bar also allows keyword searches across posts, users and topics. Results can be filtered by content type (e.g. notes, videos, users or products) and sorted by relevance or recency.
The search bar on the top right and the Explore page are some of the most relevant features for journalists and researchers on Xiaohongshu. Source: Xiaohongshu
Using the Search Bar
Xiaohongshu’s search function is relatively basic. You can search by keywords and filter by time and location, but the options are general: time filters include “past day,” “past week,” or “past six months,” while location filters offer “same city” or “nearby”.
For example, searching “Canada” returns posts tagged with that keyword, which you can then sort by recency or proximity.
Search results for “Canada” in English (left) show mainly travel and tourism-related content, while a search in Chinese (right) shows more content posted in Chinese by Chinese people about living in Canada. Source: Xiaohongshu
For breaking news events, try searching location names or names of individuals involved in the incident, filtering for the most recent posts to capture real-time reactions and on-the-ground accounts before they’re censored or deleted.
Xiaohongshu primarily uses algorithms to curate and push content through personalised feeds. For journalists using Xiaohongshu for investigative purposes, it can be useful to actively search for topics of interest to train your algorithm – the more you search and engage with specific content, the more relevant posts the algorithm will surface to you.
However, if you are researching the platform itself – studying what content Xiaohongshu promotes, how censorship operates, or what narratives dominate – you may want to start from a clean slate. In that case, consider periodically turning off personalised recommendations (Settings → Privacy Settings → Personalisation Options), clearing your browsing history, clearing cached data, or using a fresh account to observe what the platform shows to a “neutral” user.
Language and Lingo
During the influx of “TikTok refugees” in January 2025, Xiaohongshu launched a translation feature for users outside mainland China, enabling the automatic translation of comments and posts.
However, this does not translate search queries. The platform’s search engine is still optimised for Chinese, though there is a “prioritise English” filter for overseas users, and searching in English will return some results.
Searching for “Canada” in English, with “EN preferred” selected, will mainly return posts in English. Source: Xiaohongshu
But the language you search in shapes far more than just your results – it determines which version of the platform you see. When you search in English or use an international account, the algorithm treats you as a foreign user and surfaces content accordingly: influencers explaining why they love living in China, comparisons showing Chinese life favourably against the West.
This isn’t a neutral cross-section of the platform – it is a curated bubble. To access what Chinese users actually discuss among themselves, it would be more effective to search in simplified Chinese and, ideally, use a China-registered account if you have access to one. If you don’t read Chinese, you can also consider using a translation tool (Google Translate, DeepL, or an AI assistant) to convert your search terms into simplified Chinese before entering them.
Despite such tools and the in-app translation feature, it is always useful when researching using Chinese platforms to work with a native speaker familiar with the local context. They can flag when an innocuous-seeming term actually carries hidden meaning, and help identify coded conversations about a censored topic.
On Xiaohongshu specifically, this coded language extends beyond political topics to include anything the platform’s algorithm might flag as “vulgar” or promotional. For example, users substitute fruits and neutral terms for body parts or sexual content to avoid being flagged as inappropriate – the peach emoji for buttocks, or 炒菜 (“cooking”) for explicit material. They may also use abbreviations and emojis for commercial terms to evade anti-marketing filters, such as “vx” (the abbreviation of how WeChat is pronounced in Chinese) or “绿” (“plus green”, apparently referring to WeChat’s green logo) for WeChat, or “米” (rice) or the moneybag emoji for money.
Advanced Search Strategies
For more sophisticated searching, consider using third-party marketing analytics tools like Xinhong and Qiangu, which can show trending topics, popular posts and engagement metrics, as well as identify key content creators posting about specific subjects.
For example, on Xinhong, when you search for “Canada” in Chinese, it also shows show trending related searches such as “加拿大总理” (Canadian Prime Minister). Clicking through these suggestions leads to recent posts—for example, posts about Mark Carney’s latest statements at Davos, along with user comments and reactions.
A search on the Xinhong platform for “Canada” in Chinese also suggests related trending topics (in green box) such as “in Canada”, “living in Canada” and “Canadian Prime Minister”. Source: Xinhong, annotation by Bellingcat
While these tools are designed for marketers, they provide journalists with valuable capabilities: tracking how topics evolve, identifying influential voices in specific communities, and discovering related hashtags or discussions that might not surface through basic platform search. These tools often require paid subscriptions but can significantly enhance research efficiency for long-term investigations.
Another valuable feature is Xiaohongshu’s group chat function, where users gather around shared keywords and topics—from city-specific communities to niche interests. These groups are often highly active and provide access to candid community discussions that don’t appear in public posts. To find relevant groups, go to Messages → Group Square, where you can browse categories or search by keyword and request to join.
Monitoring active group chats related to relevant topics, whether that’s a specific city, industry, or issue, can help journalists and researchers stay updated on emerging issues and detect potential story leads before they become widely visible on public feeds.
Preserving the Evidence
Chinese social media content can disappear quickly and without warning due to censorship, making immediate preservation critical.
Always take two preservation steps immediately upon discovering relevant content:
First, screenshot the entire post, including the URL, timestamp, username, like/comment counts, and location tags. These metrics establish context and authenticity. Use tools that capture full-page screenshots rather than just visible portions, as posts can be long and comments extensive. Second, archive the web page using services like archive.today or Wayback Machine. Note that these services capture only static content – comments and engagement metrics may not be fully preserved and should be screenshotted separately.
For Xiaohongshu specifically, always preserve the user’s unique ID found in their profile URL when viewed on a browser, which follows the format “user/profile/[unique ID]”. Users can change their display names, but this unique identifier remains constant, allowing you to track accounts over time even after name changes. This is critical for long-term investigations or when monitoring specific sources.
The unique ID of a user can be found in the profile URL on a browser. Source: Xiaohongshu
Xiaohongshu operates under the same legal and censorship constraints as all Chinese social media platforms, and researchers should approach it with appropriate caution. Content moderation is extensive: users who post about sensitive subjects risk having their content removed or their accounts suspended, and the platform is required to comply with government data requests. For researchers, this means the information you find represents only what has survived the censorship process.
That said, Xiaohongshu remains a remarkably rich resource for open-source research. Its strength lies precisely in its apolitical, lifestyle-oriented identity: while political discussion is suppressed, candid conversations about everyday life flourish. For journalists willing to invest in learning the platform’s rhythms, building Chinese-language search skills, and understanding its coded vocabularies, Xiaohongshu offers a window into how ordinary Chinese people talk among themselves – an area that remains largely untapped by international media.
Bellingcat is a non-profit and the ability to carry out our work is dependent on the kind support of individual donors. If you would like to support our work, you can do so here. You can also subscribe to our Patreon channel here. Subscribe to our Newsletter and follow us on Bluesky here, Instagram here, Reddit here and YouTube here.
IBM has agreed to settle a complaint from the US Justice Department around its initiatives to diversify its workforce and to encourage hiring of underrepresented groups, contrary to a presidential directive. The federal contractor also agreed to pay the government roughly $17 million.
The pressure from the Trump administration to eliminate workforce diversification efforts, typically known as DEI (Diversity, Equity, and Inclusion) programs, has persuaded many companies, including Meta, Google, Amazon, Salesforce, Intel, OpenAI, Tesla and Zoom, to publicly back away from those diversification efforts. A few companies, including Apple, Microsoft, Nvidia and Oracle, have held firm in favor of DEI, for the most part.
The government’s official position states that age, race, sexual preference, and gender should have zero impact on hiring decisions. Diversification proponents counter that workforce composition will stay stagnant unless explicit efforts are made to diversify.
Focus of settlement
The Justice Department settlement focused mostly on IBM’s role as a government contractor.
The government filing said IBM made “false claims” and “false statements” to the government regarding hiring practices in connection with IBM’s government contract work.
“As a federal contractor, IBM was required to comply with anti-discrimination requirements as set forth in Title VII of the Civil Rights Act of 1964,” the settlement said, adding that IBM “discriminated against employees during employment and applicants for employment because of race, color, national origin, or sex, and failed to treat employees during employment without regard to race, color, national origin, or sex.”
Beyond hiring practices, the government also opposed hiring goals that encouraged diversity, including “developing race and sex demographic goals for business units and taking race, color, national origin, or sex into account when making employment decisions to achieve progress towards those demographic goals” and using those same criteria to offer “certain training, partnerships, mentoring, leadership development programs, educational opportunities or resources, and/or similar opportunities only to certain employees.”
The agreement also said that the deal “is neither an admission of liability by IBM nor a concession by the United States that its claims are not well founded” and added that IBM agreed to the settlement “to avoid the delay, uncertainty, inconvenience and expense of protracted litigation.”
Acting US Attorney General Todd Blanche issued a statement saying, “racial discrimination is illegal, and government contractors cannot evade the law by repackaging it as DEI.”
IBM did not respond to an email seeking comment.
Companies can work around biases
Bryan Howard, the CEO of recruiting strategy consulting firm Peoplyst, said he would encourage enterprises to simply move their workforce diversification efforts earlier in the recruitment process.
“There’s a big difference between candidate pool and the selection process,” Howard said, suggesting that there are no federal rules limiting outreach choices. If, for example, a company wanted to increase workforce representation for a particular group, then the job notice should be focused on universities and other places where that group is well represented.
“Expand your pool and do not contract it. Fish in the ponds where those people are,” Howard said. “Increase diversity by simply recruiting from diverse sources.”
Howard also said the government position leverages last year’s US Supreme Court decision in Ames v. Ohio Department of Youth Services, where the court held that reverse discrimination is illegal.
Complicating diversification efforts today are two popular recruiting/hiring tools pushed by HR: Using genAI to filter a massive number of applicants and only present a small handful to the hiring managers to choose from; and referral programs in which employees are offered cash incentives if they recommend job candidates who are eventually hired.
AI’s bias is to seek job candidates whose profiles most closely resemble that of the current workforce. In other words, AI wants to learn everything it can about who the company has hired before, to help it determine the attributes to look for.
Referral programs, Howard said, also tend to attract people with the same characteristics as the existing workforce. Even though those referral hires tend to stay with the company longer, “if you have a population that is already skewed and that is the population recruiting, the existing bias will likely continue.”
Settlement could hurt recruitment efforts
Consultant Brian Levine, executive director of FormerGov, said it is difficult to interpret the settlement as anything other than opposing DEI efforts.
The US Justice Department, where Levine once worked as a federal prosecutor, ”has issued a multi-million dollar penalty for company policy that seemed to be intended to encourage diversity,” he said. “As with Anthropic, in this new world, sometimes organizations may be forced to choose between ‘the law’ as it is currently being interpreted by some, and a good faith effort to positively influence society, or at least to minimize societal harm.”
Levine said some enterprises may try to overcompensate to keep the current administration happy.
“Fearing financial penalties, some companies that work with the federal government will now choose to ensure their DEI program is fully dismantled,” Levine said. “Other companies may choose to cease working with the federal government and/or may choose to keep, or even double down, on their DEI program. If Anthropic is any indication, these latter companies may ultimately be rewarded in the market.”
Flavio Villanustre, CISO for the LexisNexis Risk Solutions Group, added that this settlement might end up hurting tech recruitment efforts.
“I think that this will force organizations to reframe their DEI programs to not upset the DOJ, which could have an impact on hiring of individuals in certain classes and could result in overall less diversity,” Villanustre said. “Diversity is an important part of building resilient, successful organizations, so this could have a broader impact than just the one at hiring time.”
If there is anything that annoys me more than a scammer, it’s companies that behave like one, while staying just on the right side of the law. They manage to linger and disappoint customers for years.
It’s also why sometimes people think that MalwarebytesScam Guard can be overly cautious when flagging websites. Some sites sit in a grey area where even seasoned researchers have to look twice to figure out whether something is an outright scam.
That’s exactly what happened here.
After receiving an anonymized report from a customer, I started an investigation into an email Scam Guard flagged as highly suspicious.
The email
The email came from the address anna@cosmosshift[.]org and promoted a service called Credit Resources Vault, urging recipients to click a button labelled Check Eligibility Now..
There are immediate red flags:
The sender domain (cosmosshift.org) has no clear connection to credit services or financial products. There is no “Cosmos Shift” financial institution.
The message creates urgency around credit approval, a classic social engineering pressure tactic.
It includes a physical address and an opt-out link which appear to be legitimate, but are also a common technique in phishing called legitimacy laundering.
Unlike most phishing emails, this one includes a personalized greeting using the recipient’s email address. Since the recipient says they’ve never interacted with the sender, this suggests their details may have come from a data broker or a past data breach.
The website paints a suspicious picture
Clicking the link leads to (yourcreditvault.com), a polished-looking site that appears to offer credit services.
Credit Resources landing page
But under the hood we found more red flags:
The website was built with Vite/React, a modern JavaScript framework more typical of startup side projects than regulated financial services.
References to bolt.new suggest the site may have been assembled using AI tools
There are no visible indicators of banking-grade security. The HTML source shows only a basic app shell with no indicators of financial-sector encryption infrastructure.
The branding (including the logo) looks hastily put together
The JavaScript bundle (index-B54Ghi53.js) behind the submission form is heavily obfuscated: a technique used by cybercriminals to hide where the submitted data is being sent.
None of this proves malicious intent on its own. But together, it paints a picture of something built quickly, and designed to collect data rather than deliver a robust financial service.
The form collects data, and $20/week
The biggest concern is the form, which collects an extraordinary amount of data for what’s presented as a basic credit eligibility check.
The application form
By monitoring network traffic during form submission, we were able to capture exactly what fields are transmitted:
Personal: first name, last name, email, phone
Address: street, city, province, postal code
Full banking details: bank name, institution number, transit number, account number
Tracking data tied to advertising campaigns
A drawn-on-screen signature, which gets uploaded to the owner’s Google Drive.
That’s far more than what’s needed for a credit eligibility check.
With those banking details alone, someone can set up fraudulent Pre-Authorized Debits (PADs). A PAD is a form of direct bank withdrawal used legitimately by billers, but can also be abused.
Enlarged screenshot of the box they want a checkmark in
And that’s exactly what appears to happen.
A small checkbox, paired with fine print, authorizes the company to withdraw $20 weekly per the PAD agreement the target just signed. This checkbox serves two purposes: it provides the operators with legal cover (“you agreed to it!”) and it weaponizes the very bank account details the form just collected.
Targeting the financially vulnerable
This campaign seems to deliberately target people with poor or limited credit history. The promise of “approval when others say no” is powerful, especially for people under financial pressure.
These are not random victims, but people targeted because their need makes them more likely to hand over sensitive information without scrutinizing the source.
The $20/week PAD charge (over $1,000 per year) can lead to overdrafts, fees, and further financial harm.
Where your data goes
Our network traffic analysis revealed a sophisticated, multi-service backend that uses individual components which all might be legitimate.
Supabase: Victim data is sent via POST request to a Supabase project:
POST https://bstvkdzfgpktokbiagsc.supabase.co/rest/v1/vault_memberships
Supabase is a legitimate, well-regarded cloud database platform with free tiers.
Brevo (formerly Sendinblue): This is a legitimate mass-email platform. Enrolling victims here means they can be targeted with follow-up campaigns indefinitely.
POST https://bstvkdzfgpktokbiagsc.supabase.co/functions/v1/add-to-brevo
Google Drive and Sheets: The signature data field includes a signature_drive_url, indicating victims’ handwritten signatures might get stored on Google Drive infrastructure. A google_sheets_synced field confirms that incoming victim records are mirrored to a live Google Sheet, giving the operators a real-time dashboard of everyone that submitted a form.
Individually, these are trusted platforms. Together, they form a system designed to:
Collect sensitive personal and banking data
Store it in accessible formats
Add users to ongoing marketing or even phishing campaigns
In other words, submitting the form doesn’t just risk your bank account, but may also put you on a list of people likely to be targeted again.
Infrastructure
The infrastructure behind this campaign spans multiple domains:
cosmosshift[.]org (email sender)
yourcreditvault[.]com (landing page).
yourscore[.]ca (redirect after submitting the form)
creditresources[.]ca (follow-up email that included the phone number 1-833-427-1562)
debtlesscredit[.]com (another website using that same phone number)
Using multiple domains and having one telephone number associated with more than one domain raising red flags about the legitimacy of the company.
So is this a scam?
That depends on how you define it.
While this may not meet the strict legal definition of a scam, we can see why Scam Guard flagged it, as many of the tactics used here are also seen in phishing emails and on scam websites.
The evidence suggests these sites are operated by real companies, but they sit firmly in a grey area. On one hand, they have corporate registrations, public websites, and apparently even some satisfied customers. On the other, the business model—charging recurring fees for credit or debt “programs”—has generated a steady stream of consumer complaints and scam accusations. The use of multiple domains (Credit Resources, Debtless Credit, Your Credit Vault) also points to a lead-generation strategy that’s common in the debt-relief space.
It’s also likely that these companies rely on purchased mailing lists and may have found our customer’s email address on a list of likely candidates. Unfortunately, lists like these are bought and sold by legitimate marketers and cybercriminals alike.
We have reached out to the sender of the email and Credit Resources for comment but had not received an answer at the time of publication.
What do cybercriminals know about you?
Use Malwarebytes’ free Digital Footprint scan to see whether your personal information has been exposed online.
Access to open source visuals of the current Iran conflict, which has spread to many parts of the Middle East, continues to be sporadic. Videos and photos from within Iran trickle out on social media as the Iranian internet blackout hinders the flow of digital communication.
In past conflicts, satellite imagery has provided a vital overview of potential damage to both military and civilian infrastructure, especially when there are digital black spots or obstacles to on-the-ground reporting. But imagery from commercial providers is becomingincreasinglyrestricted, leaving even those who have access to the most expensive imagery in the dark.
Shortly after the war in Gaza began in 2023, Bellingcat introduced a free tool authored by University College London lecturer and Bellingcat contributor, Ollie Ballinger, that was able to estimate the number of damaged buildings in a given area. This helped monitor and map the scale of destruction across the territory as Israel’s military operation progressed.
Bellingcat is now introducing an updated version of the open source tool — called the Iran Conflict Damage Proxy Map — focused on destruction in Iran and the wider Gulf region.
The tool works by conducting a statistical test on Synthetic Aperture Radar (SAR) imagery captured by the Sentinel-1 satellite which is part of the Copernicus mission developed and operated by the European Space Agency. SAR sends pulses of microwaves at the earth’s surface and uses their echo to capture textural information about what it detects.
The SAR data for the geographic area covered by the tool is put through the Pixel-Wise T-Test (PWTT) damage detection algorithm, which was also developed by Ollie Ballinger. It takes a reference period of one year’s worth of SAR imagery before the onset of the war and calculates a “normal” range within which 99% of the observations fall. It then conducts the same process for imagery in an inference period following the onset of the war, and compares it to the reference period. The core idea is that if a building has become damaged since the beginning of the war, then the “echo” (called backscatter) from that pixel will be consistently outside of the normal range of values for that particular area. Investigators can then further probe potential damage around this highlighted area.
The plot below shows how the process was applied to Gaza and several Syrian, Iraqi and Ukrainian cities. The bars represent the weekly total number of clashes in each place, sourced from the Armed Conflict Location Event (ACLED) dataset. The pre-war reference periods are shaded in blue, spanning one year before the onset of each conflict. The one month inference periods after the respective conflicts began are shaded in orange. The blue and orange areas are what the tool compares.
The plot below shows an area with a number of warehouses in Tehran’s southwest. Some of the buildings show clear damage in optical Sentinel-2 imagery (something that has to be accessed outside of the tool via the Copernicus Browser).
Clicking on the map within the tool generates a chart displaying that pixel’s historical backscatter; the red dotted lines denote a range within which 99% of the pre-war backscatter values fall. In this example, we can see that from March 14 onwards, the backscatter values over this warehouse begin to consistently fall outside of their historical normal range. This could signal that damage has been detected in the area.
Two important aspects of this workflow are that it utilises free and fully open access satellite data, as opposed to commercial satellite services; the second is that it overcomes some key limitations of AI in this domain, the most serious of which is called overfitting. This is where a model trained in one area is deployed in a new unseen area, and fails to generalise. Because we’re only ever comparing each pixel against its own historical baseline, we don’t run into that problem.
Accuracy
The PWTT has been published in a scientific journal after two years of review. Its accuracy was assessed using an original dataset of over two million building footprints labeled by the United Nations, spanning 30 cities across Gaza, Ukraine, Sudan, Syria, and Iraq. Despite being simple and lightweight, the algorithm has been recorded achieving building-level accuracy statistics (AUC=0.87 in the full sample) rivaling state of the art methods that use deep learning and high resolution imagery. The plot below compares building-level predictions from the PWTT against the UN damage annotations in Hostomel, Ukraine. True positives (PWTT and United Nations agree on damage) are shown in red, true negatives are shown in green, false positives in orange, and false negatives in purple. The graphic shows the accuracy of the tool, while also emphasising that further checks on what it highlights should be conducted to draw full conclusions.
It is important to note that just because the tool may show a high probability of a building or buildings being damaged or destroyed, that doesn’t make it definite.
It is best to check with any other available imagery — either open source photos and videos that’ve been geolocated by a group such as Geoconfirmed or Sentinel-2 as well as other commercial satellite imagery if it’s up-to-date for the area. At time of publication, Sentinel-2 satellite imagery still offers coverage over the area that the tool focuses on. Other commercial satellite imagery providers have limited their coverage.
What the tool excels at is highlighting and narrowing down areas so that further corroboration or further confirmation can be sought.
Testing the Tool
Using the Iran Conflict Damage Proxy Map, we can spot some of the larger areas of potential damage or destruction that have occurred since the Iran war started.
Starting from a zoomed-out view of Tehran, there are a few spots that appear with large clusters of high damage probability. Cross-referencing these locations with open source map data from platforms like OpenStreetMap or Wikimapia, we can start finding sites that would make for likely targets – such as military sites.
One example of a potentially damaged site visible in the tool is the Valiasr Barracks in central Tehran, which was struck in the first week of the war. By going to the Copernicus Browser and reviewing the area with optical Sentinel-2 imagery, we can see clear indications of damage at the barracks.
IRGC Valiasr Barracks in Tehran:
Below: Sentinel-2 comparison of February 20 and March 17.
A large Islamic Revolutionary Guard Corps (IRGC) compound near Isfahan is another example of military infrastructure that is readily visible in both the Iran Conflict Damage Proxy Map as well as Sentinel-2 imagery.
IRGC Ashura Garrison in Isfahan:
Below: Sentinel-2 comparison of February 20 and March 17.
Air bases have also been a frequent target for U.S.-Israeli strikes in Iran. The Fath Air Base just outside of Tehran, near the city of Karaj, shows the signature of potential damage when using the tool. Checking Sentinel-2 imagery shows damage to multiple large buildings on the northern side of the base.
Fath Air Base in Karaj:
Below: Sentinel-2 comparison of February 20 and March 17.
Khojir Missile Production Complex outside of Tehran:
Below: Sentinel-2 comparison of February 20 and March 17.
Usage in the Gulf Region
While useful for providing a sense of damaged areas in Iran, the Iran Conflict Damage Proxy Map can also be used to see damage outsideof Iran, particularly at sites in the region which Iran has been targeting with drones and missiles.
In the below example at Al Udeid Air Base in Qatar, which hosts U.S. Central Command’s Combined Air Operations Center, there is a notable indication of damage over a warehouse-like building at 25.115647, 51.333125. Checking the same location in Sentinel-2 imagery shows that there does appear to be damage at that warehouse — represented by a large blackened area on the white roof. According to Qatar’s Ministry of Defense, at least one Iranian ballistic missile struck the base in early March.
Al Udeid Air Base in Qatar:
Below: Sentinel-2 comparison of February 22 and March 14.
Civilian sites struck by Iranian drones or missiles are also visible in the tool — though the damage has to be fairly large in order to be picked up. Something like damage to the sides of high rise buildings from an Iranian drone attack doesn’t readily appear in the tool. Sites that do appear are places like oil refineries, such as a fuel tank at Fujairah port in the United Arab Emirates.
Fuel tanks at Fujairah Port, UAE:
Below: Sentinel-2 comparison of March 3 and March 28.
Accessing the Tool
It’s important to keep in mind that the data for the Iran Conflict Damage Proxy Map is updated approximately one or two times per week as new satellite data is collected by the Sentinel-1 satellite, so it’s not meant to be a representation of real-time damage to buildings.
Still, it can be useful for researchers to quickly gain an overview of damage throughout Iran and the Gulf where suspected strikes may have taken place and when there is no other open source information available.
You can access the Iran Conflict Damage Proxy Map here.
Similar tools using the same methodology to assess damage in Ukraine following Russia’s full-scale invasion and Turkey following the 2023 earthquake can be found here. The Gaza Damage Proxy Map can be found here.
Bellingcat’s Logan Williams contributed to this report.
This article was updated on April 7, 2026, to note that Sentinel-1 and Sentinel-2 are part of the Copernicus mission developed and operated by the European Space Agency.
Bellingcat is a non-profit and the ability to carry out our work is dependent on the kind support of individual donors. If you would like to support our work, you can do so here. You can also subscribe to our Patreon channel here. Subscribe to our Newsletter and follow us on Bluesky here, Instagram here, Reddit here and YouTube here.
Since launching the military campaign against Iran on Feb. 28, the US and Israel have dropped thousands of bombs on the country. Videos of explosions have become a source of misinformation and misunderstanding, with many of the strikes incorrectly attributed to a particular munition and many explosive effects – seen in footage and images – falsely attributed to “mystery” or illegal weapons.
Take the below post that initially suggested (although it said more analysis was required) that the US may have used a nuclear weapon in Iran, an outlandish and clearly incorrect claim that experts Bellingcat spoke to had little time for.
The archived video from the post below. You can find the full post, which was set to private after we published the guide, here.
IMPORTANT UPDATE AND NOTE: The following is not a complete assessment and I require more data to verify first use. This is a surface level observation but it must be noted.
The US used what appears to be, without additional details, a nuclear weapon on Iran delivered by a… pic.twitter.com/7ucJNdGyNi
Thepost, set to private after the publication of this guide, appeared to suggest that a nuclear explosion happened in Iran. Source: X/cirnosad
“The video does not show a nuclear explosion—something that I am astonished even needs to be clarified,” Dr NR Jenzen-Jones, Director of Armament Research Services, a weapons intelligence consultancy, told Bellingcat.
“Certain types of explosive munitions, such as those working on the fuel-air explosive (FAE) and thermobaric principles, are particularly poorly understood by non-specialists. As a result, these and other types of munitions are routinely misidentified,” Jenzen-Jones said.
Support Bellingcat
Your donations directly contribute to our ability to publish groundbreaking investigations and uncover wrongdoing around the world.
Often posts about explosives are incorrect or inaccurate because of a lack of knowledge about how explosives work, but in other cases misinterpretations are deliberate. Joe Dyke, director of programmes at Airwars, told Bellingcat that deliberate disinformation that shifts responsibility of a strike is the most common they see, with posts often sharing flimsy but “scientific sounding” analysis.
Better understanding explosives can make it easier to identify misinformation surrounding explosions.
This guide explains explosives, their characteristics and the impact they have on people and infrastructure. We highlight the differences between thermobaric and Dense Inert Metal Explosives (DIME), two types of explosives that are frequently the subject of misinformation.
What Are Explosives?
Explosives are energetic materials capable of causing death and destruction through a rapid release of energy. The blast creates pressure waves emanating from the epicentre. These waves can directly kill or injure people and shatter objects into lethal fragments.
High explosives are typically used in warheads and shells; they differ from low explosives which are often used in rocket propellants. The supersonic speed of the explosive reaction- classified as detonation- also separates the two kinds of explosives. During detonation, temperatures can rise above 3,000 °C, but only briefly and very close to the reaction zone, Dr Sabrina Wahler, a Postdoctoral Scholar at the California Institute of Technology focusing on research of detonation products told Bellingcat.
Graphic showing a high explosive with a detonator (initiator or blasting cap) before and after the detonation begins. The chemical reaction zone is shown as the explosive detonates. Source: Justin Baird for Bellingcat.
The detonation creates a shockwave, which is a visible wave or bubble in high speed videos. The shockwave impacts people and objects before the sound of the blast can be heard.
Visible shockwave emanating from the blast, ahead of the fireball or blast wind, in screenshots showing a surface explosion. Source: Defense Threat Reduction Agency (DTRA) Counter-WMD Test Support Division (CXT) via Lawrence Livermore National Lab.
The shockwave is the result of the pressure pushing air away from the blast in the positive phase. When the air rushes back in the negative phase, it creates a suction effect.
The shockwave arrival time, combined with a known distance, has been used to estimate the explosive weight of blasts, including the Beirut explosion in 2020.
Reactive materials, such as aluminium powder, are often added to explosives to improve performance. These metals react with the gaseous products from the detonation, resulting in increased energy output, Jacqueline Akhavan, a Professor of Explosive Chemistry at Cranfield University, told Bellingcat.
Ammonium nitrate based Tannerite exploding targets with various amounts of aluminum powder added. Exploding targets are popular and widely available in the United States. Military ordnance also uses similar aluminised explosive compositions. Source: United States Department of Agriculture.
Sometimes, reactive metals such as aluminium from the explosive composition can be seen burning outside the fireball, indicating an explosive with reactive metal.
Photo of ammonium nitrate with aluminium powder exploding. Burning aluminium powder can be seen outside the fireball. Annotation by Bellingcat to indicate some of the burning powder. Source: United States Department of Agriculture.
The size of a fireball does not necessarily indicate the blast’s power. In movies and airshows, a “Hollywood shot” involves igniting large amounts of gasoline with small amounts of explosives, creating spectacular fireballs with minimal pressure.
Thermobaric, and dense inert metal explosives (DIME), are other types of explosive compositions where metals are added to modify specific effects.
Thermobaric Explosives
In January 2024, after an attack in Gaza, social media posts appeared claiming that thermobaric explosives “literally sucks the air out of the children’s lungs and causes them to internally explode”. According to an article by Dr Rachel Lance, a biomedical engineer specialising in patterns of injury and trauma from explosions “there is no evidence that thermobarics pull the air out of the lungs”.
There were also claims that thermobaric weapons incinerate people. According to a report by the Armament Research Services, the effects of this type of explosion “are of the same nature as those expected from a conventional high explosive”. The only difference is that the duration of each effect is likely to be longer from a few milliseconds to tens of milliseconds and in a pressure wave with a lower peak.
This occurs because thermobaric explosives add a significant amount of fuel or reactive metals to the explosive composition. Some of the fuel burns after detonation. These munitions are effective against cave or bunker systems, as the pressure wave can travel further throughout the structure.
Visual differences can indicate the types of explosives used. Even within the same category, explosives may appear different because of variations in chemical composition, conditions where the explosion occurs, and video quality.
TÜBİTAK SAGE’den yerli termobarik patlayıcıda yeni bir adım daha!
Kapalı alanlarda yüksek darbe ve sıcaklık etkinliğine sahip yeni bir termobarik patlayıcı
TENDÜREK’ten sonra KOR ile geleneksel patlayıcılara göre 4 kat daha yüksek sıcaklık etkinliği pic.twitter.com/N4yZ8YvMi9
Fuel-air explosives are similar to thermobaric explosives, but function differently. Both are volumetric weapons, but fuel-air explosives disperse a cloud of fuel, then the explosion occurs.
A video showing a test of a US fuel-air explosive munition. Source: jaglavaksoldier.
Dense Inert Metal Explosives (DIME) are typically used in munitions intended to reduce civilian harm. Non-reactive metals, like tungsten, added to the explosives reduce the area impacted by the blast, but increase the power. Often munitions filled with DIME replace steel casing with carbon fibre to reduce fragmentation.
Photo of a Dense Inert Metal Explosive (DIME) test by the US Air Force Research Laboratory (AFRL). Non-reactive metal particulates can be seen at the edges of the fireball.Annotation by Bellingcat. Source: US AFRL, 2006.
Some sources refer to DIME as a multiphase blast explosive, a term that also covers some explosives with reactive metals. Photos from testing show mannequins near the blast coated in tungsten powder.
Mannequin coated in tungsten powder following the testing of a GBU-39 A/B FLM, a DIME filled variant of the GBU-39 bomb. Source: ITEA Journal via DTIC.
Some claims of DIME use in Gaza mention the presence of powder or microscopic shrapnel found on victims. “Peppering” and “tattooing” are mentioned (warning: graphic content) as common injuries in blast victims, where the explosion propels small debris like sand into the body, along with fragments of various sizes.
There is currently no conclusive evidence that militaries aside from the US have used DIME in combat.
Clues From Clouds
Clouds, and the colours of the smoke can provide clues about the type of explosive. However, chemical composition, environmental conditions, and location can all affect how explosions appear.
Clouds
This footage, originally posted on social media in November 2025, shows an explosion in Gaza.
The Israeli army launched thermobaric and pressure bombs, supplied by the United States, on Gaza. These bombs, which burn at a temperature of 3,500 degrees Celsius, are capable of killing thousands in seconds, leaving no trace. pic.twitter.com/pZhoIfsazP
Video of an explosion in Gaza, falsely attributed as a thermobaric weapon. Source: X/@Eng_china5.
The visible cloud in the video is a condensation or Wilson cloud, caused by an explosive shockwave interacting with humid air. This same effect is visible in videos of the Beirut explosion in 2020, when ammonium nitrate exploded at the port after a fire.
Video of the 2020 Beirut ammonium nitrate explosion. Source: X/Borzou Daragahi.
Smoke colours
Colours in the smoke of an explosion can help identify the gases, which in turn can help identify the explosive material, Dr Rachel Lance told Bellingcat. “Yellow, orange, and red tones each indicate the presence of specific chemicals.”
Black smoke means “the bomb produced a lot of fire and inefficiency, because materials burned instead of detonated, and was probably a homemade or improvised explosive”. White or light grey smoke indicates “an efficient detonation, and that tells us it was a pure, high-grade material inside,” Lance said.
Some munitions, like cruise or ballistic missiles, may have efficient high explosives, as well as low explosive propellants or fuel. The area targeted, such as buildings, may lead to dust or debris that obscure the gases created by the explosion.
In some cases, multiple bright fireballs are launched into the sky, accompanied by a rapid humming or throbbing sound and bright flashes. This typically happens when solid-fuel rocket motors, like those in air defence or ballistic missiles, are burning or exploding.
Major secondary explosions after a U.S. airstrike in the vicinity of Higuerote Airport in Venezuela tonight. pic.twitter.com/NrFOVj9IfM
Qom today looks like it was hit by a GBU 57 bunker buster.
The GBU 57 Massive Ordnance Penetrator is a 30,000 pound bunker busting bomb designed to penetrate deep underground before detonating. pic.twitter.com/d4bGJ19nQb
Video shared by a user claiming this video shows the use of a GBU-57 “Massive Ordnance Penetrator”. A now-suspended user claimed the video showed the “Mother of All Bombs”. Source: Osint613.
Blast Effects on People
Misinformation regarding blast effects on people might lead to reports of harm to be wrongly dismissed or false claims about mystery weapons to spread.
In February 2026, claims of “vaporisation” or disintegration of people due to thermobaric weapon explosions appeared online. Days later, counterclaims argued that explosives can’t “disintegrate” people and thermal effects were not responsible.
According to multiple studies, even less powerful explosives can cause disintegration. When explosions occur in enclosed spaces, such as inside a building, they reflect shock waves, leading to increased blast effects.
The effects of the shock wave on some structures can be seen in the first part of this video. Source: Canadian Armed Forces.
Blast injuries are generally classified into four categories, based on what mechanism is causing the injuries.
The primary effect, the blast itself, “puts tremendous strains on human tissue, causing them to rip and tear, both internally and externally, so massive internal bleeding can occur,” Brian Castner, a weapons investigator for Amnesty International, told Bellingcat.
Primary injuries can lead to a variety of symptoms, including vertigo, vomiting blood, and bleeding from the ears. A viral post shared by the White House Press Secretary claimed to be firsthand testimony from a Venezuelan security guard following US strikes in Venezuela. The post alleged that the US used a sonic weapon without any supporting evidence, and the symptoms described are typical of primary blast injuries.
The secondary effect results from the metal fragments of the munition. Some weapons are specifically designed to break into uniform small pieces, Castner said. “Even small fragments, the size of a bullet, can break a bone, since the metal is flying through the air so quickly,” the weapons investigator explained.
Even single fragments can injure or kill people hundreds of metres away from a blast. People close to it may be largely disintegrated, often described (warning: graphic content) as “total body disruption” in Forensic Medicine.
A non-graphic video showing the destruction that explosives are capable of inflicting on various materials. Source: Ballistic High-Speed.
“Combined, these blast and fragmentary effects can do horrific damage to the human body, and if a person is close enough to a large munitions detonation, leave little trace they ever existed,” Castner told Bellingcat.
A recent Bellingcat investigation into three specific US-made munitions used in Gaza found videos showing small pieces of human bodies consistent with total body disruption, at several different strikes within the dataset.
Screenshot from a video showing one area hit by a GBU-39 bomb at Khadija School, Gaza in July 2024. A separate graphic video shows a boy in this area collecting a small part of a person. Source: X/Eye on Palestine.
Explosions can also cause burns or thermal injuries. Temperature is not the most relevant factor, because “by the time a human body is exposed to the temperatures of a burning explosive, people will have severe trauma and death,” Dr Lance told Bellingcat.
In many real-world cases “the blast pressure reaches farther than the thermal flash,” Dr Sabrina Wahler said. “The thermal danger becomes much larger and longer lasting when the explosion occurs in a confined space, when the formulation supports continued burning with air, or when the detonation triggers secondary fires that keep generating heat well after the initial blast,” she noted.
Flash burns are often seen on exposed parts of the body close to the blast (warning: graphic content). Explosions that start fires or contain incendiary materials can result in severe burns.
Are These Explosives Legal?
Misinformation often raises questions about legality, with false claims that specific weapons are inherently illegal or misrepresenting how they work. This is one of the reasons that nations conduct legal reviews of new weapons, Michael Meier, a former Senior Advisor to the Army Judge Advocate General for Law of War, and current Adjunct Professor at Georgetown University Law Center, told Bellingcat.
Subscribe to the Bellingcat newsletter
Subscribe to our newsletter for first access to our published content and events that our staff and contributors are involved with, including interviews and training workshops.
Thermobarics and DIME are legal if their use complies with specific principles of international humanitarian law (IHL) and the law of armed conflict (LOAC), such as proportionate and discriminate use, experts told Bellingcat.
“Even lawful weapons can be used in an unlawful manner”, Michael Meier said. One example is when they are directed against civilians or when they are used in a manner that breaches the principles of distinction or proportionality, he explained.
“The law’s ability to prevent harm is constrained by the compromises between military necessity and humanity made in its creation,” Dr Arthur van Coller, Professor of International Humanitarian Law at the STADIO Higher Education and a legal expert on thermobaric explosives, told Bellingcat.
“As a result, weapons that cause immense destruction may remain lawful (even nuclear weapons) if they fit within legal definitions, even when their humanitarian impact is severe,” van Coller explained.
Bellingcat is a non-profit and the ability to carry out our work is dependent on the kind support of individual donors. If you would like to support our work, you can do so here. You can also subscribe to our Patreon channel here. Subscribe to our Newsletter and follow us on Bluesky here, Instagram here, Reddit here and YouTube here.
As tensions linked to the ongoing West Asia conflict continue to shape the geopolitical environment, India’s technology industry body NASSCOM has urged member companies to remain alert and strengthen operational preparedness. The NASSCOM advisory highlights the need for heightened vigilance across business continuity and cybersecurity frameworks amid developments in the Middle East.The Nasscom advisory states that while business operations for companies remain stable at present, organizations are proactively reassessing contingency plans. Firms are reviewing operational safeguards and resilience measures to minimize potential disruption if the West Asia conflict in the Middle East escalates further.
The official Nasscom advisory, titled “Strengthening Operational and Cyber Resilience Amid Evolving Middle East Situation,” outlines a set of measures companies should implement in response to the geopolitical developments linked to the West Asia conflict.According to the advisory, organizations should ensure their business continuity frameworks are fully prepared to address potential disruptions across the Middle East. Even though services are currently functioning normally, the advisory stresses that companies must be ready to respond quickly if the situation deteriorates.The advisory notes, “Nasscom Advisory: Strengthening Operational and Cyber Resilience Amid Evolving Middle East Situation. Considering the geopolitical situation in the Middle East, Nasscom has issued another advisory to member companies, urging heightened vigilance and preparedness across business continuity and cybersecurity frameworks.”
Companies Reviewing Business Continuity Plans
One of the key recommendations in the Nasscom advisory relates to the activation and review of business continuity plans. Companies with operations or exposure to the Middle East are examining contingency frameworks to ensure operational stability if the West Asia conflict disrupts regional infrastructure or logistics.These contingency measures are intended to help maintain uninterrupted service delivery even if regional instability affects normal operations.
Employee Safety Prioritized as Middle East Tensions Persist
The Nasscom advisory also stresses the importance of employee safety. Companies have been asked to prioritize the well-being of staff members located in areas affected by the West Asia conflict.Many organizations are enabling remote work arrangements for employees based in impacted geographies across the Middle East. Firms are also closely monitoring the situation to ensure the safety of their workforce.Another focus area highlighted in the Nasscom advisory involves strengthening technology infrastructure resilience. Companies are assessing alternative routing options for cloud infrastructure and data centers located in or connected to the Middle East.These steps aim to protect critical systems and ensure that services remain operational even if regional disruptions linked to the West Asia conflict affect connectivity or infrastructure.
Travel Advisories Issued Due to West Asia Conflict
Given that the Middle East serves as a major global transit hub, the Nasscom advisory recommends limiting non-essential travel through the region. Companies have been advised to explore alternative transit routes where possible to avoid potential disruptions arising from the West Asia conflict.Employees are being encouraged to postpone or reconsider travel plans unless necessary.The Nasscom advisory also calls on companies to maintain proactive communication with customers. Firms are engaging with clients to provide updates about preparedness measures and reassure them about service continuity despite uncertainties linked to the West Asia conflict.Maintaining transparent communication, the advisory notes can help minimise concerns among clients with operations tied to the Middle East.
Cybersecurity Risks Rise During Geopolitical Tensions
The Nasscom advisory warns that geopolitical instability, including the ongoing West Asia conflict, often leads to an increase in coordinated cyber threats, disinformation campaigns, and attacks targeting critical infrastructure. To address these risks, organizations have been asked to treat several cybersecurity actions as immediate priorities.These include rotating credentials across the organization and applying patches for critical Common Vulnerabilities and Exposures (CVEs). The advisory also recommends enforcing multi-factor authentication across all external access paths, such as VPNs, RDP, SSH, and cloud administration systems. Implementing conditional access controls can help counter token theft and adversary-in-the-middle attacks.
Supply Chain and DDoS Readiness Highlighted
The Nasscom advisory further advises companies to conduct thorough audits of third-party vendors, especially those with exposure to the Middle East. According to the advisory, a single compromised vendor could potentially trigger disruptions across the broader industry supply chain.Companies have also been urged to prepare for potential distributed denial-of-service (DDoS) attacks by coordinating with internet service providers and cloud partners to ensure adequate mitigation capacity.To strengthen resilience, the Nasscom advisory recommends maintaining offline and immutable backups for critical systems such as industrial control systems, operational technology environments, core banking platforms, and healthcare infrastructure.Employee awareness is also considered a key line of defense. Organizations are being encouraged to conduct training sessions to help staff recognize social engineering attempts that may exploit narratives around the West Asia conflict or fake government alerts.
Flight tracking data is an important tool in open source research, but with 100,000 daily flights, it can be difficult to contextualise what a particular aircraft’s movements indicate.
Bellingcat has developed a tool called Turnstone to make it easier to visualise historical trends in flight data and spot unusual patterns. It also allows users to filter by parameters such as aircraft type or a geographic region of interest.
Source: ZUMA Press Wire via Reuters Connect; overlays of Turnstone by Bellingcat
This tool primarily uses Automatic Dependent Surveillance–Broadcast (ADS-B) data, the technology that enables open source investigators and enthusiasts to track flights.
Most aircraft are equipped with transmitters that broadcast ADS-B data to comply with global aviation regulations, though regulations vary by jurisdiction, and military aircraft might not always transmit. ADS-B data includes information about an aircraft’s identity and type, as well as its precise position, speed and altitude.
Popular flight-tracking websites such as Flightradar24 and ADS-B Exchange typically display historical data for a particular time or aircraft. However, Turnstone aggregates ADS-B data for multiple aircraft over time, and allows users to search for flights across two areas of interest at once. These features provide additional context for open source investigators to better understand flight behaviour.
Watch the video for a demonstration of how the tool works, using the example of Black Hawk helicopter patrols near one of the borders between the US and Canada:
You can view Turnstone’s source code and information about hosting it yourself on Bellingcat’s GitHub.
We also have a web-based instance of the tool that journalists and academics can access. Due to data hosting and processing costs, we can only grant access on a selective basis. If you would like to apply, please fill in this form. Priority will be given to researchers conducting open source investigations aligned with Bellingcat’s goals.
Read on for more examples of how Turnstone can be used for investigations, as well as some limitations of the tool.
Spotting Unusually High US Tanker Activity Before Iran Strikes
Flight data before both the June 2025 and February 2026 strikes showed a large number of American aerial tankers leaving the US and crossing the Atlantic towards Iran. Aerial tankers such as the KC-135 and KC-46A can refuel military aircraft in-flight, making them essential for most long-range combat missions.
With Turnstone, it is possible to interrogate the baseline level of movement and see how unusual this activity is.
To do this, three filters are set on the search: a geographic region of interest, set to the North Atlantic, a filter on the aircraft type, to search only for tankers, and a filter on the aircraft heading, to search only for eastbound traffic.
Filtering a search by aircraft type, region of interest, and heading range that captures eastbound traffic. Source: Turnstone/Bellingcat
[Note: For the aircraft category designations, Bellingcat used a custom-prompted large language model (LLM), Claude Sonnet 4.0, to assign a category label using aircraft type code data. There may be some inaccuracies in the classifications, as LLMs are prone to hallucinations. We discuss this further in the “Limitations of the Data” section of this piece.]
This search finds over 40,000 aircraft locations that match these filter queries. However, a look at the summary table shows that this data includes non-American tankers as well.
Results from a filtered search, showing tankers owned by the French Air Force and the United States Air Force. Source: Turnstone/Bellingcat
We can filter this data to include only aircraft associated with the US by typing “United States” into the search box in the table. Note that ownership data is not 100 percent accurate – it may be out of date, especially for privately owned aircraft, and new aircraft might not have any data at all. However, especially when comparing trends over time or searching for research leads, this data can still be useful.
The graph of matching detections over time now shows that while there is a large baseline level of transatlantic movement for American tankers, there was a notably higher number of American tankers heading eastward from the US across the North Atlantic detected in the week of June 15, 2025, as well as in the last two weeks of February 2026.
The weekly graph view on Turnstone shows a noticeable spike in eastbound American tankers crossing the North Atlantic per day from June 15 to June 21, 2025 and from Feb. 15 to Feb. 28, 2026. Source: Turnstone/Bellingcat
Altering the search query to look for westbound tankers instead of eastbound tankers, we can also see a larger-than-normal number of American tankers heading in the direction of the US during the week of July 13, 2025, bookending the summer airstrikes in Iran. No such return movement is yet visible following the recent strikes.
The number of American tankers heading westward across the North Atlantic, towards the US, appeared higher than usual from July 13 to July 19, 2025. Source: Turnstone/Bellingcat
Finding Deportation Flights to Guantanamo Bay
Turnstone also allows you to search for aircraft detected across two different geographic regions of interest (ROIs).
Shortly after US President Donald Trump announced the opening of a migrant detention centre at Guantanamo Bay in Cuba at the end of January 2025, the US military reportedly flew about 100 immigrants from El Paso, Texas, to the US naval base to await deportation. By selecting the areas around both Guantanamo Bay and El Paso, we can find flights between these cities that broadcast ADS-B data.
When you select two regions of interest, a filter for the time difference between them also appears. Source: Turnstone/Bellingcat
When two ROIs are selected, you can also enter the maximum time difference between an aircraft’s presence in the two regions.
In the example below, we have entered 36,000 seconds (10 hours), meaning that the aircraft must have crossed through both regions within 10 hours of each other. We have also set the maximum altitude to 15,000 ft (4.57km) to look for planes landing and taking off. This limit is set relatively high as there are no ADS-B receivers at Guantanamo Bay, and only the initial approach is captured.
Search panel settings for finding aircraft that have been in both Guantanamo Bay and El Paso, Texas, with inputs under the “Maximum Altitude” and “Maximum Time Difference” fields, and selection areas drawn around both areas on the map (in blue). Source: Turnstone/Bellingcat
After five months with no tracked flights between the two locations, this search shows an uptick in flights in the few months from February 2025.
The results from Turnstone come with a bar graph that shows the average aircraft per day by week or by month, which can be further filtered by aircraft hex code (the unique identifier for specific aircraft) or the aircraft type code. Source: Turnstone/Bellingcat
Results for this search query from Jan. 26, 2026, include several passenger aircraft operated by companies known to run deportation flights from the US, such as Omni Air International and Global Crossing Airlines.
Results from a search of flights of up to 10 hours between Guantanamo Bay and El Paso, Texas, conducted on Jan. 26, 2026 show flights owned by Omni Air International and Global Crossing Airlines, both carriers known to operate deportation flights. Source: Turnstone/Bellingcat
Mapping US Customs and Border Patrol Aircraft
Turnstone also supports uploading a list of International Civil Aviation Organization (ICAO) addresses, informally referred to as aircraft “hex codes”, which are unique identifiers assigned to aircraft by ICAO member states.
For example, to explore data related to Department of Homeland Security (DHS) activity and look for patterns related to the US immigration enforcement and border security operations, we can copy and paste the hex codes from a list of US Customs and Border Patrol (CBP) aircraft (used across the DHS) into a text file, and upload that file. Now, we can search among these aircraft with any of the same filters demonstrated in the earlier case studies. Alternatively, we can also deselect all of the filters to track the most recent activity by those aircraft.
Let’s try that with the CBP list, this time with a very large number of results selected: 500,000. Note that increasing the number of results increases the search time and requires more browser memory.
With the list of hex codes provided, the search interface shows “216 hex codes loaded”. No other filters have been selected and the result limit is set to 500,000. Source: Turnstone/Bellingcat
When many points are displayed, the map is simplified, and hover features are disabled.
The results map shows a large number of CBP flights over the US without any filters, from a search of historical data on Jan. 26, 2026. Source: Turnstone/Bellingcat
By the California-Mexico border, Eurocopter AS350 (type “AS50”) can be seen on frequent patrol missions over the land border. Over the Pacific Ocean, Black Hawk helicopters (“H60”) can be seen patrolling the international waters boundary off the Mexican coast, while CBP Dash-8s (“DH8B” and “DH8C”) travel farther offshore.
Zooming in on the area near the California-Mexico border shows an obvious concentration of certain aircraft types in this search of historical data on Jan. 26. 2026. Source: Turnstone/Bellingcat
In contrast, by the Minnesota-Canada border, CBP makes more active use of one of its MQ-9 Reaper drones, as seen from the prevalence of red dots that correspond to “Q9”, the type code of these drones, in the results map.
The dots around the Minnesota-Canada border mainly show activity by MQ-9 Reaper drones in this search of historical data on Jan. 26, 2026. Source: Turnstone/Bellingcat
Let’s take a closer look at these drones by filtering the results with the text “Q9”. Now the displayed aircraft only include MQ-9 Reaper drones.
Results can be filtered by typing into the search field on the top right of the “Aircraft Summary” table. Source: Turnstone/Bellingcat
Now we can take a closer look at the patterns of drones, specifically among the search results.
Left: A very large number of MQ-9 Reaper flights south of San Angelo, Texas. They are coloured by altitude, with green symbols indicating lower flights and red showing those at higher altitudes. Right: The flight pattern of a known Aug. 13, 2025 MQ-9 Reaper mission into Mexico, as shown on Turnstone. Source: Turnstone/Bellingcat
While overall CBP flight activity was relatively stable, drone flights seem to have intensified in December 2025 and January 2026, compared with previous weeks.
The bar graph by week shows a higher average number of MQ-9 Reaper drone flights in December 2025 and January 2026 than in previous weeks. Source: Turnstone/Bellingcat
Limitations of the Data
In open source research, it is always important to be alert to the limitations of a particular data source, and ADS-B data is no exception.
For example, some aircraft do not have ADS-B transponders and use older transponders to transmit flight information, which can result in tracking tools such as Turnstone showing inaccurate position data.
In the previous case study of CBP aircraft, the Turnstone results appeared to show an MQ-9 Reaper drone in Canada on Jan. 20, 2026.
Search results for CBP MQ-9 Reaper drones on Jan. 20, 2026, which appeared to show four instances (circled) of a drone in Canadian airspace. Source: Turnstone/Bellingcat
Is this evidence of covert DHS missions in Canadian airspace? Likely not: a cross-check of the drone’s hex code on that date with ADS-B Exchange shows that the aircraft’s position track is not smooth, but jumps back and forth between a line in the US and several points many kilometres away in Canada.
Screenshot from flight tracking website ADS-B Exchange, appearing to show a CBP drone flying within US airspace but jumping suddenly to the circled points in Canada, several kilometres away. Source: ADS-B Exchange; annotations by Bellingcat
This happens because when ADS-B position data is not available, flight trackers often use multilateration (MLAT), which estimates the location of the aircraft using the time differences between signals transmitted from known sites, as a substitute. The flight tracking information on ADS-B Exchange shows that the position was calculated using MLAT, which is less accurate than position data directly transmitted through ADS-B. ADSB.lol, which is the data source used by Turnstone, uses MLAT when ADS-B position data is not available.
ADS-B data is also limited by where ground antennas are available to receive radio signals from aircraft and by when aircraft choose to transmit the data.
Other datasets which Bellingcat has used to enable the filters available on Turnstone each have their own limitations.
There is no single source of data on aircraft ownership. ADS-B data identifies an aircraft only using its ICAO address or hex codes, but does not contain other information that directly specifies the type of aircraft or its registration.
Instead, flight-tracking websites reference aircraft registration databases, such as those maintained by the US Federal Aviation Administration, to correlate ICAO addresses with registration information. The ownership data displayed on Turnstone is from tar1090-db, a community-maintained project which has produced the most comprehensive freely available global aircraft registration database. However, since ownership data is collected from many jurisdictions, with different privacy and disclosure requirements, it may sometimes be out-of-date or misleading.
Ownership information displayed in Turnstone or any other flight-tracking software should still be verified independently using multiple sources.
For example, one of the aircraft that came up in the search for flights between El Paso and Guantanamo Bay had a hex code of a6b0f5. This showed up in Turnstone’s results as being owned by Bank of Utah Trustee, which matches the operator listed for this flight on ADS-B Exchange. But some of the flight codes used by this aircraft, starting with “GXA”, are used by Global Crossing Airlines (GlobalX). The Bank of Utah is known to legally own aircraft under a trust relationship, while leasing the aircraft and operational control to third parties such as GlobalX.
Screenshot from Turnstone showing aircraft flying between Guantanamo Bay and El Paso, from a historical flight data search on Jan. 26, 2026.
The “Category” label and “Military” flag, which provide a convenient way to filter aircraft, are pre-generated by a custom-prompted large language model, Claude Sonnet 4.0, based on the make and model of an aircraft.
For example, the LLM may take a type code of A321, which refers to an Airbus A321 passenger jet, as input and assign the corresponding aircraft the category of “airliner”.
Bellingcat manually verified over 80 per cent of aircraft, corresponding to the most common aircraft types. But as we know, LLMs are prone to hallucinations, and categorisation may be inaccurate for more obscure aircraft. Additionally, some aircraft, such as the V-22 Osprey, fall between categories and are inherently ambiguous.
To prevent errors caused by the potential miscategorisation of aircraft, you may want to search by type code, which will draw from the raw tar1090-db data, rather than category. All aircraft registration, type, and owner information should be independently verified.
Suggestions and Further Information
As we’ve seen in this guide, Turnstone searches historical ADS-B data to allow researchers to explore flight patterns over time and in specific locations. While flight-tracking data has inherent limitations, Turnstone can provide useful leads for researchers looking to incorporate flight tracking in their investigations.
If you have suggestions for improving the tool, you can submit a pull request on Bellingcat’s GitHub. More technical information can also be found in the tool’s README.
For more demos and information about the history of this tool, watch a talk that Bellingcat gave about it at the What Hackers Yearn (WHY) 2025 hacker camp:
Bellingcat is a non-profit and the ability to carry out our work is dependent on the kind support of individual donors. If you would like to support our work, you can do so here. You can also subscribe to our Patreon channel here. Subscribe to our Newsletter and follow us on Bluesky here and Mastodon here.
To stay up to date on our latest investigations, join Bellingcat’s WhatsApp channel here.
Federal agents have frequently used so-called “less-lethal” weapons against protesters, including impact projectiles, tear gas and pepper spray, since the Trump administration’s nationwide immigration raids began last year.
Earlier this month, two protesters in California were reportedly blinded after US federal agents fired less-lethal rounds at their faces from close range. These incidents were part of a wave of violent clashes between agents from the Department of Homeland Security (DHS) and protesters across the country after the deadly shooting of US citizen Renee Good by an Immigration and Customs Enforcement (ICE) agent in Minneapolis.
Federal agents armed with less-lethal weapons in Minneapolis on Friday, Jan. 9, 2026. Source: Cristina Matuozzi/Sipa USA via Reuters Connect
In protests in Minneapolis immediately following Good’s death, one Customs and Border Patrol (CBP) officer was captured on camera firing a 40mm less-lethal launcher five times in less than five minutes, with several of these shots appearing to target protesters’ faces, which is against CBP’s own use-of-force policy.
A Bellingcat investigation of DHS incidents in October 2025 also found about 30 incidents that appeared to violate a temporary restraining order (TRO) issued by an Illinois judge restricting how DHS agents could use LLWs.
Support Bellingcat
Your donations directly contribute to our ability to publish groundbreaking investigations and uncover wrongdoing around the world.
It is not always obvious whether the use of a LLW is authorised or not, as DHS component agencies such as ICE and CBP have varying guidance on factors such as the level of resistance an individual needs to show before a certain type of force can be used, as well as how specific types of less-lethal weapons and munitions can be used.
While CBP’s use-of-force policy as of January 2021 is available on its website, ICE does not include specific guidance on less-lethal weapons in its 2023 “Firearms and Use of Force” Directive, and does not appear to have any publicly available policy that outlines this guidance.
DHS did not respond by publication time to Bellingcat’s request for the most recent DHS, CBP and ICE use-of-force policies, or to questions about what less-lethal weapons were authorised for use by the department and its component agencies.
The DHS use-of-force policy, updated in February 2023, states that the department’s law enforcement officers and agents may use force, including LLWs, “only when no reasonably effective, safe and feasible alternative appears to exist”. It also says agents may only use a level of force that is “objectively reasonable in light of the facts and circumstances” that they face at the time.
DHS has repeatedlydefended its use of riot-control weapons in protests across the country, stating that it was “taking reasonable and constitutional measures to uphold the rule of law and protect [its] officers”.
Here’s how to identify some of the less-lethal weapons that DHS agents, including those from ICE and CBP, have been seen using during recent immigration operations.
Compressed Air Launchers or ‘PepperBall Guns’
Left: A Border Patrol Agent in Chicago carrying an orange TAC-SF series PepperBall gun in Illinois on Oct. 24, 2025. Right: Agent aiming a Pepperball gun at someone filming them in Illinois on Oct. 19, 2025. Source: Youtube / @BlockClubChicago and Tiktok / @ericcervantes25
Compressed air, or pneumatic launchers, are essentially paintball guns that fire 0.68mm balls which break on impact. Often, this releases a powdered chemical irritant such as oleoresin capsicum (OC) or PavaPowder – the same compounds typically found in pepper spray.
Compressed air launchers can also be used with other projectiles, such as “marking” projectiles that use paint to mark an individual for later arrest, and projectiles intended to break glass.
These weapons are often referred to as “PepperBall” guns, named after the leading brand PepperBall. However, DHS agents have also been seen carrying compressed air launchers from different brands, such as the FN303, produced by FN America.
Many compressed air launchers resemble standard paintball guns, with a distinct hopper or loader, which holds the ball projectiles, mounted to the top. They also have a compressed air tank that might be mounted to the side, bottom, or inside the buttstock (or back) of the weapon.
Many compressed air launchers, and less-lethal weapons in general, have very bright colours such as orange to distinguish them from lethal weapons.
The TAC-SF PepperBall gun features a compressed air tank and a top-mounted EL-2 hopper, which has a distinctive shape. Graphic: Justin Baird for Bellingcat
The PepperBall TAC-SA Pro’s hopper is a slightly different shape from the TAC-SF, but serves the same purpose. Graphic: Justin Baird for Bellingcat
PepperBall VKS Pro features a compressed air tank located inside the buttstock and a magazine rather than a top-mounted hopper. Graphic: Justin Baird for Bellingcat
However, some compressed air launchers require closer scrutiny to distinguish them from firearms.
For example, federal agents have been seen carrying FN303 compressed air launchers in videos of immigration enforcement activities. This weapon may resemble a rifle or other firearm, as it is usually all-black and, unlike the TAC-SF series PepperBall guns, lacks a visible hopper.
Left: Agent holding an FN303 in California on June 11, 2025. Right: Federal Agent aiming a FN303 compressed air launcher at someone filming them in Illinois on Oct. 7, 2025. Source: TikTok / @anthony.depice and TikTok / @krisvvec
If closer examination is possible, this weapon can be identified by its distinct features, including a circular magazine, side-mounted compressed air tank and a hose connecting the firearm to the air tank.
The FN303’s air tank is mounted on the side and connected to the firearm by a hose. Graphic: Justin Baird for Bellingcat
The January 2021 CBP Use of Force Policy places several restrictions on the use of compressed air launchers, including that they should not be used against small children, the elderly, visibly pregnant women, or people operating a vehicle. It also states that PepperBall guns should not be used within 3 feet “unless the use of deadly force is reasonable and necessary”. When using the FN303, the minimum distance is increased to 10 feet.
The CBP Use of Force Policy says that the intentional targeting of areas where there is a “substantial risk of serious bodily injury or death is considered a use of deadly force.” Agents are instructed not to target “the head, neck, spine, or groin of the intended subject, unless the use of deadly force is reasonable”. PepperBall and FN America provide similar warnings about avoiding vital areas to prevent serious injury or death.
According to a 2021 report by the US Office of Inspector General, CBP requires its agents to recertify their training to use PepperBall guns and FN303s every year, but ICE does not.
40mm Launchers
Left: CBP agent “EZ-17” with a B&T GL06 40mm launcher and a belt with a variety of Defense Technology 40mm less lethal munitions, including one Direct Impact OC round and two Direct Impact CS rounds in Illinois on Oct. 24, 2025. Centre: EZ-17 firing a B&T GL06 launcher at a man in Minneapolis on Jan. 7, 2026. Right: A federal agent with a B&T GL06 in Illinois on Oct. 24, 2025. Source: YouTube / Block Club Chicago, X / Dymanh, Facebook / Draco Nesquik
DHS agents also use 40mm launchers to fire “Less-Lethal Specialist Impact and Chemical Munitions (LLSI-CM)”. These launchers resemble military grenade launchers, but are used to fire less-lethal ammunition, including “sponge” rounds that can disperse chemical irritants on impact.
The B&T GL06 (pictured) and other 40mm launchers have a visibly wider barrel than compressed air launchers or standard firearms. Graphic: Justin Baird for Bellingcat
There are various less-lethal munitions available for 40mm launchers, including those whose primary function is “pain compliance” through the force of impact, chemical irritants or a combination of both.
Videos of clashes between Border Patrol agents and protesters show these launchers being used with combination rounds designed to hit the target for pain compliance while also delivering a chemical irritant such as OC or CS.
Direct Impact munitions by Defense Technology have distinctive rounded sponge foam noses and colours that indicate their chemical fill. Graphic: Justin Baird for Bellingcat
Other munitions dispense chemical irritants or smoke after being launched. For example, in the protests immediately following Good’s death, a Border Patrol agent was seen firing a 40mm munition that released multiple projectiles emitting chemical irritants in a single shot, consistent with the “SKAT Shell” by Defense Technology.
The SKAT Shell by Defense Technology (left) fires multiple projectiles, while the company’s SPEDE-Heat shell launches a single projectile. Graphic: Justin Baird for Bellingcat
Defense Technology’s technical specifications for its 40mm Direct Impact Rounds, which agents have been seen armed with, state that the munitions are considered less-lethal when fired at a minimum safe range of 5 feet and at the large muscle groups of the buttocks, thigh and knees, which “provide sufficient pain stimulus, while greatly reducing serious or life-threatening injuries”.
A DHS Office of Inspector General Report in 2021 noted varying guidance on the use of 40mm launchers among the department’s component agencies: “ICE’s use of force policy indicates that the 40MM launcher is deadly force when fired at someone, while the CBP use of force policy only directs officers not to target a person’s head or neck.”
CBP’s 2021 use-of-force policy states that agents should “not intentionally target the head, neck, groin, spine, or female breast”, and that anyone in custody who has been subject to such munitions should be seen by a medical professional “as soon as practicable”.
As of publication, DHS had not replied to Bellingcat’s questions about whether the department had an internal policy or provided training to staff on the minimum safe distance for 40mm less-lethal launchers as recommended by the manufacturers.
Hand-Thrown Munitions
Top Left: Border Patrol Commander of Operations At Large Greg Bovino with two Triple-Chaser CS Grenades on his vest in Minneapolis on Jan. 8, 2026. Top Right: Person holding a used Pocket Tactical Green Smoke grenade in Minneapolis, Jan. 21, 2026. Bottom Left: Top third of a Triple-Chaser Grenade in Illinois, Oct. 25, 2025. Bottom Right: Used Riot Control CS Grenade in Minneapolis, Jan. 23, 2026. Source: Nick Sortor, Rollofthedice, Bluesky / Unraveled Press, Andrew Hazzard
DHS agents have also been seen throwing some less-lethal munitions, such as flash-bangs, smoke and “tear gas” grenades or canisters by hand.
These munitions activate a short delay after the grenade is employed. When they activate, flash-bangs or “stun” grenades emit a bright flash of light and a loud sound that is designed to disorient targets. Both smoke grenades and tear gas (also known as “CS gas” or “OC gas”) emit thick smoke, but the former just impedes visibility, whereas the latter also contains chemical irritants that sting the eyes.
The shape and general construction, colour, and any text can help identify these munitions.
Less-lethal munitions typically feature the manufacturer’s logo, the model name of the munition, and the model or part number. The text and manufacturer logo are typically colour-coded to indicate the type of payload the munition has, with blue indicating CS, orange indicating OC, yellow indicating smoke, green indicating a marking composition and black indicating munitions with no chemical payload.
The “Triple-Chaser” grenade by Defense Technology (left) has three distinct segments that separate after the grenade is thrown, with each emitting smoke or chemical irritants, while other chemical grenades by the same company have a single smooth body (right). Graphic: Justin Baird for Bellingcat
A 2021 analysis by Bellingcat and Newsy found that Defense Technology and Combined Tactical Systems, the two manufacturers which produce most of the less-lethal munitions used by federal agents, both list the model numbers of their products online. Publicly available price lists for Defense Technology and Combined Tactical Systems can also be used to identify specific munitions by their model numbers.
CBP’s 2021 use-of-force policy states that hand-thrown munitions are subject to the same restrictions for use as munition launcher-fired impact and chemical munitions.
Chemical Irritant Sprays
Left: DHS agent using a chemical irritant spray on a protester in Minneapolis on Nov. 25, 2025. Centre: CBP Agent spraying Alex Pretti with what appears to be OC spray moments before he is killed in Minneapolis on Jan. 24, 2026. Right: Federal Agent with a SABRE MK-9 spray threatening to spray a journalist if they do not move back in Minneapolis on Dec. 11, 2025. Source: Reddit / I_May_Have_Weed, TikTok/ShitboxHyundai, Instagram / Status Coup
DHS agents have also been using handheld chemical irritant sprays, often colloquially referred to as “pepper spray” or “mace”.
These sprays come in a variety of sizes and concentrations containing CS, OC, or both. Sprays used by law enforcement usually have a canister size designated “MK-” followed by a number, with higher numbers indicating larger canister sizes. The concentration of chemical irritants contained in the spray is also indicated on the canister.
The .2% MK-9 OC Spray by Defense Technology (left). The MK-9 produced by various companies with various concentrations has been seen often used by federal agents on protestors (right). Graphic: Justin Baird for Bellingcat
The effectiveness of OC sprays is determined by the concentration of major capsaicinoids, which are the active compounds in OC that cause irritation. These sprays are also affected by the type of aerosol dispersion, or stream, used. Different types of streams increase or decrease the range of the spray as well as the coverage area.
Civilian and law enforcement sprays range from 0.18 percent to 1.33 percent major capsaicinoids, according to SABRE, a producer of law enforcement and civilian sprays. Civilian sprays in the US can have the same major capsaicinoid content as law enforcement sprays, but are restricted to smaller-sized canisters.
Subscribe to the Bellingcat newsletter
Subscribe to our newsletter for first access to our published content and events that our staff and contributors are involved with, including interviews and training workshops.
Defense Technology sprays have different colour bands to indicate the percentage of major capsaicinoids in the spray for OC. If the spray is CS, the CS concentration is standardised at 2 percent. The company uses a white band for .2 percent, yellow band for .4 percent, orange band for .7 percent, red band for 1.3 percent and a grey band for sprays containing either CS or a combination of OC and CS.
SABRE sells a variety of concentrations and sprays as law enforcement products, including 0.33 percent, 0.67 percent, and 1.33 percent major capsaicinoid concentrations of OC, as well as CS, and combination CS and OC sprays. The specific concentrations of SABRE sprays and the type of stream can also be identified by the text on the canister.
One Air Force Research Laboratory study found that some sprays may pose a significant risk of severe eye damage due to pressure injuries resulting from large aerosol droplets hitting the eye.
Defense Technology’s technical specifications recommend a minimum distance of between 3 and 6 feet, depending on the specific spray. SABRE does not publicly provide their minimum safe deployment distances, but a Mesa Police Department document lists a minimum distance of six feet for the SABRE Red MK-9. CBP’s 2021 use-of-force policy does not provide any minimum use distances.
CBP’s 2021 use-of-force policy states that OC Spray may only be used on individuals offering “active resistance”, and that it should not be used on “small children; visibly pregnant; and operators of motor vehicles”.
Electronic Control Weapons
Left: Federal Agent pointing an Axon Taser 10 at a bystander who was filming an arrest in Los Angeles in June 2025. Right: DHS Agent with an Axon Taser 10 during an arrest in California on June 24, 2025. Source: Instagram / @dianaluespeciales, Instagram / Joe Knows Ventura
ECWs can deliver a shock upon direct contact or launch probes that embed in the targeted person, incapacitating them.
A shock on contact, or a “drive-stun” feature, delivers localised pain while in direct contact. When properly deployed, the probes send signals to the body that cause muscles to contract. A person’s body “locking up” from muscle contractions is an indicator that an ECW has been deployed. ECWs may be capable of using either or both methods. ECWs are typically painted a combination of black and bright yellow, but this varies between models. The bright colour of parts of tasers is a common feature to help distinguish an ECW from handguns used by federal agents. When viewed from the front, a circular gun barrel is visible on handguns, while ECWs feature multiple circular probes or rectangular covers on the cartridge. ECWs also usually have flashlights and lasers, although handguns may also be equipped with these features. Some ECWs may make audible sounds when armed or deployed.
The Axon TASER 10. Graphic: Justin Baird for Bellingcat
Axon, the predominant manufacturer of ECWs, produces several models including the TASER 10 and TASER 7. Axon provides a policy guide on recommended use of its TASER models to law enforcement agencies, which recommends targeting below the neck from behind, or the lower torso from the front. It recommends avoiding sensitive areas including the head, face, throat, chest and groin.
Axon also recommends against using ECWs against small children, the elderly, pregnant people, very thin people and individuals in positions of increased risks such as running, operating a motor vehicle, or in an elevated position “unless the situation justifies an increased risk”.
CBP’s 2021 use-of-force policy, in addition to restricting the use of ECWs against small children, the elderly, visibly pregnant women, and people operating a vehicle, states that they should not be used against someone who is running or handcuffed. However, the policy does state that there may be an exception to the rule against using ECWs on a running person if an agent has a “reasonable belief that the subject presents an imminent threat of injury” to an agent or another person. This threat, according to the policy, must “outweigh the risk of injury to the subject that might occur as a result of an uncontrolled fall while the subject is running”.
Bellingcat is a non-profit and the ability to carry out our work is dependent on the kind support of individual donors. If you would like to support our work, you can do so here. You can also subscribe to our Patreon channel here. Subscribe to our Newsletter and follow us on Bluesky here and Mastodon here.
In June, Bellingcat ran 500 geolocation tests, comparing LLMs from various companies against each other, as well as Google Lens – a staple tool for finding the location of photos.
At the time, ChatGPT o4-mini-high emerged as the clear winner, with Google Lens outperforming most other models. Just two months later, with new versions of these AI tools available, we re-ran the trial – this time including Google “AI Mode,” GPT-5, GPT-5 Thinking, and Grok 4 into the mix.
These five photos were excluded from our most recent trial as they were published in our previous article.
The original test used 25 of Bellingcat’s own holiday photos. From cities to remote countryside, the images included scenes both with and without recognisable features – such as roads, signage, mountains, or architecture. Images were sourced from every continent.
For the updated trial, five test photos were excluded, as they had appeared in a previous article, thus compromising the integrity of the results.
All 24 models’ responses were ranked on a scale from 0 to 10, with 10 indicating an accurate and specific identification (such as a neighbourhood, trail, or landmark) and 0 indicating no attempt to identify the location at all.
Google AI Mode was shown to be the most capable geolocation tool overall.
Grok 4 gave both better and worse answers compared to Grok 3 but, on average, scored marginally higher. However, it was still less accurate than older versions of Gemini and GPT.
GPT-5, even in ‘Thinking’ and ‘Pro’ modes, was a considerable downgrade when compared with the capabilities demonstrated by GPT o4-mini-high. In one example, of a city street with skyscrapers in the background, o4-mini-high correctly identified the street, while GPT-5 in Thinking mode pointed to the wrong country.
Support Bellingcat
Your donations directly contribute to our ability to publish groundbreaking investigations and uncover wrongdoing around the world.
Despite delivering faster answers, GPT-5 appeared to sacrifice accuracy. A surprising number of errors and a general sense of disappointment in the new model have also been reported by other users.
Bellingcat tested GPT-5 and its ‘Thinking’ mode via the Plus subscription, which costs roughly the same as access to 04-mini-high prior to its retirement. Five of the most difficult test images were also run through GPT-5 Pro. But even Pro, with a premium price tag of €200 per month, failed to geolocate the photos any more accurately than GPT 04-mini-high.
A Beach, a Hotel and a Ferris Wheel
The disparity between Google and the GPT models became even more apparent in Test 25 – a photo of a shoreline hotel in Noordwijk, the Netherlands, with a Ferris wheel rising just beyond the dunes.
Test 25: A photo of Noordwijk beach in the Netherlands. Credit: Bellingcat.
In the previous trial, most older models – including those from GPT, Claude, Gemini and Grok – accurately identified the country as the Netherlands but failed to locate the town. Many latched onto the Ferris wheel but pointed instead to the seaside town of Scheveningen, which also has a Ferris wheel, though situated on a pier, not among the sand dunes.
However, the most recent models, GPT-5 Pro and Thinking, were even less accurate, identifying a beach in France – an entirely different country.
Unfortunately for open source researchers, following the release of GPT-5, OpenAI removed the option to select older models such as o4-mini-high. After a wave of negative feedback, OpenAI reinstated GPT-4o as the default model for paid subscribers. However, the most capable geolocation models identified in Bellingcat’s testing remain inaccessible.
Google AI Mode, on the other hand, was the first, and only model so far, to correctly identify Noordwijk as the location in Test 25.
Though AI Mode is powered by a version of Gemini 2.5, it outperformed Gemini 2.5 Pro Deep Research in these tests. Described by Google as its “most powerful AI search, with more advanced reasoning and multimodality,” AI Mode geolocated test images with greater accuracy than any GPT models, including our previous winner, o4-mini-high.
The majority of models, at some point, returned a hallucination. Users should not rely solely on the answers provided by LLMs. Even the best options, including Google AI Mode, still, at times, confidently point to the wrong location.
The difference in models’ capabilities compared with just two months ago shows how quickly this field is evolving. However, OpenAI’s recent changes also suggest that progress is not guaranteed, and that AI’s ability to geolocate may plateau or even worsen over time. As new models emerge, Bellingcat will continue to test them.
Thanks to Nathan Patin for contributing to the original benchmark tests.
Bellingcat is a non-profit and the ability to carry out our work is dependent on the kind support of individual donors. If you would like to support our work, you can do so here. You can also subscribe to our Patreon channel here. Subscribe to our Newsletter and follow us on Bluesky here and Instagram here.
Bellingcat’s Auto Archiver is a tool aimed at preserving online digital content before it can be modified, deleted or taken down. Publicly launched in 2022, it has preserved over 150,000 web pages and social media posts to date. The Auto Archiver has been used by Bellingcat’s journalists to preserve information on dozens of fast moving events such as the Jan. 6 riots – when we first used the tool internally – as well as gather digital evidence for our Justice and Accountability project and to monitor Civilian Harm in Ukraine.
The Auto Archiver has also been adopted by both large newsrooms and NGOs. It has been used by individual researchers, journalists, activists, archivists, academics and developers as well. With interest in the tool strong, we have worked hard to add to and improve it over time. But we have used the past few months to take a step back and to build a new and more robust ecosystem to further help individual organisations and researchers use and benefit from it.
Our aim has been to make it more reliable and even easier to use for more people. Today, we are happy to announce an updated version of the Auto Archiver which includes many new features like:
A new modular structure that improves the startup speed and reliability of the tool
New features like chain of custody, perceptual hashing for deduplication, and techniques to avoid anti-bot measures and captchas on websites
A user-friendly tool to configure the Auto Archiver, without the need to edit configuration text files
Screenshot of new Documentation site for the Auto Archiver
For an in-depth look at the changes made in this stable version of the Auto Archiver, see the What Changed, What Remains section further down in this article.
Automated Archiving and Collaboration – When to Use This Tool?
The latest version of the Auto Archiver has an easy-to-use web interface and a simplified installation process that makes it more straightforward to set up than before. However, some technical skills are still required for this initial process, and there are other tools available that could meet many of your archiving needs.
Support Bellingcat
Your donations directly contribute to our ability to publish groundbreaking investigations and uncover wrongdoing around the world.
If all you need is to archive a few unauthenticated URLs, we recommend using the Wayback Machine or Archive.today. Alternatively, WebRecorder’s browser extension ArchiveWebPage can create a replayable archive of a website you visit – even for content behind login walls. For batch processing, the Wayback Machine has a bulk upload service that accepts Google Sheets. If you individually need to record all your browser interactions and store content along the way there are paid options like Hunchly. Finally, if all you are interested in are videos and are comfortable with the command line, yt-dlp will probably be enough to download those, even in bulk.
But if you’re hoping to automate your archiving, or archive a large number of URLs in a collaborative environment, then this is where the Auto Archiver really shines. Its modular framework allows you or your team to customise archiving based on your needs, and provides a way to generate metadata that ensures others can trust that your archived content has not been tampered with.
Learn more about what sites the Auto Archiver can archive here.
The Future of Web Archiving
Archiving the web is hard, especially when logins, captchas, and other bot prevention systems are in place. We will do our best to keep improving our Auto Archiver, but we note that it should be just one of many tools in your researcher’s toolkit. You can explore a variety of other useful tools in the Bellingcat Open Source Investigation Toolkit.
Still, if you want to support us on this journey of archiving critical information, you can:
Test, give feedback, and develop new features in our GitHub
For newsrooms: If you work in a newsroom or research team and want to access a demo or help to deploy the Auto Archiver internally you can reach us at contact-tech@bellingcat.com with the Subject “Auto Archiver at [my team/organisation]” and tell us more about your organisation and archiving needs. Building a greater adoption base is the best way to ensure the future of this tool and its versatility.
What Changed, What Remains
Subscribe to the Bellingcat newsletter
Subscribe to our newsletter for first access to our published content and events that our staff and contributors are involved with, including interviews and training workshops.
Now that we have given a broad overview of the tool and its changes, what follows is a deeper look at how different parts of it work and interact. This will likely be of greater benefit for more technical users, and we again stress that successful users of the tool will likely need some technical knowledge to set it up for the first time.
But help is available with our live Auto Archiver Documentation. This is where you will always find the latest information on how to install, configure or debug the tool. Even if some aspects mentioned in this article change in the coming years, the documentation will be your go-to space for the up to date instructions.
If you have questions or problems please open an issue on GitHub. That’s where others will also be going to for help and constitutes our shared knowledge space.
A New Architecture
Many open source researchers, including at Bellingcat, favour using the Auto Archiver with the Google Sheets integration, which allows users to work collaboratively by adding links to a spreadsheet and letting the Auto Archiver run in the background. However, we have now made it simpler to integrate the Auto Archiver into other systems. One such example is ATLOS, a collaborative investigations platform that integrated the Auto Archiver and which has been used by Bellingcat and the Centre for Information Resilience.
Integration is possible via the new modular architecture of the Auto Archiver and can be seen in the two new projects that we recently made public under open source code licenses: the Auto Archiver API and the Auto Archiver Web Interface.
A screen grab of the new Auto Archiver Web Interface showing the Google Spreadsheets management page, where users can enable the Auto Archiver to run periodically on new or existing spreadsheets.
Modules are the building blocks of the archiving pipeline and tell the tool how to run. They detail where to find the URLs, which archiving techniques to use, what additional processing to carry out on archived content and where and how to store it. Each module falls into a specific class:
Feeder modules specify where to read the URLs from. There’s one for Google Sheets, for example.
Extractor modules download media and other metadata from a URL: our most versatile one is the Generic Extractor, which uses yt-dlp to download videos. However, extractors can be tailor made for specific platforms like the Telethon Extractor, which requires a Telegram account to download all media and metadata from the messages in public or private chats an account has joined.
Enricher modules increase the value of the archived content with additional information or checks, such as hashing or timestamping the content for future consistency or chain of custody validations.
Storage modules tell the tool where to put the files it downloaded or generated. The easiest is to store it locally. But to ensure better preservation the best practice is to use cloud storages like S3 or Google Drive.
Database modules simply indicate where to save a record of this archive, such as whether archival was successful and which methods were used. You can use a CSV file and Google Sheets, for example.
The modules documentation can be found here and it is there to help you understand how each module works and is configured. Configuring which modules to use is done via a YAML file. If you are not comfortable with those, we have you covered with a new interface called the configuration editor where you can visually create or edit your modules configuration. In fact, the first time you run the Auto Archiver a minimal working YAML configuration file is generated which you can use straight away to read URLs from the command line and store archived content locally.
Some platforms rate-limit or outright block IPs based on inauthentic behaviour. One of the strategies we employ to circumvent that is sending traffic through a proxy, which you can configure in specific modules like the Generic Extractor . We have been using Oxylab’s Residential Proxies as part of their Project 4beta successfully for over a year, but know that there are several good providers out there.
If you are a developer, you can design new modules as needed using Python code, and we welcome it if you want to contribute those back to our code. Imagine a Feeder that is constantly scraping URLs from a Bluesky account, or an Enricher that uses an AI model to detect and blur graphic content. All of that is possible and easy to build in this new architecture.
We hope you will enjoy the updated tool.
Please give us any feedback or suggestions for improvements by contacting us via contact-tech@bellingcat.com.
Bellingcat is a non-profit and the ability to carry out our work is dependent on the kind support of individual donors. If you would like to support our work, you can do so here. You can also subscribe to our Patreon channel here. Subscribe to our Newsletter and follow us on Bluesky here and Instagram here.
This guide is part of a collaboration between Bellingcat and Evident on detecting AI-generated products. You can watch Evident’s video here.
Sipping coffee from a mug carved from mineral rock, its surface glimmering with amethyst, rose quartz and other crystals, sounds almost too magical to be real.
And unfortunately, as some shoppers discovered, it was.
Ads for crystal coffee cups, like the one shown in the Facebook post below, have appeared across the internet. The artisan mugs, available in color variations like blue, green and pink, were being sold on a swathe of platforms ranging from independent Facebook pages to large retailers including Amazon. However, when customers received these mugs, they were in for a surprise.
Facebook post from an Amazon deals Facebook group linking to an Amazon page for the crystal mugs. Names and full URL obscured by Bellingcat. Source: Facebook
In the comment section of this Facebook post, users shared images of the mugs they had bought, which bore little resemblance to the fantastical images in the listing.
A compilation of images posted by Facebook users showing the “crystal” mugs they received.
Major advancements in artificial intelligence in recent years have made it harder to differentiate between what’s real or fake, not just when it comes to photos and videos of people, but also in product listings.
There has also been an increase in AI-generated books being sold on platforms including Amazon, with some even showing up in libraries without any disclosure that they are AI-generated.
But AI is not perfect, and if you look closely, you can often detect several tell-tale signs of a fake. In this guide, we walk you through some questions that savvy shoppers can ask to identify “red flags”, using just critical thinking and basic investigative tools such as reverse image searches.
Does the Image Make Sense?
Many AI-generated images have some sort of “sheen” or look to them that can set off alarm bells.
Take this image of one of the “crystal coffee mugs”. At first glance, it looks like a beautiful mug. But if you look closer, you might notice defects in the image.
Photo of the virally sold crystal mug, annotated by Bellingcat. Source: Reddit
There are multiple areas on this mug where the lines of the “crystal” do not align. These broken or inconsistent lines are red flags. There also appears to be some sort of defect in the centre of the mug that resembles a smudge from digital painting, rather than a natural flaw in rock or crystal. The blurriness of the smudge is a feature often seen in AI-generated images. And at the top of the rim, a section of the mug begins to fade out and disappear, suggesting the image has been manipulated.
It is also useful to think about how this product would work in practice. For example, the mug shown in the picture below appears to be made of some sort of lava-type stone, with glowing red light emanating from the cracks. The lighting on the mug appears to be artificial and since there are no visible wires, it would probably need a battery to power it. However, the listing does not specify whether a power source is required or included, which should raise suspicions that the image could be AI-generated.
An image of a mug being sold on Etsy, with the seller’s name blocked out by Bellingcat.
Are There Multiple Angles and Pictures of the Product?
AI image generators can create convincing images, but they are not great at producing the same image consistently. Authentic listings will often show the same item from multiple angles so customers can see what the object looks like before purchasing. If you only see one photo of the item, that is a red flag that the listing may be using an AI-generated image. Sellers will often take one amazing photo and place the object in multiple “scenes” but you may notice that they don’t show any other angle of the item.
Where there are multiple photos of the product, it is also worth considering whether it looks like the same product in all of the pictures. In the below Etsy listing for a crocheted Highland cow pattern, for example, there are multiple photos of crocheted Highland cows, but they are not consistently the same pattern or design.
A listing for a Highland cow crochet pattern, seller’s name obscured by Bellingcat. Source: Etsy
A collage of the images included in the listing for the highland cow template. Source: Etsy
Given that this listing is supposed to be for a pattern – a template which crocheters can follow to create the product shown – it’s suspicious that there are different colours, shapes and materials used in these photos. It may mean that these images were created by an image generator that was not able to replicate the exact same stuffed cow.
You can also focus on differences in small details, like the placement of the nostril holes, between the photos or even sometimes in the same photo. For example, in the very first image of this listing, the two nostril holes are slightly different shapes. In the subsequent images, there are slight variations in how these nostril holes are depicted on the cows. The shape of the horn, body, hooves, and the scarf, all have variations between the images.
The image also does not make sense as, if you’re familiar with crochet, you may notice that the hairs shown on the head, body and legs of some of these sample stuffed cows do not match the texture of the type of yarn typically used for crochet. In one of the seller’s replies to customer complaints, they even confirmed that these images were AI-generated.
In response to customer complaints, the seller stated that the images were AI-generated. Source: Etsy
Bonus Tip: Zooming In On Eyes
One useful hint for identifying an AI-generated image of a human face is to look at the reflective light in the eyes of the people shown and see if there are any abnormal patterns. The same principles may also be applied to images of animals or products such as this Highland cow, where there are shiny surfaces that reflect light.
In real photos, the shape of the light being reflected in the eyes is typically identical or nearly identical if they are facing the same direction. But AI-image generators have not perfected this feature. In some of the pictures of the stuffed cow’s eyes, the shape of the light differs. Since the stuffed toy depicted is facing forward, the light in both eyes should be the same as they should be reflecting back the same light source.
However, as you can see from the photos below, they are different – another indicator that these images are AI-generated.
Close up of the eyes of two of the stuffed cows (top), with the shape of the reflections in the eyes highlighted by Bellingcat in red (below)
Have You Thoroughly Read the Listing?
To protect themselves from being accused of misrepresentation or having their listings taken down by platforms, some sellers may hide disclosures within text or images – relying on the assumption that buyers may not closely read the details of their listings. If called out, they may then claim that the images were only for illustration.
To avoid falling prey to such tactics, look out for specific product details including the materials and dimensions, and whether the seller discloses that they are using AI-generated photos. Sellers may include these details within the descriptions to indicate that the item will be different to what is depicted in the listing’s image.
In the case of the mugs, some listings state that the product is a “crystal-like” or “mineral-inspired” design, indicating that it is made from another type of material.
In another example, these cute animal-themed ornaments look three-dimensional and hyper-realistic in their eBay listing. However, if you look at the full listing title, the seller specifies that the ornament is two-dimensional – in other words, flat.
A listing for “lifelike” animal ornaments that look three-dimensional in photos, although the title discloses that they are in fact two-dimensional, or flat ornaments. Seller name obscured by Bellingcat. Source: eBay
In one post on Reddit, a user said they purchased animal ornaments that looked similar to those in this listing. Based on their post, the ornaments they received were flat acrylic discs with images printed on them. If – as in the listing we saw – the seller indicated this in some way in the title or description, buyers who purchased the ornaments based on the AI-generated images alone may find it harder to seek recourse.
Scammers rely on people making impulse purchases. Being consistent in reading the details can protect you from these surprises.
Images shared by a Reddit user from an online listing of animal ornaments, and the actual ornaments they received. Source: Reddit
Are There Pictures Posted by Buyers?
Fake reviews can occur on just about any platform, not just retail websites. There are whole networks dedicated to creating fake reviews, so we cannot just rely on positive customer feedback to determine if a product is trustworthy to purchase.
However, it takes more effort to create a fake review that includes images of the product.
In addition to reading the text reviews, look to see if anyone has posted photos of the item in question, and compare how it looks to the item shown in the listing. Are these photos just taken from the listing? Do they look like they’re showing the same item? Does the background or setting look like someone’s home?
If the item is on a platform that does not have reviews, or seems to be a newly listed item without many reviews, you can try doing a reverse image search of the item. Some sellers will take down a listing when they start getting negative reviews, and then relist the item again. Reverse image searches may pick up archived versions of these older listings, where you might be able to find negative user reviews. You may even find multiple sellers listing the same item and see negative reviews for the product from another seller.
If the same product is being sold elsewhere, check the photos and customer reviews. If you cannot find any photos of the item other than those supplied by the seller, you may want to investigate further.
Is It Too Good to Be True?
Many of us often search for the cheapest items online, looking to get the most bang for our buck, but it is also important to be alert to deals that seem too good to be real.
It is always good practice to compare prices. Is there a difference of a few dollars, or a few hundred? Should a highly intricate sweater be this cheap?
Reverse image searches can also be a good tool to use here. If there is a drastic difference in cost on listings showing similar products, this should give you pause. While there may be legitimate reasons for such price differences, such as the country of origin or bulk buying by sellers, this could also indicate the lower priced listings are a scam.
For example, the below stained glass lamp in the shape of a cat is sold on Walmart, Amazon, and eBay, among others, for under US$23.
A stained glass lamp in the shape of a cat (top) and various platforms all selling the same lamp, names of sellers obscured by Bellingcat (bottom).
An online search for other stained glass lamps returns listings of lamps in more simple domed shapes that cost at least a hundred US dollars – significantly more than the cat-shaped ones that could be more costly to produce because of their intricacy.
Additionally, a Google search for cat-related stained glass lamps returned images of lamps in simpler, boxy shapes. Other than the images that matched the cat lamp above, the rest of the results were all listed at a significantly higher price point than US$25. From this search, it appears that not only is the price point too low but that even the design and shape of the cat lamp is not representative of other lamps available on the market.
While it’s possible that an item that looks somewhat similar may have a large price difference due to branding or geographical origin, this discrepancy is a potential red flag that you might want to investigate further to see if this is a real deal or a scam.
Google searches for stained glass lamps (top) and cat-shaped lamps (bottom), showing a range of prices in the hundreds of US dollars.
In this case, a reverse image search of this lamp showed that some customers who ordered it received a cheap plastic item with airbrushed paint rather than stained glass, and nothing at all close to the object in the listing.
Review from an Amazon customer who said they purchased the cat lamp.
Who Is Behind This Item?
Finally, it’s always helpful to look beyond the listing and consider who is profiting from the purchase.
Is this a name-brand item, or does it appear to be some mysterious seller that has popped up overnight? Does this seller have a website, or do they only exist on Facebook or Amazon? Is the seller’s account brand new? If they sell other items, what do the customer reviews say? Is the seller using an AI-generated image as their profile picture?
If it is a book you are purchasing, look to see who the author is. Does this person exist? Is there a legitimate publisher of the book, or is it just through Amazon’s self-publishing? While self-publishing does not automatically mean a book is untrustworthy, this process has fewer checks and balances compared with books from publishers, which usually go through a review before being released.
Doing an online search on the author should reveal other information about them. If they are real, does it appear that this book was authored by them? Do they promote it on other platforms? Could someone else be using their name without permission?
For example, the cookbook shown below lists the author as “Ethan Neulife”. Their bio on Amazon describes an “experienced author” but a search of his name did not turn up anything except cached listings on Amazon’s various online marketplaces for this book, which are no longer accessible. There were no social media profiles or personal sites under this name, articles about his books or any contact information available online.
Amazon listing for “Renal Diet Cookbook for Beginners”, as captured in January. Listings for this book across Amazon’s online marketplaces have since been taken down.
A reverse image search of the profile picture using several different search engines did not return any exact matches except those on Amazon. However, it did suggest stock images that were marked as AI-generated.
For example, one of the suggested results came from a website that specialises in AI-generated stock imagery, FreePik. The image titled “Portrait of Businessman on White Background”, generated using Midjourney 6, bore a striking resemblance to the profile photo of “Ethan Neulife”.
A reverse image search of a profile picture that returns results from AI-image websites may indicate that the image you are searching for is also AI-generated.
Profile image of “Ethan Nuelife” on Amazon (left), and suggested match of an AI-generated stock image of a man. Source: FreePik
These kinds of checks can be done before purchase to ensure that the book or product you are buying comes from a legitimate company or person. There are, of course, always small businesses or individuals vigilant about online privacy who may not have much information about themselves online, but if in doubt, it is a good idea to do some basic online research on the seller to get a sense if they are legitimate or a potential scammer.
Bellingcat is a non-profit and the ability to carry out our work is dependent on the kind support of individual donors. If you would like to support our work, you can do so here. You can also subscribe to our Patreon channel here. Subscribe to our Newsletter and follow us on Twitter here and Mastodon here.










 绿” (“plus green”, apparently referring to WeChat’s green logo) for WeChat, or “米” (rice) or the moneybag emoji for money.
绿” (“plus green”, apparently referring to WeChat’s green logo) for WeChat, or “米” (rice) or the moneybag emoji for money.


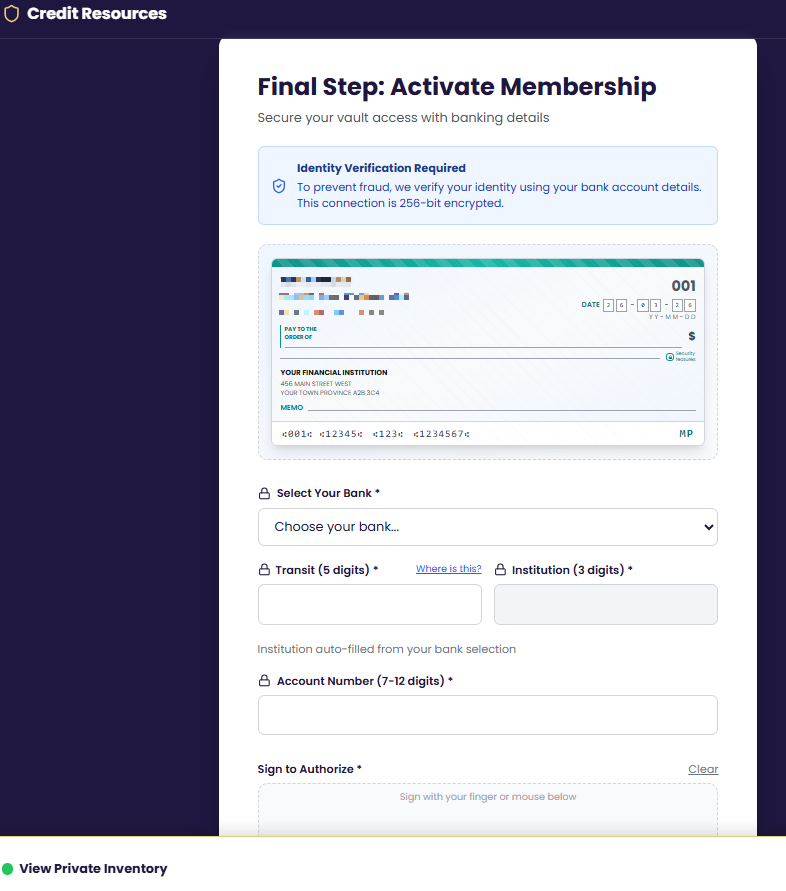






















 The US used what appears to be, without additional details, a nuclear weapon on Iran delivered by a…
The US used what appears to be, without additional details, a nuclear weapon on Iran delivered by a… 
 (@cirnosad)
(@cirnosad) 











 (@Eng_china5)
(@Eng_china5) 
 (@borzou)
(@borzou)