New PCPJack worm steals credentials, cleans TeamPCP infections
A new malware framework called PCPJack is stealing credentials from exposed cloud infrastructure while actively removing TeamPCP's access to the systems. [...]

At Datadog, an observability and security platform for cloud applications, I work on research studies that analyze anonymized infrastructure telemetry from thousands of production environments across Kubernetes, managed container platforms and serverless services across cloud providers. The datasets span multiple cloud providers and billions of workload hours. Much of that work goes into our annual reports on container and serverless adoption, where we examine how organizations run workloads in modern cloud environments.
Over the past few years, one question kept coming up as we updated these reports: As cloud platforms become more granular and autoscaling adoption increases, does resource efficiency improve?
Going into this work, I didn’t have a formal hypothesis about utilization improving over time. But there was an implicit assumption—one that felt reasonable. As platforms became more granular and autoscaling adoption increased, resource efficiency should improve at least incrementally.
It didn’t.
When we compared successive editions of the research, including the 2023 Container Report and the 2025 State of Containers and Serverless, the answer was less straightforward than expected. The share of Kubernetes workloads running well below their requested CPU and memory levels remained broadly consistent between reports.
That persistence raises an uncomfortable question: If modernization alone doesn’t improve utilization, what does?
Cloud environments today look markedly different from even three years ago.
In the 2023 Container Report, we found that over 65% of Kubernetes workloads were using less than 50% of their requested CPU and memory. That report examined container telemetry across thousands of production environments to understand how teams run Kubernetes workloads.
Two years later, the 2025 State of Containers and Serverless expanded the scope of the research to look at broader compute patterns, including the growing mix of containers and serverless, while continuing to analyze Kubernetes workloads.
Using the same <50% threshold for comparison, the overall utilization pattern remained similar. In October 2025, 72% of Kubernetes workloads were still using less than 50% of their requested CPU, and 62% were using less than 50% of their requested memory.
In other words, even as organizations adopted newer compute models and expanded autoscaling, most workloads continued to run well below their requested capacity.
At a surface level, the modernization between those report cycles is obvious: More granular compute models, broader instance diversification, increased use of managed services and deeper abstraction.
Looking only at platform capabilities and adoption trends, this appears to be steady operational maturity, the kind often discussed in CIO.com’s own coverage of cloud strategy.
If modernization alone were enough, we would expect to see measurable improvement in utilization patterns. The data suggests otherwise.
Using the same <50% threshold for comparison, the 2025 data shows a familiar pattern. In October 2025, 72% of Kubernetes workloads were using less than 50% of their requested CPU, and 62% (vs. 65% in 2023) were using less than 50% of their requested memory.
In other words, most workloads still operate well below their provisioned capacity.
Looking even closer, the distribution becomes more pronounced. In October 2025, 57% of workloads were using less than 25% of requested CPU, and 37% were using less than 25% of requested memory.
This is not marginal inefficiency at the edges. It reflects a large share of workloads running far below their requested baseline.
When I saw those updated numbers in the 2025 report, I was a little surprised. Not because I expected perfection, since cloud systems are inherently uneven, but because I expected at least some measurable drift toward tighter provisioning as platform sophistication increased.
Instead, the overall distribution remained remarkably persistent.
To be clear, this does not imply that teams are careless or that modernization efforts failed. It suggests something more structural. Utilization behaves less like a short-term tuning issue and more like a stable characteristic of how systems are configured and operated over time.
A longitudinal comparison between the 2023 and 2025 data shows that individual workloads churn, clusters scale and instance types diversify, yet the aggregate distribution remains comparatively steady. That persistence stood out more than any single annual trend.
Importantly, the longitudinal data does not explain why that persistence exists. It only shows that modernization at the platform layer does not automatically reshape the utilization distribution.
At scale, persistent underutilization also has cost implications. Even if individual workloads appear inexpensive, conservative provisioning raises the baseline against which budgets are set.
Over time, that baseline becomes normalized, shaping cloud forecasts, contract negotiations and infrastructure investment priorities.
Infrastructure data is rarely evenly distributed; it is long-tailed.
A relatively small number of workloads drive sustained utilization. A much larger number are bursty, intermittently active or lightly used. When averaged together, the system appears stable even when individual components are dynamic.
Averaging utilization metrics can therefore be misleading. An average implies symmetry. In practice, resource usage is asymmetric. Extreme values often drive cost and capacity exposure, while the median workload remains comparatively quiet. When those extremes are averaged away, the signals that matter most are softened.
Partial instrumentation adds another layer. Not every workload produces the same performance and utilization data at the same level of detail. As organizations mix legacy systems with newer managed services, visibility gaps are common. Those gaps can skew aggregate metrics and create a false sense of stability or efficiency.
CIOs encounter similar issues when interpreting other aggregate metrics such as average latency, mean time to recovery or blended cloud spend. As CIO.com has noted in discussions of meaningful metrics, aggregation can obscure operational reality.
In infrastructure, that obscurity can persist for years.
Before interpreting the trend, it is important to clarify what these utilization metrics measure.
In Kubernetes environments, utilization is typically measured relative to requested resources rather than raw machine capacity. Requests influence scheduling and reserve capacity on anode, shaping the baseline against which utilization is measured. But they also encode human judgment. Sometimes that judgment is based on load testing. Sometimes it reflects historical spikes. Sometimes it is simply conservative.
Two teams can run similar services and choose very different request baselines. The utilization metric will faithfully reflect that configuration choice.
That is one reason I am cautious about treating utilization as a moral signal. It is a technical metric, but it is also a reflection of configuration decisions embedded over time.
Looking at it over time shows what changes and what stubbornly does not, even as platforms evolve.
One obvious question is whether autoscaling adoption should materially change these patterns.
Horizontal Pod Autoscaling (HPA) is common across Kubernetes environments and widely supported across platforms. This reflects broader ecosystem trends described in the CNCF Annual Survey.
But elasticity is not the same as precision.
Many autoscaling configurations still center on CPU and memory signals. More context-aware scaling, based on queue depth or application-level indicators, remains less prevalent. Vertical scaling is comparatively rare and often used in advisory modes rather than actively reshaping requests.
Workloads can scale up and down without necessarily altering their baseline request posture or the broader utilization distribution we observe.
Enabling elasticity is straightforward. Sustaining precision over time is much harder.
Another pattern surfaced in the Container Reports is version lag. In both the 2022 and 2023 editions, a significant share of Kubernetes clusters were running versions approaching end-of-life even as newer releases were widely available.
Production systems rarely upgrade at the same pace as new platform capabilities are released. End-of-life versions persist. Premium support tiers extend. Older runtimes remain embedded even when more efficient versions are available.
Upgrades compete with feature delivery. Stability is prioritized. Risk is managed conservatively.
Version adoption does not directly determine utilization levels. But it reflects a broader dynamic: Configuration and upgrade decisions change more slowly than platform capabilities. When analyzed at scale, that inertia becomes visible. New tools layer onto existing systems, but earlier configuration assumptions often remain intact.
In practice, modern platforms often inherit older provisioning choices.
Seeing the same utilization pattern persist across report cycles shifted my thinking. It was not about Kubernetes, serverless or autoscaling in isolation. It was about separating capability from outcome.
Cloud platforms today offer far more granularity than they did a few years ago. We can allocate resources in smaller increments. We can autoscale pods and nodes. We can mix execution models. We can diversify architectures.
None of that automatically changes the empirical shape of infrastructure usage.
Modernization creates new possibilities, but it does not automatically change how resources are used.
Across report cycles, it became clear that architecture was evolving faster than the underlying usage patterns.
That distinction has significant implications for how infrastructure performance—and investment decisions—are interpreted.
If multiple years of visible platform evolution do not materially shift the utilization baseline, the constraint likely extends beyond feature availability.
What makes this pattern interesting is not that utilization is low in any single snapshot. It is that it remains low even as surrounding variables change. Platform capabilities evolve. Adoption curves shift. Workload composition becomes more heterogeneous. Yet the aggregate distribution remains comparatively stable.
That stability suggests something important: Modernization changes what is possible, but it does not automatically change how systems are configured or revisited over time.
For CIOs and senior technology leaders, the implication is not to pursue the next abstraction layer. It is to examine the decision frameworks that shape provisioning, headroom and risk tolerance year after year.
Cloud platforms will continue to evolve quickly. Whether utilization patterns change will depend less on new capabilities and more on how deliberately organizations revisit the assumptions embedded in their configurations.
This article is published as part of the Foundry Expert Contributor Network.
Want to join?

Small business owners should be sure to fix these three non-technical risks that require little cybersecurity expertise.
The post 3 easy-to-miss cybersecurity risks for small businesses appeared first on Security Boulevard.
There’s a lot to security that isn’t necessarily “cyber.” It’s not all hackers or complex network attacks.
Alongside traditional cyberattacks that deploy malware or exploit known software vulnerabilities, there are also less technical—yet equally devastating—forms of theft.
This doesn’t mean that well-known cybersecurity best practices don’t apply. Every small business owner should still use unique passwords for every account, turn on multi-factor authentication, keep their software and operating systems updated, and run always-on cybersecurity software.
But for the everyday small business owner juggling dozens of accounts, networks, devices, and the reams of data being created, stored, and shared across text messages, emails, and online portals, this advice is for you.
For National Small Business Week in the US, here are three ways to protect your business that require little technical prowess.
In the US, the Internal Revenue Service (IRS) allows small business owners to use their personal Social Security Number (SSN) as the Federal Tax ID. It’s a small grace meant to simplify annual record-keeping for sole proprietors and owner-employees, but for cybercriminals, it’s a basic oversight they’d like every small business to make.
Using your Social Security Number as your Federal Tax ID means putting your Social Security Number in an ever-increasing number of hands. That’s because small business taxes are different from taxes for everyday salaried employees.
Whenever a small business takes on a new client or a contractor who pays for services costing at least $600, that small business has to share and receive what is called a W-9 form. This exact form isn’t filed with the IRS, but it is used to track payments for later filings.
What’s more important, though, is that this form asks for an owner’s name, address, and tax ID number.
This means that as a small business grows, its vulnerability to identity theft increases in tandem. Every W-9 filed that uses an owner’s SSN as their tax ID number is another opportunity for that SSN to be stolen. After just one year of operation, a small business owner’s SSN could end up in the inboxes, filing cabinets, and cloud drives of a dozen different people and companies.
This is exactly what cybercriminals want.
Equipped with a W-9 form about your business, a cybercriminal could impersonate you or your business. They could open a business credit line, file fraudulent returns that claim your small business income, or scam your clients.
How to stay safe:
Apply for a free Employer Identification Number (EIN) at IRS.gov. It’s quick to do and it separates your business tax identity from your personal tax identity. After that, put the EIN on W-9s, 1099s, and all other business paperwork instead of your SSN.
The most popular cloud storage for most small business owners is the cloud storage they already have—their personal Google Drive or iCloud.
Built to make memory archival as easy as possible, these tools can automatically back up and secure nearly every single moment that happens through your device, from the vacation photos you snapped last summer, to your kid’s first steps recorded on video, to the texts you sent, the notes you made, and the calendar appointments you managed.
But this type of automatic archival poses a threat to any non-personal information that you view, send, markup, or sign when using your personal smartphone. Suddenly, and often without thinking about it, your cloud storage has backups of signed contracts, tax returns, client intake forms, invoices, business financial statements, and photos of physical paperwork.
Above, we warned about using your SSN as your tax ID because it creates a risk if anyone in your business network is breached. But storing client information in your personal cloud storage creates a different problem: it puts that risk directly on you.
Compounding the threat here is the fact that many personal cloud storage accounts are shared with family members. More people accessing the same account means more exposure and more chances for mistakes, even if everyone has good intentions.
How to stay safe:
Go through the cloud backup settings on both your phone and your computer and manage what data is being synced. Move sensitive business files to a dedicated business storage account with proper access controls, sharing permissions, and audit logs—something that can tell you who opened a file and when.
If anything business-related has to live in a personal cloud account, give that account a strong, unique password, turn on multi-factor authentication, and don’t share access with anyone who isn’t you.
Devices have a funny way of moving around. Your smartphone goes into your spouse’s hands as they override your music choices in the car. Your tablet ends most nights in your kid’s bedroom as they watch TV. And your laptop gets tugged around from couch to counter to kitchen table—each time fully opened and logged in, a portal to the web.
You trust everyone in your home to act safely online, but the path to online safety is full of mistakes.
A single errant click on a fake ad, a malicious search result, or a disguised download is all it takes to compromise your device today, along with all your small business records.
Aside from the threat of malware, someone using your device could make purchases, accidentally delete files, and overwrite important documents.
Remember, an “insider threat” doesn’t need to be malicious to cause damage—they just need to be inside your network (which in this, is your home).
How to stay safe:
Treat your devices that you use for work as work devices. That means requiring a passcode or password for device entry, along with multi-factor authentication for important business accounts.
Also, to ensure that any wrong click doesn’t lead to a malicious PDF download or a wayward malware installation, use always-on antimalware protection software, like Malwarebytes for Teams.
It’s easy to get overwhelmed with modern cybersecurity advice. Every week there are new vulnerabilities to patch, emerging scams to avoid, and novel viruses and pieces of malware that can seemingly take over your device, your data, and your business.
Thankfully, there are important steps you can take today that don’t require you to fiddle with internal settings or take a class on network engineering. Some of the most effective protections are simple: Limit how widely you share sensitive information, keep business and personal data separate, and control who can access your devices.
For everything else, try Malwarebytes for Teams to receive 24/7, always-on antimalware protection to shut out viruses, block malware attacks, and keep hackers out of your business.
WhatsApp is currently developing an independent cloud backup system designed to give users more direct control over their chat histories.
This upcoming feature will allow users to store their backups securely on WhatsApp’s native servers.
The update aims to reduce reliance on third-party cloud services like Google Drive and Apple’s iCloud while enforcing strict cryptographic standards.
As users share more high-resolution media, WhatsApp chat backups frequently consume significant portions of personal cloud storage.
Currently, Android and iOS users must store their backups on their respective default cloud providers.
This setup forces users to share their limited storage space across emails, device backups, and heavy WhatsApp data files.
Once a user reaches their storage limit, they must either delete files or purchase additional space from Google or Apple.
To address this data bottleneck, WhatsApp is building a dual-provider system.

Users will soon have the flexibility to stick with their current third-party service or switch to WhatsApp’s dedicated backup platform.
Key details regarding the new storage ecosystem include:
Security remains the central focus of this independent storage system. If a user selects WhatsApp’s native cloud for backups, end-to-end encryption becomes mandatory for all data stored in the cloud.
This ensures that chat histories remain completely inaccessible to unauthorized parties, threat actors, and even WhatsApp itself.
To make this encryption both highly secure and user-friendly, WhatsApp is integrating device-based authentication.
According to WABetaInfo, users will have three options to secure their backup data:
Passkeys represent a major security upgrade for average users.
Because they are securely stored in a password manager and tied to trusted devices, they eliminate the risk of forgotten passwords while protecting against remote phishing attacks.
The WhatsApp Chat Backup Provider is currently under active development.
Engineers are rigorously testing the feature to ensure it integrates seamlessly with existing security frameworks.
Following internal validation, the feature will gradually roll out to select beta testers before receiving a wider public launch.
This capability marks a significant shift in how the platform handles user data, optimizing backup management while reinforcing mobile security.
Follow us on Google News, LinkedIn, and X for daily cybersecurity updates. Contact us to feature your stories.
The post WhatsApp Testing Own Cloud Backup Provider for Default End-to-End Encryption appeared first on Cyber Security News.

WhatsApp is actively developing an independent, first-party cloud backup service featuring mandatory end-to-end encryption. This upcoming feature aims to reduce users’ reliance on third-party storage providers such as Google Drive and Apple’s iCloud. By bringing backup storage in-house, WhatsApp gives users greater control over their data privacy and device storage limits. All chat histories hosted […]
The post WhatsApp Tests Encrypted Cloud Backup Service for Safer Message Storage appeared first on GBHackers Security | #1 Globally Trusted Cyber Security News Platform.


In a world where digital threats are becoming more confusing, Cyble Research and Intelligence Labs (CRIL) has uncovered one of the most extensive deceptive domain spoofing campaigns to date.
Dubbed Operation TrustTrap, this large-scale operation has leveraged over 16,800 malicious domains to exploit cognitive trust mechanisms and harvest sensitive user data from unsuspecting victims.
The scope and scale of this operation reveal a shift in how cybercriminals are evolving their tactics to bypass traditional technical security measures.
Since early 2026, CRIL has been tracking a well-coordinated infrastructure involving a massive network of spoofed domains. These domains were designed to mimic legitimate government portals, particularly those related to transportation services like Department of Motor Vehicles (DMV) portals, toll payment systems, and vehicle registration services in the United States. The aim of this campaign is clear: credential and payment card harvesting through the exploitation of trusted government-facing services.
However, the technical complexity of the attack isn't based on advanced hacking techniques. Instead, Operation TrustTrap exploits how humans visually interpret URLs. By embedding government-like subdomains, attackers have created fraudulent domains that resemble legitimate government addresses, deceiving individuals into visiting these sites and providing sensitive information.
The spoofed domains were predominantly hosted on Tencent Cloud and Alibaba Cloud APAC, both of which have significant data centers in the Asia-Pacific region. These platforms have been linked to the infrastructure of the campaign, and their concentrated use adds another layer of complexity to the attribution process.
Furthermore, CRIL found that the domains were primarily registered through Gname.com Pte. Ltd., a registrar known for its significant Chinese customer base. Other registrars, such as Dominet (HK) Limited and NameSilo LLC, were also identified in the campaign.
These domain names were often associated with .bond, .cc, and .cfd top-level domains (TLDs), which were frequently used to evade detection and blacklisting.
The most common method used in Operation TrustTrap is subdomain trust injection. This technique involves embedding trusted government tokens, such as mass.gov or wa.gov, in subdomains rather than the root domain. In legitimate URLs, the .gov component typically appears at the end of the domain string, but in these malicious domains, .gov is cleverly placed as part of a subdomain.
For instance, a URL such as mass.gov-bzyc[.]cc will lead a user to believe they are accessing an official Massachusetts government page, but in reality, they are on a fraudulent site designed to capture personal and financial data.
[caption id="" align="alignnone" width="1024"]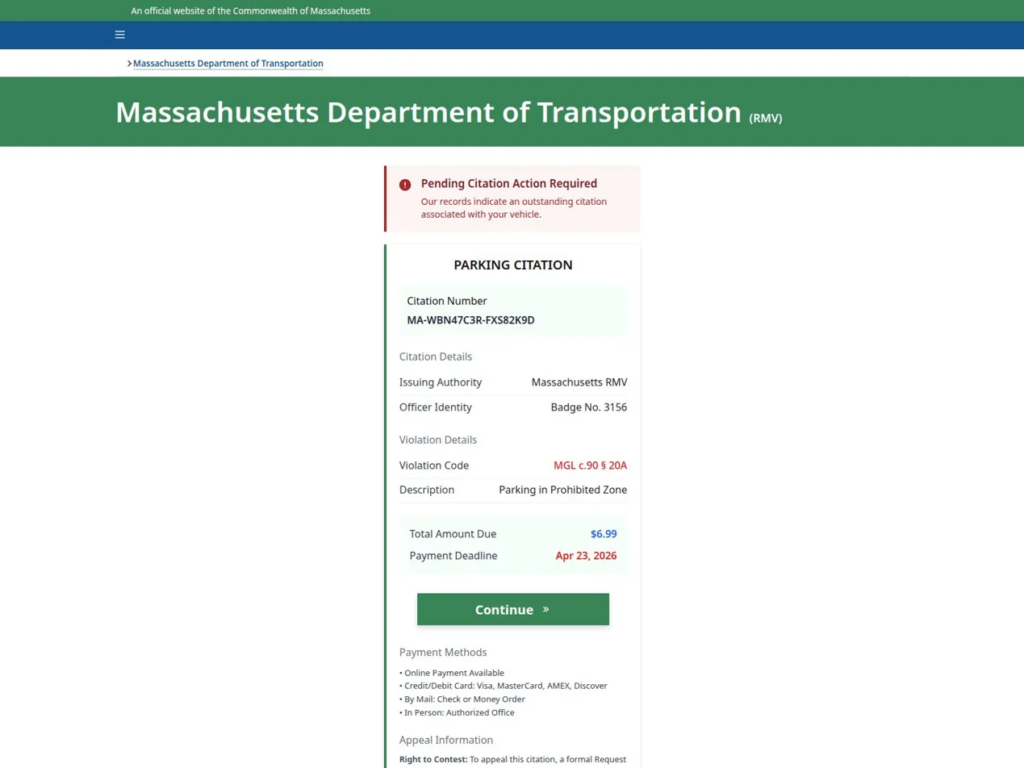 Fake Massachusetts RMV citation landing page (Source: Cyble)[/caption]
Fake Massachusetts RMV citation landing page (Source: Cyble)[/caption]
This manipulation of the domain’s structure is visually convincing, but it bypasses traditional security filters that only check the root domain for trusted indicators like .gov.
Another obfuscation technique used is hyphen-based semantic manipulation, where hyphens are inserted into familiar government identifiers to create visually similar URLs. This tactic further complicates the detection of malicious domains.
While Operation TrustTrap is heavily focused on the United States, targeting state portals such as those in California, Washington, and Florida, the operation is not confined to one region. CRIL identified similar spoofing efforts targeting government portals in India, Vietnam, and the United Kingdom.
In India, attackers have specifically targeted portals that follow the .gov.in domain structure. By injecting subdomains like www.in.gov-bond, the attackers were able to replicate the appearance of legitimate government websites, particularly those related to the Indian Department of National Investigation (NIA) and other defense-adjacent sites.
[caption id="" align="alignnone" width="939"]![APT36 impersonating NIA, India operating at nia[.]gov[.]in[.]in3ymonaq[.]casa](https://cyble.com/wp-content/uploads/2026/04/figure7.png) APT36 impersonating NIA (Source: Cyble)[/caption]
APT36 impersonating NIA (Source: Cyble)[/caption]
This specific targeting suggests that the threat actor has knowledge of government infrastructure and how it operates.
In addition to the use of Tencent Cloud and Alibaba Cloud, the tactics, techniques, and procedures (TTPs) observed in the campaign bear a striking resemblance to those used by APT36 (also known as Transparent Tribe). This Pakistan-based Advanced Persistent Threat (APT) group has a long history of targeting Indian government entities, defense personnel, and diplomatic infrastructure.
The infrastructure used in Operation TrustTrap shows similarities to APT36’s previous campaigns, particularly in terms of the domain registration patterns and use of Tencent Cloud and Alibaba Cloud APAC infrastructure. Furthermore, the behavior observed, including domain rotation and the use of disposable domains, matches previous APT36 activities.
The dominance of Gname.com as the registrar of choice for over 70% of the spoofed domains points to a specific trend in the campaign’s operational setup. This Singapore-based registrar, which serves a large number of Chinese entities, is part of the broader infrastructure strategy that focuses on low-cost hosting in the Asia-Pacific region.
Notably, Tencent Cloud and Alibaba Cloud APAC offer cloud services with global reach, providing the necessary infrastructure to scale this type of malicious operation. These services have been instrumental in supporting the rapid deployment of phishing sites across a variety of government services, especially those involving time-sensitive financial transactions.
In 2026, the question for security leaders is not whether a supply chain attack is coming. Every serious organization should assume it is. The question is whether their defense architecture can stop a payload it has never seen before. It’s a question that takes on even more critical implications at a time where trusted agentic automation increasingly becomes the norm.
In three weeks this spring, three threat actors each ran a tier-1 supply chain attack against widely deployed software: LiteLLM, a core AI infrastructure package, Axios, the most downloaded HTTP client in the JavaScript ecosystem, and CPU-Z, a trusted system diagnostic tool. Different vectors, different actors, different techniques. SentinelOne® stopped all three on the same day each attack launched, with no prior knowledge of any payload.
The more important story is the how. Each attack arrived as a zero-day at the moment of execution. Each exploited a trusted delivery channel: an AI coding agent running with unrestricted permissions, a phantom dependency staged eighteen hours before detonation, a properly signed binary from an official vendor domain. No signature existed for any of them. No IOA matched.
SentinelOne stopped all three. That outcome is a direct answer to the question every security leader is now running against: What does your defense do when the attack arrives through a channel you explicitly trust, carrying a payload you have never seen before?
Adversaries are no longer running manual campaigns at human speed. In September 2025, Anthropic disclosed a Chinese state-sponsored group that jailbroke an AI coding assistant and ran a full espionage campaign against approximately 30 organizations. The AI handled 80–90% of tactical operations autonomously (i.e., reconnaissance, vulnerability discovery, exploit development, credential harvesting, lateral movement, exfiltration) with minimal human direction. Anthropic noted only 4–6 human decision points per campaign. The attack achieved limited success across those targets, but the trajectory is clear: AI is compressing the human bottleneck in offensive operations. Security programs designed around manual-speed adversaries are calibrating to a threat that is moving faster.
The LiteLLM attack is the clearest recent example of what this looks like inside an AI development workflow. On March 24, 2026, threat actor TeamPCP compromised the LiteLLM Python package by obtaining PyPI credentials through a prior supply chain compromise of Trivy, a widely-used open-source security scanner. Two malicious versions (1.82.7 and 1.82.8) were published. Any system with those versions during the exposure window executed the embedded credential theft payload automatically. In one confirmed detection, an AI coding agent running with unrestricted permissions (claude --dangerously-skip-permissions) auto-updated to the infected version without human review — no approval, no alert, no visible action before the payload ran. SentinelOne detected and blocked the malicious Python execution on the same day across multiple environments. Most organizations running AI development workflows didn’t know they were exposed until after the fact. The gap where human review processes don’t reach is wide, and it grows with every AI agent added to a pipeline.
Security programs were built for a different adversary. Vulnerability management, triage queues, patch cadences: all of it assumes an attacker who moves at a pace where human response can still close the window. This year’s SentinelOne Annual Threat Report documented what happens when that assumption breaks: adversaries are shifting left, embedding malicious logic in the build process before software ever reaches production. Likewise, the Verizon 2025 Data Breach Investigations Report found that edge device vulnerabilities are now being mass-exploited at or before the day of CVE publication, while organizations take a median of 32 days to patch them. The old model worked when it was designed. Attackers just weren’t running AI yet.
Each attack ran through the same gap. Authorization was treated as a sufficient security boundary, and when authorization is automated, that assumption has no floor.
An AI agent with install permissions doesn’t stop to ask whether a package looks right. It installs. Trusted source, valid credentials, done. Supply chain attacks have always exploited trusted delivery channels, but a human at the keyboard introduces at least one friction point: Someone might notice something off, slow down, ask a question. Agents don’t do that. They execute at the speed of the next API call. When you give an agent install permissions, you’ve extended your trust model to cover everything it will ever run. Authorized agents execute exactly what their permissions allow. That’s the design. Treating permission as a proxy for safety is what turns a compromised supply chain hypersonic.
LiteLLM was compromised via credentials stolen through Trivy, a security scanner. The Axios attacker bypassed every npm security control the project had in place by exploiting a legacy access token the maintainers had forgotten to revoke. The CPUID attackers went after the vendor’s distribution infrastructure directly, so anyone who downloaded from the official website got a properly signed binary with a payload inside. In all three cases, the identity was legitimate. The intent wasn’t.
SentinelOne’s Annual Threat Report named the failure precisely: “The identity is verified, but the intent has been subverted, rendering traditional access controls ineffective against the resulting supply chain contamination.” Signature libraries, IOA rule sets, reputation lookups: All of them check authorization. None check intent. These attacks were designed to exploit exactly that. When the authorization model runs automatically, so does the exposure.
In each incident, SentinelOne’s on-device behavioral AI flagged the execution pattern, not a known signature or hash for that specific attack.
The LiteLLM detection flagged a Python interpreter executing Base64-decoded code in a spawned subprocess. SentinelOne killed the process preemptively, terminating 424 related events in under 44 seconds, before any human was in a position to observe it. The Axios detection, via the Lunar behavioral engine, caught PowerShell executing under a renamed binary from a non-standard path. The engine flagged the technique regardless of what the payload contained. The first infection occurred 89 seconds after the malicious package went live; the behavioral detection fired on the same day of publication. The CPU-Z detection flagged cpuz_x64.exe building an anomalous process chain: spawning PowerShell, which spawned csc.exe, which spawned cvtres.exe. CPU-Z does not do that. The platform terminated the execution chain mid-attack during a 19-hour active distribution window.
This is the operational output of Autonomous Security Intelligence (ASI), the intelligence fabric built into the Singularity Platform. ASI runs on-device at the edge as part of the core architecture. It is already running when the attack starts, killing the process before the threat can escalate.
Platform. ASI runs on-device at the edge as part of the core architecture. It is already running when the attack starts, killing the process before the threat can escalate.
Where customers had SentinelOne fully deployed with the right policies enabled, they were covered. Where they did not, they were exposed, and with average ransomware recovery costs exceeding $4M per incident, that exposure has a real price. If you are not certain your deployment matches the configuration that stopped these three attacks, that certainty is worth getting.
This is the product reality behind the thesis SentinelOne brought to RSAC: AI to fight AI. A machine-speed adversary requires a machine-speed defense. That is an architectural requirement, not a positioning statement. ASI monitors behavioral patterns at the point of execution and kills the process when something deviates, at machine speed, without waiting for a human to write a query or approve a kill.
According to an IDC study, organizations using SentinelOne’s AI platform identify threats 63% faster and remediate 55% faster than legacy solutions, neutralizing 99% of threats without a single manual step. For organizations in regulated industries (healthcare, financial services, manufacturing, critical infrastructure), the stakes compound beyond breach cost. An exposure window that stays open through manual investigation is a potential regulatory notification event, an audit finding, and a conversation the CISO has with the board under circumstances no one wants. The difference between a stopped attack and an active breach is whether the architecture acts before the attacker establishes persistence. By the time a human analyst approves the kill, redundant persistence mechanisms may already be installed. The CPU-Z attack deployed three of them specifically because partial cleanup leaves the payload operational.
Human-driven workflows, manual validation, and legacy tooling cannot keep pace with that attack cadence. When defense relies on investigation before action, the advantage shifts to the adversary. The gap is in the architecture. You cannot tune your way out of it.
SentinelOne’s latest Annual Threat Report documented the pattern these three attacks confirm: Adversaries are “shifting left” by integrating malicious logic into the build process itself, compromising software before it reaches production. It is the current operating model of advanced threat actors, and it is accelerating.
Three attacks. Three detections. Three outcomes, all in a matter of weeks. The architecture that survived them is real-time, AI-native, and built into the edge.
The question every security leader should be able to answer: Could your current solution have stopped LiteLLM, Axios, and CPU-Z autonomously, on the day of each attack, with no prior knowledge of any payload?
If the answer depends on a signature update, a cloud verdict, a manual investigation step, or a policy that wasn’t enabled, that is your answer.
Read the full technical breakdown of each incident:
Third-Party Trademark Disclaimer:
All third-party product names, logos, and brands mentioned in this publication are the property of their respective owners and are for identification purposes only. Use of these names, logos, and brands does not imply affiliation, endorsement, sponsorship, or association with the third-party.

Unit 42 reveals how multi-agent AI systems can autonomously attack cloud environments. Learn critical insights and vital lessons for proactive security.
The post Can AI Attack the Cloud? Lessons From Building an Autonomous Cloud Offensive Multi-Agent System appeared first on Unit 42.

Unit 42は、マルチエージェントAIシステムがクラウド環境をどのように自律的に攻撃できるかを明らかにします。プロアクティブなセキュリティのための重要なインサイトと不可欠な教訓を学びます。
The post AIはクラウドを攻撃できるのか?自律型クラウド攻撃型マルチエージェント システムの構築から得られた教訓 appeared first on Unit 42.
Amtrak data breach exposes over 2.1 million customer records after CRM access. Learn what was leaked, risks, and steps users and IT teams should take now.
The post Amtrak Data Breach Exposes 2.1M Records, Reports Suggest Larger Leak appeared first on TechRepublic.