Principais riscos do OpenClaw, Clawdbot, Moltbot | Blog oficial da Kaspersky
É provável que todos já tenham ouvido falar do OpenClaw, anteriormente conhecido como “Clawdbot” ou “Moltbot”, o assistente de IA de código aberto que pode ser implementado localmente em uma máquina. Ele se conecta a plataformas de bate-papo populares como WhatsApp, Telegram, Signal, Discord e Slack, o que permite aceitar comandos do proprietário e acessar todo o sistema de arquivos local. Ele tem acesso ao calendário, e-mail e navegador do proprietário, podendo até mesmo executar comandos do SO por meio do shell.
Do ponto de vista da segurança, essa descrição por si só já é suficiente para deixar qualquer pessoa com os cabelos em pé. Mas quando as pessoas tentam usar o assistente em um ambiente corporativo, a ansiedade rapidamente se transforma na certeza de um caos iminente. Alguns especialistas já consideram o OpenClaw como a maior ameaça interna de 2026. Os problemas com o OpenClaw cobrem todo o espectro dos riscos destacados na recente lista OWASP Top 10 for Agentic Applications.
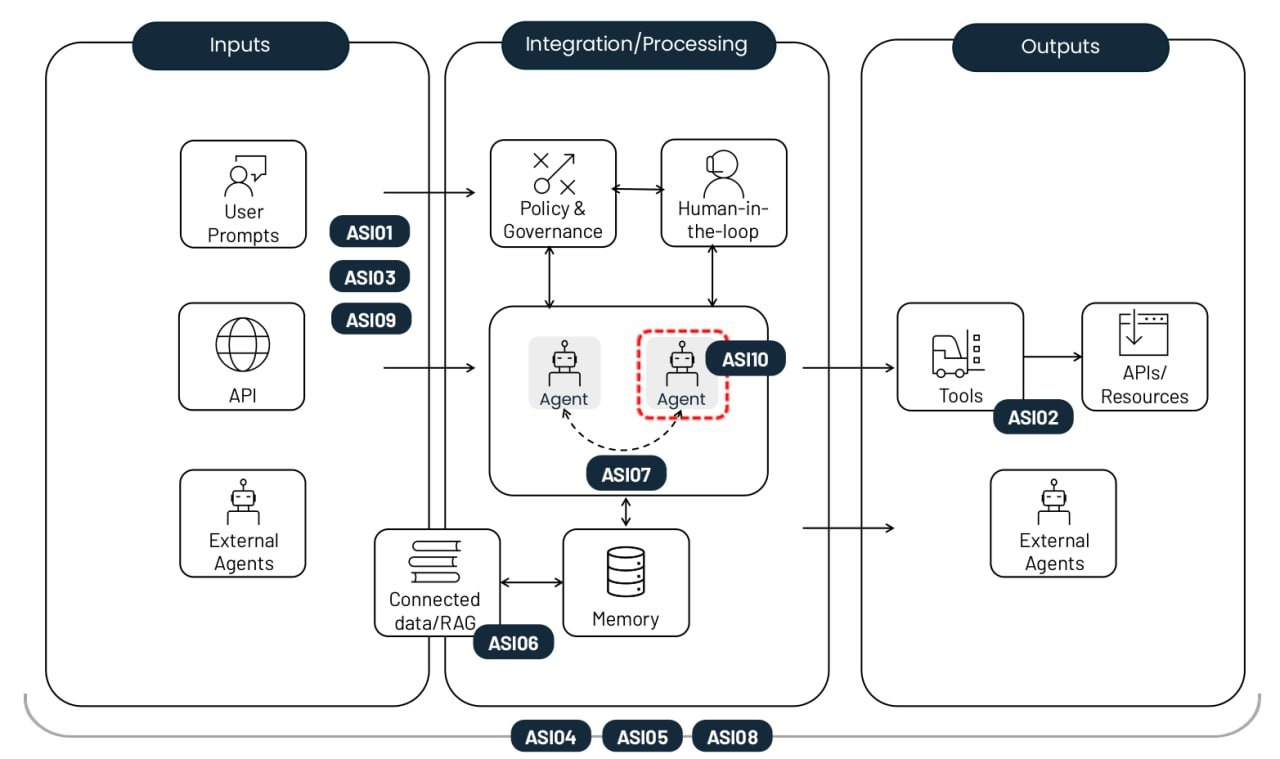
O OpenClaw permite conectar qualquer LLM local ou baseada em nuvem e usar várias integrações com serviços adicionais. No seu núcleo, há um gateway que aceita comandos por aplicativos de bate-papo ou por uma interface web e os encaminha para os agentes de IA adequados. A iteração inicial (Clawdbot), de novembro de 2025, apresentou gargalos de segurança significativos após sua popularização viral em janeiro de 2026. Em uma única semana, várias vulnerabilidades críticas foram divulgadas, surgiram habilidades maliciosas no diretório e vazaram segredos do Moltbook (basicamente um “Reddit para bots”). Para completar, a Anthropic exigiu que o projeto mudasse de nome para evitar violação da marca “Claude”, e o nome da conta no X foi sequestrado para promover golpes de criptomoedas.
Problemas conhecidos do OpenClaw
Embora o desenvolvedor do projeto pareça reconhecer a importância da segurança, como este é um projeto de hobby, não há recursos dedicados ao gerenciamento de vulnerabilidades nem a outros elementos essenciais de segurança do produto.
Vulnerabilidades do OpenClaw
Entre as vulnerabilidades conhecidas no OpenClaw, a mais perigosa é a CVE-2026-25253 (CVSS 8.8). Ela leva a um comprometimento total do gateway, permitindo que um invasor execute comandos arbitrários. Para piorar a situação, é assustadoramente fácil de explorá-la: se o agente visitar o site de um invasor ou se o usuário clicar em um link malicioso, o token de autenticação principal será vazado. Com esse token em mãos, o invasor tem controle administrativo total sobre o gateway. Essa vulnerabilidade foi corrigida na versão 2026.1.29.
Além disso, duas vulnerabilidades perigosas de injeção de comando (CVE-2026-24763 e CVE-2026-25157) foram descobertas.
Padrões e recursos inseguros
Uma série de configurações padrão e peculiaridades de implementação tornam o ataque ao gateway muito fácil:
- A autenticação é desativada por padrão, portanto, o gateway pode ser acessado pela Internet.
- O servidor aceita conexões WebSocket sem verificar a origem.
- A confiança das conexões localhost é implícita, o que é um desastre prestes a acontecer caso o host esteja executando um proxy reverso.
- Várias ferramentas, inclusive algumas perigosas, estão acessíveis no Modo Visitante.
- Os parâmetros de configuração críticos vazam pela rede local por meio de mensagens de difusão mDNS.
Segredos em texto simples
A configuração, a “memória” e os registros de bate-papo do OpenClaw armazenam chaves de API, senhas e outras credenciais para LLMs e serviços de integração em texto simples. Esta é uma ameaça crítica, pois versões dos malwares de roubo de informações RedLine e Lumma já foram identificadas com caminhos de arquivo do OpenClaw adicionados às suas listas de itens a roubar. Além disso, o malware de roubo de informações Vidar foi pego roubando segredos do OpenClaw.
Habilidades maliciosas
A funcionalidade do OpenClaw pode ser expandida com “habilidades” disponíveis no repositório do ClawHub. Como qualquer pessoa pode carregar uma habilidade, não demorou para que agentes de ameaças começassem a embutir o malware de roubo de informações AMOS macOS em seus envios. Em pouco tempo, o número de habilidades maliciosas chegou à casa das centenas. Isso levou os desenvolvedores a assinar rapidamente um acordo com o VirusTotal para garantir que todas as habilidades enviadas sejam verificadas em bancos de dados de malware e também passem por análise de código e conteúdo via LLMs. Dito isto, os autores são muito claros: não é uma solução milagrosa.
Falhas estruturais no agente de IA OpenClaw
As vulnerabilidades podem ser corrigidas e as configurações podem ser reforçadas, mas alguns dos problemas do OpenClaw são intrínsecos ao seu design. O produto combina vários recursos críticos que, quando agrupados, são muito perigosos:
- O OpenClaw tem acesso privilegiado a dados confidenciais na máquina host e às contas pessoais do proprietário.
- O assistente está totalmente receptivo a dados não confiáveis: ele recebe mensagens por meio de aplicativos de bate-papo e e-mail, acessa páginas da Web de forma autônoma etc.
- Ele sofre com a incapacidade inerente dos LLMs de separar comandos de dados de forma confiável, tornando possível a injeção de prompt.
- O agente salva as principais conclusões e artefatos das suas tarefas para guiar ações futuras. Isso significa que uma única injeção bem-sucedida pode envenenar a memória do agente, influenciando seu comportamento a longo prazo.
- O OpenClaw pode se comunicar com o mundo exterior, enviando e-mails, fazendo chamadas de API e usando outros métodos para exfiltrar dados internos.
Vale notar que, embora o OpenClaw seja um exemplo particularmente extremo, essa lista de “Cinco fatores aterrorizantes” é característica de quase todos os agentes de IA multifuncionais.
Riscos do OpenClaw para as organizações
Se um funcionário instalar um agente como esse em um dispositivo corporativo e conectá-lo a um conjunto básico de serviços (como Slack e SharePoint), a combinação de execução autônoma de comandos, amplo acesso ao sistema de arquivos e permissões OAuth excessivas cria um terreno fértil para o comprometimento profundo da rede. Na verdade, o hábito do bot de acumular segredos e tokens não criptografados em um só lugar é um desastre prestes a acontecer, ainda que o próprio agente de IA nunca seja comprometido.
Além disso, essas configurações violam os requisitos regulamentares em vários países e setores, ocasionando possíveis multas e falhas de auditoria. Os requisitos regulatórios atuais, como os da Lei de IA da UE ou da Estrutura de gerenciamento de risco de IA do NIST, exigem explicitamente controle de acesso rigoroso para agentes de IA. A abordagem de configuração do OpenClaw claramente deixa a desejar nesse quesito.
Mas o verdadeiro problema é que, mesmo que os funcionários sejam proibidos de instalar esse software em máquinas de trabalho, o OpenClaw pode ir parar nos seus dispositivos pessoais. Isso também cria riscos específicos para toda a organização:
- Os dispositivos de uso pessoal costumam armazenar acessos do trabalho, como chaves de VPN e tokens de navegador para ferramentas e e-mails da empresa. Eles podem ser sequestrados para obter acesso inicial à infraestrutura da empresa.
- Controlar o agente por aplicativos de bate-papo significa que não só os funcionários se tornam alvos de engenharia social, mas também seus agentes de IA, tornando reais invasões de contas de IA ou personificação do usuário em bate-papos com colegas (entre outros golpes). Mesmo que o trabalho seja discutido apenas ocasionalmente em bate-papos pessoais, as informações ali estão prontas para serem exploradas.
- Se um agente de IA em um dispositivo pessoal estiver conectado a qualquer serviço corporativo (e-mail, mensagens, armazenamento de arquivos), os invasores podem manipular o agente para desviar dados, e essa atividade seria extremamente difícil de ser detectada pelos sistemas de monitoramento corporativos.
Como detectar o OpenClaw
Dependendo dos recursos de monitoramento e resposta da equipe do SOC, eles podem rastrear tentativas de conexão do gateway do OpenClaw em dispositivos pessoais ou na nuvem. Além disso, uma combinação específica de sinais de alerta pode indicar a presença do OpenClaw em um dispositivo corporativo:
- Procure os diretórios ~/.openclaw/, ~/clawd/ ou ~/.clawdbot nas máquinas host.
- Verifique a rede com ferramentas internas ou públicas, como o Shodan, para identificar as impressões digitais HTML dos painéis de controle do Clawdbot.
- Monitore o tráfego de WebSocket nas portas 3000 e 18789.
- Fique atento às mensagens de difusão de mDNS na porta 5353 (especificamente openclaw-gw.tcp).
- Preste atenção a tentativas de autenticação incomuns em serviços corporativos, como novos registros de ID de aplicativo, eventos de consentimento OAuth ou strings de User-Agent típicas do Node.js e de outros agentes do usuário não padrão.
- Procure padrões de acesso típicos de coleta automatizada de dados: leitura de grandes volumes (por exemplo, raspar todos os arquivos ou e-mails) ou varredura de diretórios em intervalos fixos fora do horário do expediente.
Controlando o comportamento da Shadow AI
Um conjunto de práticas de higiene de segurança pode reduzir muito a pegada de Shadow IT e Shadow AI, tornando muito mais difícil implementar o OpenClaw em uma organização:
- Use a lista de permissões em nível de host para garantir que apenas aplicativos aprovados e integrações na nuvem sejam instalados. Implemente uma lista fechada de complementos verificados para produtos que oferecem extensibilidade (como extensões do Chrome, plugins do VS Code ou habilidades do OpenClaw).
- Faça uma avaliação de segurança completa de todos os produtos ou serviços, inclusive dos agentes de IA, antes de permitir que eles se conectem aos recursos corporativos.
- Aplique aos agentes de IA os mesmos requisitos de segurança rigorosos aplicados aos servidores de uso público que processam dados corporativos confidenciais.
- Implemente o princípio de privilégio mínimo para todos os usuários e outras identidades.
- Não conceda privilégios administrativos sem que haja uma necessidade comercial crítica. Exija que todos os usuários com permissões elevadas as usem apenas ao executar tarefas específicas, em vez de trabalhar com contas privilegiadas o tempo todo.
- Configure os serviços corporativos para que as integrações técnicas (como aplicativos que solicitam acesso pelo OAuth) recebam apenas as permissões mínimas.
- Faça auditorias periódicas de integrações, tokens OAuth e permissões concedidas a aplicativos de terceiros. Analise a necessidade disso com os proprietários de empresas, revogue proativamente permissões excessivas e elimine integrações obsoletas.
Implementação segura de agentes de IA
Se uma organização permitir agentes de IA de forma experimental (por exemplo, em testes de desenvolvimento ou pilotos de eficiência) ou liberar casos de uso específicos para a equipe, então medidas robustas de monitoramento, logs e controle de acesso devem ser implementadas:
- Implemente os agentes em uma sub-rede isolada com regras estritas de entrada e saída, limitando a comunicação apenas aos hosts confiáveis necessários para a tarefa.
- Use tokens de acesso de curta duração com um escopo de privilégios muito limitado. Nunca entregue a um agente tokens que concedam acesso aos servidores ou serviços principais da empresa. O ideal é criar contas de serviço exclusivas para cada teste individual.
- Mantenha as ferramentas perigosas e os conjuntos de dados que não são relevantes para o trabalho específico. Para implementações experimentais, a prática recomendada é testar o agente usando dados puramente sintéticos que imitam a estrutura de dados de produção reais.
- Configure o registro detalhado das ações do agente. Isso deve incluir registros de eventos, parâmetros de linha de comando e artefatos da cadeia de raciocínio associados a cada comando executado.
- Configure o SIEM para sinalizar atividades anormais do agente. As mesmas técnicas e regras usadas para detectar ataques LotL são aplicáveis aqui, embora sejam necessários esforços adicionais para definir quais são as atividades normais de um agente específico.
- Se servidores MCP e habilidades de agente adicionais forem usados, verifique-os com as ferramentas de segurança emergentes para essas tarefas, como o skill-scanner, mcp-scanner ou o mcp-scan. Várias empresas já lançaram ferramentas de código aberto para auditar a segurança das configurações durante testes do OpenClaw.
Políticas corporativas e treinamento de funcionários
A proibição total de todas as ferramentas de IA é um caminho simples, mas que quase nunca é produtivo. Os funcionários geralmente encontram soluções alternativas, empurrando o problema para as sombras e dificultando ainda mais o seu controle. Em vez disso, é melhor encontrar um equilíbrio sensato entre produtividade e segurança.
Implemente políticas transparentes para o uso de agentes de IA. Defina quais categorias de dados podem ser processadas por serviços externos de IA e quais estão estritamente proibidas. Os funcionários precisam entender por que algo é proibido. Uma política de “sim, mas com ressalvas” é sempre melhor recebida do que um “não” geral.
Use exemplos do mundo real nos treinamentos. Avisos abstratos sobre “riscos de vazamento” tendem a não ser levados a sério. É melhor demonstrar como um agente com acesso ao e-mail consegue encaminhar mensagens confidenciais só porque um e-mail de entrada aleatório solicitou. Quando a ameaça parece real, a motivação para seguir as regras também cresce. O ideal é que os funcionários façam um curso rápido sobre segurança de IA.
Ofereça alternativas seguras. Se os funcionários precisarem de um assistente de IA, forneça uma ferramenta aprovada com gerenciamento centralizado, logs e controle de acesso OAuth.